
Paralelni genetski algoritmi moćni su alati za rješavanje problema optimiranja. U ovom radu prezentirano je nekoliko modela paralelnih genetskih algoritama. Svaki od tih paralelnih genetskih algoritama ima svoje prednosti i nedostatke. U sklopu rada ostvarena je i praktična implementacija tih genetskih algoritama na višestrukom grafičkom procesoru. Višestruki grafički procesori su učinkovito sredstvo za paralelizaciju algoritama koji rade sa sitnozrnatim (fine-grained) podacima.
evolucijsko računanje, genetski algoritmi, višestruki grafički procesor, CUDA (jedinstvena arhitektura za paralelno računanje na višestrukim grafičkim procesorima), masivno paralelno računanje
Parallel genetic algorithms are powerful tools for solving optimization problems. In this text, several models of parallel genetic algorithms are presented. Each of these PGA has its advantages and flaws. A practical implementation of those genetic algorithms on a multicore graphical processing unit was made as a part of this work. Multicore graphical processing units are efficient means of parallelization of algorithms which work with fine-grained data.
Evolutionary Computing, Genetic Algorithms, Multicore Graphical Processing Unit, CUDA (Compute Unified Device Architecture), Massive Parallel Computing
Genetski algoritam je jedna od vremenski najzahtjevnijih metoda optimiranja. Paralelizacijom genetskog algoritma skraćuje se vrijeme izvođenja. Višestruki grafički procesori su jeftina i učinkovita sredstva za paralelizaciju algoritama. U ovom diplomskom radu ispituje se mogućnost implementacije genetskih algoritama na grafičkoj jedinici.
Rad je nastao kao logičan nastavak istraživanja paralelnog evolucijskog računanja na diplomskom studiju. Istraživanje obuhvaća pregledni rad „Paralelni genetski algoritmi“ izrađen u sklopu predmeta Seminar u drugom semestru, te praktični rad „Trivijalni paralelni genetski algoritam na višestrukom grafičkom procesoru“, izrađen u sklopu predmeta Projekt, u trećem semestru diplomskog studija.
U prvom dijelu rada pruža se kratki pregled genetskog algoritma. Nakon toga donosi se pregled paralelnih genetskih algoritama koji su implementirani u praktičnom dijelu diplomskog rada. Treći dio donosi kratak pregled arhitekture višestrukog grafičkog procesora. U zadnjem dijelu prezentiran je praktični dio implementiran na višestrukom grafičkom procesoru u CUDA tehnologiji: masovno paralelni GA, globalni paralelni GA i distribuirani GA.
Genetski algoritam je heuristički optimizacijski algoritam koji oponaša prirodni evolucijski proces. Po načinu djelovanja ubraja se u metode usmjerenog pretraživanja prostora rješenja (guided random search techniques) u traženju globalnog optimuma. Koncept genetskih algoritama predložio je dr. John Henry Holland početkom sedamdesetih godina dvadesetog stoljeća. Danas su genetski algoritmi vrlo moćno i praktično oruđe za rješavanje čitavog niza optimizacijskih problema upravo zbog jednostavnosti ideje na kojoj su zasnovani, te jednostavnosti njihove primjene. Unatoč sve većoj primjeni i opsegu istraživanja na području genetskih algoritama, rezultati dobiveni na teorijskom području ostaju dvojbeni, a genetski algoritmi još su uvijek u osnovi heurističke metode.
Populacija bilo koje vrste živih bića sastoji se od jedinki. Svaka se jedinka može okarakterizirati nekim svojstvima i sposobnostima, a ona određuju koliko će ta jedinka biti uspješna u borbi za preživljavanje u trenutnim uvjetima. Svojstva jedinke zapisana su u kromosomima. Jedno svojstvo zapisano je na jednom malom djeliću kromosoma koji se naziva gen. Kako bi se pohranila sva svojstva, potrebno je više kromosoma. Jedna dugačka neprekinuta nit deoksiribonukleinske kiseline (DNK) čini devedeset i osam posto kromosoma. DNK se sastoji od dvije spiralne niti građene od fosforne kiseline i šećera, međusobno povezane parovima dušičnih baza, adeninom i timinom odnosno citozinom i gvaninom. Upravo te dušične baze, nositelji su informacija.
Slika 2-1 - Građa i struktura DNA
Jedinka genetskog algoritma predstavlja jedno potencijalno rješenje problema koji nastojimo riješiti. Svojstva jedinke mogu biti zapisana korištenjem bilo kojeg oblika ili strukture podataka. Uzmimo za primjer problem traženja minimuma funkcije u skupu realnih brojeva: svojstva jedne jedinke mogu se prikazati klasom Point, skupom varijabli s pomičnom točkom, nizom bitova u kojem prva polovica bitova predstavlja x, a druga polovica y varijablu.
| class Jedinka { Point data; } |
class Jedinka { float xData; float yData; } |
class Jedinka { byte[8] data; } |
Pseudokod 2-1 - Različite organizacije podataka jedinke
Na temelju svojstava jedinke, može se odrediti koliko je ona dobro rješenje u odnosu na ostale. Broj kojim se iskazuje kvaliteta jedinke naziva se dobrota. Evaluacija je postupak kojim se iz svojstava jedinke izračunava njena dobrota. Osim dobrote jedinke možemo računati i kaznu jedinke. Kazna jedinke nam govori koliko je jedinka loša u odnosu na druge. Kazna se izračunava oduzimanjem dobrote jedinke od dobrote najbolje jedinke u populaciji.
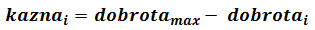 | (2-1) |
Cilj funkcije evaluacije jest razlučiti dobra rješenja od loših. Upravo zato je važno napisati dobru funkciju evaluacije, kako se neka potencijalno dobra svojstva ne bi izgubila, ili neka loša nepotrebno propagirala u sljedeće generacije. Još jedno poželjno svojstvo funkcije evaluacije je neuniformnost rezultata. Naime, ukoliko nam funkcija evaluacije daje uniformne dobrote za veći dio jedinki, teško ćemo razlučiti bolje jedinke od lošijih.
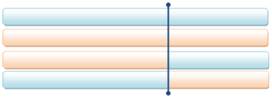
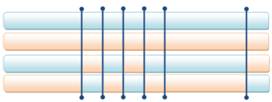
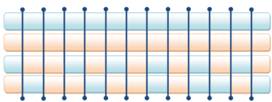
Selekcija je proces kojim genetski algoritam čuva dobre, a odbacuje loše jedinke iz populacije rješenja. Selekcijom se odabiru jedinke koje će sudjelovati u reprodukciji, te tako prenijeti svoj genetski materijal na sljedeću generaciju. Kako i loše jedinke mogu sadržavati dobre i korisne gene, potrebno je i njima omogućiti barem minimalnu vjerojatnost razmnožavanja. Bolje jedinke, naravno, trebaju imati veću vjerojatnost razmnožavanja. Slika 2-2 prikazuje tipove i vrste selekcija.
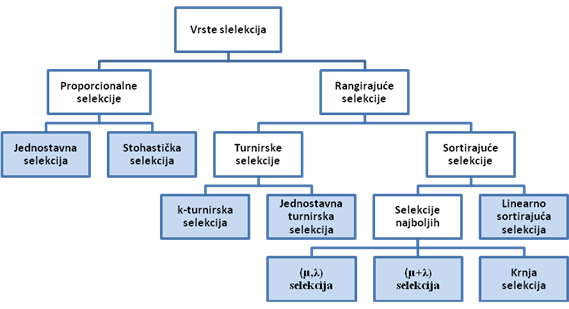
Slika 2-2 - Vrste selekcija
U proporcionalnim selekcijama vjerojatnost izbora jedinke proporcionalna je njenoj dobroti. Svakoj jedinci određuje se vjerojatnost preživljavanja (ili eliminacije) u odnosu na ostale jedinke. Vjerojatnost preživljavanja jednaka je odnosu dobrote jedinke i ukupnog zbroja dobrota cijele populacije.
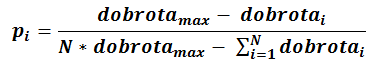 | (2-2) |
Gotovo sva teorijska istraživanja temelje se na proporcionalnim selekcijama, te je njihova upotreba najraširenija. Dostupnost veće količine podataka o ovom postupku selekcije omogućava lakšu analizu rada genetskog algoritma.
Proporcionalne selekcije troše znatno više procesorskog vremena od rangirajućih selekcija. Postupak selekcije teško je paralelizirati s obzirom da se u svakoj iteraciji mora obaviti sinkronizacija procesa radi izračuna ukupne dobrote cijele populacije. Funkcija izračuna dobrote ne smije davati negativne vrijednosti, a dobrote jedinki ne bi smjele biti približno jednakih vrijednosti. Ukoliko je dobrota negativna, tada je i vjerojatnost izbora te jedinke negativna. Ukoliko jedinke imaju približno jednake vrijednosti dobrote, tada se genetski algoritam pretvara u postupak slučajnog pretraživanja, jer sve jedinke imaju približno istu vjerojatnost selekcije.
Kod rangirajućih selekcija vjerojatnost selekcije ne ovisi izravno o dobroti, već o položaju jedinke u poretku jedinki sortiranih po dobroti. Sortirajuće selekcije obavljaju sortiranje jedinki prema njihovoj dobroti. Postupak sortiranja procesorski je veoma zahtjevan, zbog čega se sortirajuće selekcije rijetko koriste. Postupak sortiranja ne isplati se paralelizirati za veličine populacija kakve se najčešće koriste u primjeni (od 30 do 100 jedinki). Stoga rangirajuće selekcije nisu pogodne za paralelno izvođenje. Postupak sortiranja značajno usporava proces selekcije i ako je ikako moguće, treba ga izbjeći kao i postupak sinkronizacije.
Za razliku od sortirajućih selekcija koje sortiraju cijelu populaciju jedinki, turnirske selekcije uspoređuju dobrotu samo nekoliko slučajno izabranih jedinki. U generacijskom algoritmu najbolja od izabranih jedinki prelazi u novu generaciju, dok se u eliminacijskom algoritmu najlošija od izabranih jedinki eliminira iz populacije. Prema broju slučajno izabranih jedinki turnirske selekcije se dijele na 2-turnirske, 3-turnirske, 4-turnirske itd.
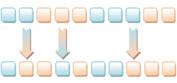
Križanje je genetski operator koji imitira prirodni proces križanja (crossover). U njemu sudjeluju dvije jedinke iz populacije, te se križanjem njihovog genetskog materijala dobiva jedna ili dvije nove jedinke. Novonastala jedinka nastaje iz dvije dobre jedinke, koje su prošle selekciju, te bi njihova svojstva trebala biti dobra. Prema tome, nova jedinka također bi trebala biti dobra. Križanje se može izvesti na nekoliko načina. Postupkom križanja brzo se postiže konvergencija optimumu, ali postoji opasnost da on bude lokalni. Najjednostavniji način je križanje s jednom točkom prekida kada se kromosom lomi u jednoj točki te spaja s dijelom drugog slomljenog na istom mjestu.

Slika 2-3 - Križanje s jednom točkom prekida
Križanje sa više točaka prekida obavlja se na sličan način. Jedina razlika je u tome što se kromosomi lome u više točaka, a zatim se dijelovi roditelja A i B naizmjence spajaju. Krajnji slučaj ovog načina križanja je uniformno križanje, tj. križanje s b-1 prekidnih točaka na kromosomu sa b bitova. Kod uniformnog križanja, dijelovi kromosoma ne spajaju se naizmjence, već se za svaki gen računa je li naslijeđen od prve ili druge jedinke koja sudjeluje u križanju. Vjerojatnost nasljeđivanja gena od svakog roditelja je jednaka (p=0.5). P-uniformno križanje je poseban oblik uniformnog križanja u kojem je vjerojatnost nasljeđivanja pojedinog gena od jednog roditelja drugačija od vjerojatnosti nasljeđivanja od drugog. Vrijednost parametra pi određuje koliko je vjerojatno da će nova jedinka i-ti gen naslijediti od prvog, odnosno drugog roditelja. Ukoliko vrijedi p = 0, gen se uvijek nasljeđuje od prvog roditelja, a ako je p = 1, onda od drugog. Vrijednost parametra pi = 0.3 govori da će u tri od deset križanja i-ti gen biti od prvog roditelja, dok će u ostalih sedam biti od drugog.

Slika 2-4 - Križanje s više točaka prekida

Slika 2-5 - Uniformno križanje
Mutacija je unarni operator koji mijenja neki dio gena jedinke u neku nasumično odabranu vrijednost. Mutacija može promijeniti jedno ili više svojstava jedinke. Genetski operator mutacije može promijeniti jednu ili više jedinki koje će usmjeriti GA prema još neistraženim područjima rješenja što može dovesti do otkrivanja globalnog optimuma.
Slika 2-6 - Primjer mutacije na tri gena neke jedinke
Mutacija s maskom provodi mutaciju samo nad onim genima kromosoma koji su određeni maskom. Maska može biti uvijek ista, ali se može i generirati prije svake mutacije.
Slika 2-7 - Primjer mutacije s maskom
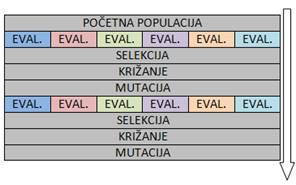
Generacijski genetski algoritam započinje generiranjem početne populacije. Zatim se u petlji sve do postizanja uvjeta završetka GA ponavlja sljedeći proces:
Jedinke u populaciji se evaluiraju, tj. izračunava se njihova dobrota. Na temelju te dobrote obavlja se selekcija jedinki koje će sudjelovati u križanju. Križanjem se stvara broj novih jedinki (djece) jednak brojnosti jedinki u početnoj populaciji. Jedinke nastale križanjem podvrgavaju se mutaciji te tako nastaje nova populacija. U sljedećoj iteraciji petlje, nad novom populacijom ponavlja se isti proces – evaluacija, selekcija, križanje i mutacija. Kada je uvjet završetka GA-a postignut, najbolja jedinka predstavlja najbolje rješenje.
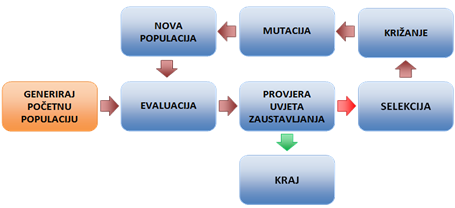
Slika 2-8 - Dijagram tijeka generacijskoga genetskog algoritma
Eliminacijski genetski algoritam radi s jednom populacijom. Model je nešto bliži prirodnom evolucijskom procesu, s obzirom da se u svakoj iteraciji eliminira samo dio jedinki. Jedinke koje će činiti populaciju generiraju se na početku algoritma. Sve jedinke se evaluiraju, te se svakoj jedinci pridjeljuje kazna. Zatim se u petlji sve do postizanja uvjeta završetka GA-a ponavlja sljedeći proces:
Prema kazni, odabire se M jedinki za eliminaciju. Broj jedinki za eliminaciju (M) mora biti manji od broja jedinki u početnoj populaciji (N). Od preostalih jedinki (N - M) križanjem se stvara M novih jedinki koje nadopunjuju populaciju do brojnosti N. Kada je populacija postigla brojnost N, provodi se operator mutacije. Za nove i mutirane jedinke, izračunava se kazna. Kad je uvjet završetka GA-a postignut, jedinka s kaznom jednakom nula predstavlja najbolje rješenje optimizacijskog problema.
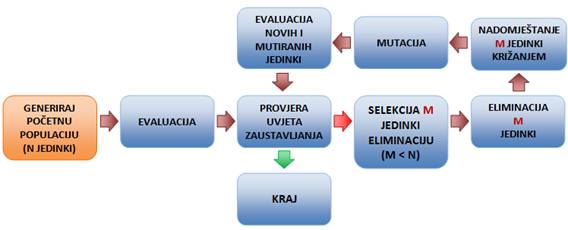
Slika 2-9 - Dijagram tijeka eliminacijskoga genetskog algoritma
Izračunavanjem kazne samo za nove i jedinke koje su mutirale, skraćuje se vrijeme izvođenja GA. Pod pretpostavkom da je evaluacija najskuplji genetski operator, ovakvo izračunavanje dobrote donosi značajne uštede vremena. Uzmemo li da je broj jedinki u populaciji jednak N, broj jedinki za eliminaciju jednak M, a faktor mutacije μ, tada će genetski algoritam u najgorem slučaju izvesti evaluaciju (M + μ*N), umjesto N puta. Ukoliko uzmemo u obzir da je broj mutiranih jedinki često malen u odnosu na broj eliminiranih jedinki, a vrijeme izvođenja ostalih operatora zanemarivo u odnosu na vrijeme potrebno za evaluaciju, tada možemo reći da će se izvođenje GA-a ubrzati N/M puta.
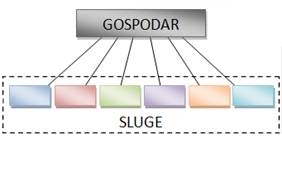
Globalni paralelni genetski algoritam oblik je genetskog algoritma s jednom populacijom. GPGA je višedretveni proces. Jednoj dretvi se dodjeljuje uloga gospodara – ona raspodjeljuje posao slugama (ostale dretve) i po potrebi sinkronizira proces razmjene jedinki.
Tradicionalni_globalni_paralelni_genetski_algoritam()
{
generiraj_početnu_populaciju_jedinki();
dok (nije_zadovoljen_uvjet_završetka_evolucijskog_procesa)
{
// SLUGE:
evaluiraj_paralelno(); // evaluiraj paralelno jedinke
// GOSPODAR:
selektiraj(); // selektiraj jedinku za reprodukciju
križaj(); // obavi reprodukciju nad odabranim jedinkama
mutiraj();
}
}
Pseudokod 3-1 - Globalni paralelni genetski algoritam
U tradicionalnom globalnom paralelnom genetskom algoritmu gospodar obavlja sve genetske operatore osim evaluacije koju provode sluge. Evaluacija se smatra operatorom koji troši najviše procesorskog vremena, dok je utrošak procesorskog vremena na obavljanje ostalih operatora zanemariv u odnosu na utrošak na evaluaciju. Upravo je to razlog paralelizacije procesa koraka evaluacije. Gospodar u svojoj memoriji ima pohranjenu cijelu populaciju, te provodi genetske operatore nad cijelim skupom jedinki. U koraku evaluacije, gospodar šalje slugama segmente populacije, a oni mu vraćaju izračunate vrijednosti funkcija cilja. Ukoliko sluge obavljaju i ostale genetske operatore osim evaluacije – mutaciju, križanje i selekciju, tada se iz naziva izostavlja riječ tradicionalni.
Slika 2-8 - Dijagram tijeka generacijskoga genetskog algoritma
Pri ocjeni ubrzanja GPGA-a moramo uzeti u obzir utrošak vremena na komunikaciju između gazde i slugu. Recimo da ono iznosi Tc vremena. Tada ukupno vrijeme za komunikaciju u svakoj iteraciji iznosi (S+1)Tc. Nadalje, vrijeme trajanja evaluacije jedne jedinke neka iznosi Tf. Neka sve sluge imaju dodijeljen jednak broj jedinki za evaluaciju i neka je vrijeme trajanja evaluacije konstantno. Tada je ukupno trajanje evaluacije skraćeno S+1 puta i iznosi N×Tf/(S+1). Ukupno vrijeme trajanja jedne iteracije, uz pretpostavku da je vrijeme potrebno da se obave genetski operatori zanemarivo u odnosu na vrijeme potrebno za evaluaciju i komunikaciju između gospodara i slugu, iznosi:
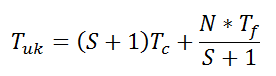 | (3-1) |
Optimalni broj slugu S* se dobiva ako izraz ( 3-1 ) deriviramo i izjednačimo s nulom:
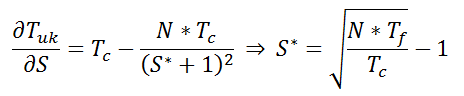 | (3-2) |
GPGA je jednostavan za implementaciju i nema potrebe za uvođenjem dodatnih parametara genetskog algoritma. Veća ubrzanja GPGA-a postižu se što je funkcija evaluacije vremenski zahtjevnija. U tom slučaju se paralelizacijom postižu veće uštede nego u slučajevima kada je trajanje evaluacije zanemarivo u odnosu na trajanje ostalih operatora.
Masovno paralelni genetski algoritam (ili stanični genetski algoritam) je oblik paralelnog genetskog algoritma koji radi sa sitnozrnato raspodijeljenom populacijom. MPGA za svoju implementaciju zahtjeva višeprocesorsko računalo koje se sastoji od mnogo procesora. U internoj memoriji procesora pohranjena je jedna jedinka – jedinka procesora. Često se veličina populacije ograničava brojem procesora, ali se može implementirati i model s više jedinki po procesoru. Ono što razlikuje MPGA od DGA-a je to što se migracija obavlja samo među susjednim procesorima. Susjedstvo procesora definira se topologijom susjedstva. Svi procesori paralelno obavljaju sve genetske operatore i evaluaciju. Unarni operatori (evaluacija i mutacija) obavljaju se nad jedinkom pohranjenom u memoriji procesora, dok se binarni operator križanja obavlja nad jedinkom procesora i jedinkom koja je selekcijom odabrana među susjedima. Jedinka dobivena križanjem, zamijenit će pohranjenu jedinku.
Masovno_paralelni_genetski_algoritam()
{
generiraj_paralelno_populaciju_slučajnih_jedinki();
dok (nije_zadovoljen_uvjet_završetka_evolucijskog_procesa)
{
paralelno_za_svaku_jedinku
{
evaluiraj();
selektiraj(); // među susjedima i sobom
reproduciraj(); // sebe i selektiranu jedinku
nadomjesti(); // novom jedinkom
}
}
}
Pseudokod 3-2 - Masovno paralelni genetski algoritam
Masovno paralelni genetski algoritam uvodi dva nova parametra kontrole raznolikosti populacije. Topologija susjedstva ima utjecaj na smjer i brzinu propagacije boljih rješenja. Ukoliko procesori MPGA-a imaju velik broj susjeda, bolja rješenja će se brže širiti, a to može dovesti do brze konvergencije k lokalnom optimumu. Manji broj susjeda (tj. veća izoliranost subpopulacija) omogućava GA-u da pretraži puno veći prostor rješenja, ali neće spriječiti propagaciju boljih rješenja.




Slika 3-2 - Različite topologije susjedstva u MPGA, procesori obojani s dvije boje predstavljaju procesore na kojima se događa preklapanje susjedstva istaknutih procesora
Distribuirani genetski algoritam je oblik paralelnog genetskog algoritma koji radi sa raspodijeljenom populacijom. Umjesto izvođenja genetskog algoritma nad jednom velikom populacijom, distribuirani genetski algoritam djeluje na više manjih populacija. Svaka populacija nalazi se u jednom čvoru. Čvor može biti računalo u mreži ili procesor u višeprocesorskom sustavu. Genetski algoritmi u pojedinim čvorovima ne moraju biti jednaki, ali optimizacijski problem koji rješavaju mora biti isti. Čvorovi međusobno razmjenjuju jedinke u nadi da će jedinka koju dobiju usmjeriti GA u još neistražene dijelove područja rješenja te tako postići bolje rješenje.
Distribuirani_genetski_algoritam()
{
inicijaliziraj_P_populacija();
dok (nije_zadovoljen_uvjet_završetka_evolucijskog_procesa)
{
za svaku subpopulaciju obavljaj paralelno
{
evaluiraj();
ako ((broj_iteracija % period_izmjene) == 0)
{
migracija();
{
selektiraj();
križaj();
mutiraj();
}
}
}
Pseudokod 3-3 - Distribuirani genetski algoritam
Distribuirani genetski algoritam pogodan je za implementaciju na umreženim računalima. Ulogu čvorova preuzimaju pojedina računala, a jedinke se razmjenjuju preko mreže.
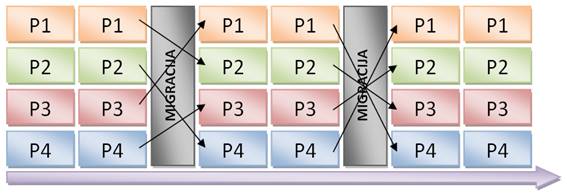
Slika 3-3 - Distribuirani genetski algoritam s četiri populacije
Migracija i način njene implementacije imaju snažan utjecaj na uspješnost DGA. Postupak migracije uvodi pet novih parametara u GA: migracijski interval, migracijsku stopu, strategiju odabira boljih jedinki, strategiju odabira jedinki za eliminaciju i topologiju razmjene jedinki.
Migracijski interval određuje broj iteracija između dvije migracije. Migracijski interval označava se Mi. Ponekad se umjesto migracijskog intervala koristi migracijska frekvencija fi= Mi^(-1). Migracijski interval može biti konstantan (unaprijed određen) ili slučajan. U slučaju nekonstantnog migracijskog intervala, za analizu rada GA-a, važan je prosječan faktor migracijskog intervala. Operator mutacije može biti i uvjetovan. U tom slučaju migracija se odvija samo kada je ispunjen unaprijed određeni uvjet.
Što je frekvencija migracije manja to su populacije izoliranije. Ukoliko su populacije izolirane, tada GA pretražuje različite prostore rješenja. Ipak, ukoliko su populacije potpuno izolirane, tada se DGA degradira na svojstva GA-a sa veličinom populacije veličine jedne subpopulacije DGA. Takav GA nužno je lošiji od sekvencijskog GA-a s većim brojem jedinki. Druga krajnost je provedba operatora migracije u svakoj iteraciji GA-a. Takav genetski operator ima svojstva slična sekvencijskim genetskim algoritmima s istom veličinom populacije samo ako se uvijek razmjenjuju najbolje jedinke. Provedba operatora migracije u svakoj iteraciji također može zagušiti komunikacijski kanal kojim se razmjenjuju jedinke, čime se dodatno usporava provedba distribuiranog genetskog algoritma.
Migracijska stopa određuje broj jedinki koji se razmjenjuje između subpopulacija. Migracijska stopa označava se Ms. Migracijska stopa utječe na različitost populacija. Ukoliko se velik broj jedinki kopira iz jedne populacije u drugu, tada će te populacije postajati sve sličnije. U tom slučaju subpopulacije će se usmjeriti na isti prostor rješenja, te će DPA biti manje učinkovit od sekvencijskog GA-a s istom veličinom populacije. Uobičajeno je u migraciji izmijeniti samo jednu jedinku između susjednih subpopulacija.
Strategija odabira jedinki značajno utječe na selekcijski pritisak, a time i na brzinu konvergencije algoritma. Selekcijski pritisak veći je, što bolje jedinke imaju veću vjerojatnost preživljavanja u odnosu na loše jedinke i obrnuto.
Prilikom razmjene moguće je odabrati jedinke za razmjenu i jedinke koje će nove jedinke zamijeniti. U oba slučaja mogu se koristiti strategija slučajnog odabira ili strategija odabira najboljih, odnosno najlošijih jedinki. U primjeni se najčešće koristi izbor najboljih jedinki za razmjenu, a slučajan odabir ili odabir najgorih jedinki za eliminaciju.
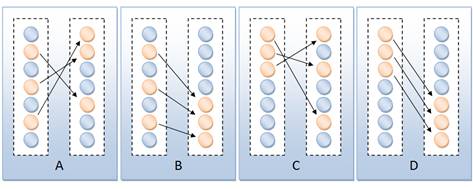
Slika 3-4 – Strategije izbora jedinki – a) slučajan odabir jedinki za slanje i eliminaciju, b) slučajno odabrane jedinke nadomještaju najlošije, c) najbolje jedinke nadomještaju slučajno odabrane, d) najbolje jedinke nadomještaju najgore
Topologija razmjene jedinki može biti statička ili dinamička. Uobičajeno se koristi statička topologija, koja se definira na početku, te se ne mijenja do kraja izvođenja GA-a. Ako se koristi dinamička topologija, tada GA slučajnim odabirom odlučuje koje će subpopulacije poslati svoje jedinke kojim subpopulacijama, ili se unaprijed definira dinamička strategija izmjena topologije.
Brzina širenja nekog rješenja među subpopulacijama ovisi o broju subpopulacija kojima subpopulacija šalje svoje jedinke. Subpopulacije koje primaju jedinke od neke druge subpopulacije nazivaju se njenim susjedima. Što topologija ima više susjedstva, to je veća brzina kojom se šire rješenja po drugim subpopulacijama. Prevelik broj susjedstva može opteretiti komunikacijski kanal te tako usporiti izvođenje GA-a.
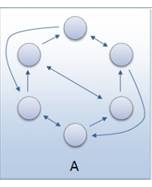
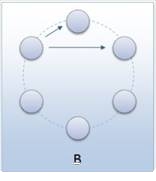
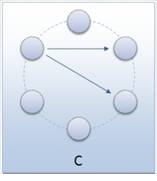
Slika 3-5 - Primjeri topologija s dva susjeda
Topologije s više slojeva imaju manju vjerojatnost zaglavljivanja u lokalnom optimumu. Najbolja rješenja nižih slojeva skupljaju se u jednoj ili više populacija višeg sloja. Ukoliko neka subpopulacija nižeg sloja zaglavi u lokalnom optimumu, GA višeg sloja eliminirat će to rješenje uporabom selekcije.
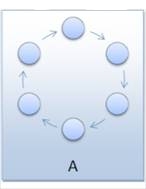
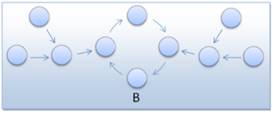
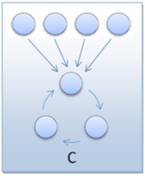
Slika 3-6 - Primjeri topologija razmjene jedinki - a) prstenasta topologija, b) tipična višeslojna topologija s jednim susjedom, c) dvoslojna otočna topologija
Za razliku od CPU-a koji je namijenjen za obavljanje velikog broja različitih operacija, grafički procesori specijalizirani su za paralelno izvođenje istih operacija nad velikim brojem podataka. Stoga se i arhitektura CPU-a i GPU-a znatno razlikuje. Ipak, osnovne jedinice čipa su iste – memorija, priručna memorija, kontrolna jedinica i aritmetičko-logička jedinica.
Osnovna zadaća GPU-a jest obraditi veliki broj podataka istim setom naredbi. Iz tog razloga broj ALU-a je višestruko veći nego kod CPU-a. Današnji dizajn NVIDIA GPU-a okuplja po osam jezgri u jednu procesorsku jedinku. Po tri procesorske jedinke okupljene su u jedan grozd za procesiranje dretvi (TPC – thread processing cluster). Primjerice NVIDIA GTX280 sadrži deset TPC-a – ukupno 240 jezgri, te postiže vršnu brzinu od 933 GFLOPs-a.
Za CPU je dohvat podataka iz memorije jedna od najskupljih operacija. Iz tog razloga, priručna memorija na CPU-u je vrlo velika. Kako se na grafičkoj jedinici istim instrukcijama obrađuje više podataka, ti podaci se raspoređuju u više manjih priručnih memorija, kojima procesori mogu vrlo brzo pristupiti. Svaka procesorska jedinka ima svoju priručnu memoriju veličine 16Kb. Podaci se u priručnu memoriju raspoređuju uglavnom prije početka obrade, te se optimira njihov raspored (na riječi od 16, 32, 64 ili 128 bita), kako bi se mogli dohvatiti paralelno za svaku jezgru procesorske jedinke. Ukoliko je raspored podataka tako optimiran, trošak dohvata iz priručne memorije otprilike je jednak dohvatu podatka iz registra. Osim 16Kb priručne memorije, svaka procesorska jedinica ima svoju kontrolnu jedinicu.
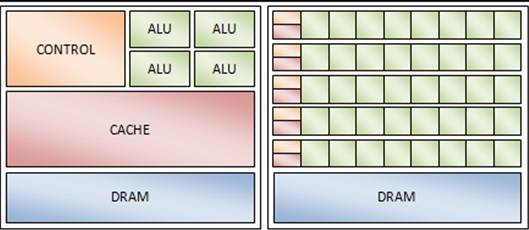
Slika 4-1 - Usporedba arhitekture CPU-a i GPU-a
Slika 4 2 shematski prikazuje hijerarhiju memorije na grafičkoj jedinici. Svaki procesor (element procesorske jedinke) ima skup registara. Svaka procesorska jedinica ima dijeljenu memoriju (shared memory) koja se može čitati i pisati, te je pristup njoj najbrži. Osim te memorije, postoje još dvije priručne (cache) memorije koje se mogu samo čitati – za konstante i teksture (constant memory i texture memory). Uređaj također sadrži glavnu memoriju, čija je veličina najveća, ali je pristup njoj najskuplji.
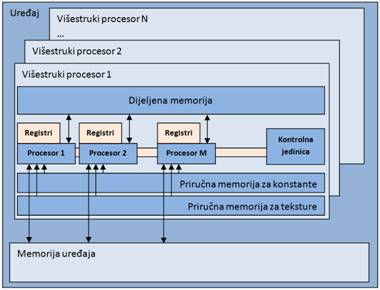
Slika 4-2 – Shematski prikaz hijerarhije memorije na grafičkoj jedinici. Strelice označavaju smjer u kojem je moguće čitanje, odnosno pisanje.
NVIDIA GTX280 uređaj ima sljedeće memorijske kapacitete:
Zahvaljujući velikom broju jezgri, ali i manjoj raznovrsnosti operacija koje se izvode na GPU-u, u posljednjih nekoliko godina GPU je znatno nadmašio CPU u broju mogućih FLOPs-a po sekundi. Iz toga možemo zaključiti da je GPU pogodan za izvođenje paralelnih, procesorski zahtjevnih algoritama kao što je genetski algoritam.
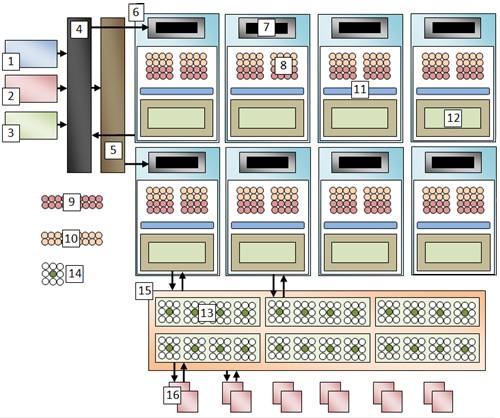
Slika 4-3 – Detaljna arhitektura GPU čipa
Programsko rješenje ostvareno je kombinacijom .NET (grafičko sučelje i dijelovi algoritama koji se izvršavaju na matičnom procesoru) i CUDA tehnologija (dijelovi algoritma koji se izvršavaju na grafičkom procesoru).
CUDA (kratica za Compute Unified Device Architecture) je arhitektura za paralelno računanje koju je razvila NVIDIA. CUDA je dostupna na NVIDIA GPU-ovima kroz standardne programske jezike. C for CUDA je ekstenzija programskog jezika C koja uključuje naredbe za kontrolu GPU-a. U CUDA programu, kod za CPU može biti u C++ jeziku, dok se za GPU može koristiti samo C. CUDA pruža programerima pristup nativnim setovima instrukcija i memoriji GPU-a. Koristeći CUDA-u, programeri mogu razvijati aplikacije namijenjene izvođenju na GPU-u, kojemu više nije potrebno pristupati kroz setove instrukcija za obradu grafike. Tipična CUDA aplikacija je heterogena. Sastoji se od CPU i GPU funkcija. GPU i CPU izvode različite vrste koda. CPU izvodi glavni program i šalje GPU-u zadatke u obliku kernel funkcija. Više različitih kernel funkcija može biti deklarirano i pozvano, ali se samo jedan kernel može izvršavati u jednom trenutku.
Dretve su organizirane u blokove. Blokovi dretvi su sadržani u mreži. (Thread-Block-Grid) Procesorska jedinka izvršava jedan blok u jednom trenutku. Skup dretvi koji se izvršava u jednom trenutku naziva se paket (warp). Programer sam specificira topologiju dretvi pri pozivu funkcije koja će se izvoditi na GPU-u. Topologija može biti određena kao jednodimenzionalna, dvodimenzionalna ili trodimenzionalna, što vrijedi i za blokove i za dretve. Takvo indeksiranje dretvi i blokova olakšava pisanje kompleksnijih algoritama u kojima je topologija bitna.
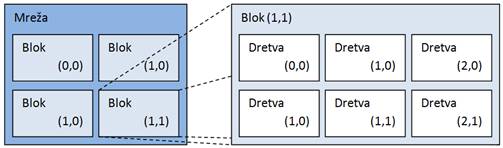
Slika 5-1 – Primjer topologije dretvi – mreža se sastoji od 2x2 blokova, a svaki blok od 3x2 dretvi
CUDA.NET je omotač koji pruža programeru mogućnost pozivanja funkcionalnosti CUDA tehnologije iz .NET programskih jezika. CUDA.NET omogućuje lakše kombiniranje prednosti .NET tehnologije u razvoju sučelja i objektnog dizajna, te CUDA paralelizacije na višestrukom grafičkom procesoru.
Zadan je skup točaka T = {(x1,y1), (x2,y2), (x3,y3),….., (x4,y4)} i funkcija g(x) s neodređenim koeficijentima a0,a1,a2,….,aN-1, gdje je ai ∈ [dgi, ggi]. Ako je za zadani skup točaka os x vrijeme (x = t), tj. zadan je niz vrijednosti u određenim vremenskim trenutcima, tada je skup točaka T skup vrijednosti u diskretnim vremenskim trenutcima i naziva se vremenski niz, odnosno T = {(t1,y1), (t2,y2), (t3,y3),….., (t4,y4)}. Zadatak je odrediti N koeficijenata a0 do aN-1 pomoću genetskog algoritma, tako da kvadrat odstupanja funkcije g(t) u zadanim točkama bude minimalan:
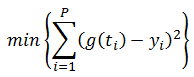 | (3-2) |
Za genetski algoritam to je N-dimenzijski problem i u kromosomu je zapisan vektor koeficijenata a. Funkcija cilja f koju treba minimizirati glasi:
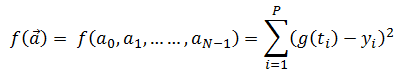 | (3-2) |
Koeficijenti a0,a1,a2,….,aN-1 koji određuju funkciju g(t) su nepoznanice za funkciju cilja f. Rješenje zadanog problema je jedna ili više točaka u N dimenzijskom prostoru.
Za funkciju g(x) odabrana je funkcija a proksimacije pomoću sinusnih funkcija.
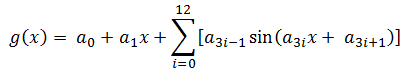 | (3-2) |
Koeficijenti se nalaze unutar sljedećih ograničenja:
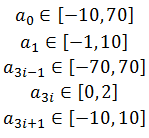 | (3-2) |
Cilj optimiranja jest odrediti koeficijente a0, a1, …, a37, tj. 38 realnih brojeva. Koristi se binarni prikaz i svaka je nepoznanica predstavljena s 32 bita. Ukupno treba odrediti 1216 bitova.
Programsko rješenje ostvareno je u programskom okruženju Visual Studio 2008. Program je strukturiran u četiri knjižnice klasa i jedno sučelje.

5-2 - Struktura programskog rješenja
Grafičko sučelje programa sastoji se od upravljačke vrpce (ribbon) i grafa.
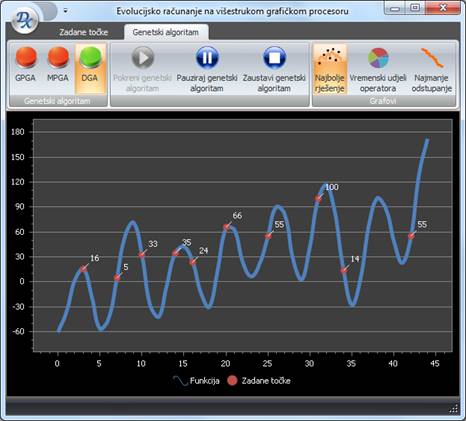
Slika 5-3 – Sučelje realizirane aplikacije
Prva kartica (tab) upravljačke vrpce sadrži naredbe za manipulaciju i prikaz zadanih točaka. Točke se mogu učitati iz datoteke ili unijeti kroz prozor za unos točaka. Zadane točke mogu se spremiti u datoteku.

Slika 5-4 - Prva kartica upravljačke vrpce
Druga kartica upravljačke vrpce (Slika 5-5) sadrži naredbe za odabir i pokretanje genetskog algoritma. GA također se može pauzirati i zaustaviti. Kartica također sadrži naredbe za odabir podataka koji će se prikazati na grafu.

Slika 5-5 - Druga kartica upravljačke vrpce
Graf može prikazivati različite informacije: prikaz trenutno najbolje aproksimacijske funkcije, postotni vremenski udjeli pojedinih operatora paralelnog GA-a ili vrijednosti minimalnog odstupanja kroz iteracije GA-a. Slika 5 3 prikazuje sučelje programa, a na grafu je prikazana trenutna najbolja aproksimacijska funkcija. Podaci prikazani na grafu osvježavaju se u intervalu od pola sekunde.
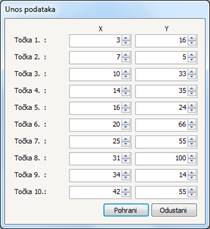
Slika 5-6 - Prozor za unos zadanih točaka
Prozor za unos zadanih točaka sastoji se od deset parova kontrola za unos cijelih brojeva. Nakon što se brojevi ručno unesu, odnosno promijene, mogu se pohraniti u datoteku pomoću naredbi na prvoj kartici upravljačke vrpce.
U masovno paralelnom genetskom algoritmu paralelizirani su evaluacija i križanje. Uloga CPU-a je provedba mutacije, komunikacija sa sučeljem, protok podataka između CPU-a i GPU-a te GPU-a i CPU-a kada je to potrebno. CPU također poziva CUDA kernele. Svi kerneli pokreću se s topologijom blokova 2x2, te topologijom dretvi 8x8.
Veličina populacije GA-a je 256 jedinki. Vjerojatnost mutacije jedinke je 0.2, pri čemu mogu mutirati jedan do tri gena. Broj iteracija GA-a je 10000.

Slika 5-7 – Topologija susjedstva MPGA
Topologija susjedstva MPGA-a prikazana je na slici iznad. Svaka jedinka susjedna je sa četiri druge jedinke. Jedinke iznad, ispod, lijevo i desno su susjedne s centralnom jedinkom. Za dvije susjedne jedinke preklapanje susjedstava iznosi jedan (samo su si te jedinke u oba susjedstva). Dvije jedinke koje se dodiruju po dijagonali imaju preklapanje susjedstva dva. Po dvije jedinke iz njihovih susjedstava se preklapaju.
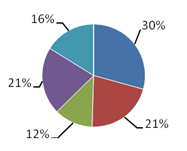
Slika 5-8 – Na lijevom su grafu prikazani vremenski udjeli u slučaju pretvorbe byte[] u float obavlja na GPU-u, a na desnom grafu su vremenski udjeli u slučaju pretvorbe byte[] u float obavlja na CPU-u
U slučaju pretvorbe byte[] genoma u float genom na GPU-u, evaluacija je najskuplji operator, te uzima 50% ukupnog vremena. Dio evaluacije koji se obavlja na procesoru zauzima malo više od polovice vremena evaluacije, (29% ukupnog vremena), dok dio koji se obavlja na GPU-u uzima 21% vremena. Križanje je sljedeći najskuplji operator, te uzima 33% vremena. CPU obavlja križanje 12% vremena, dok GPU troši 21%. Mutacija troši 16% vremena. Kada se pretvorba iz byte[] genoma u float genom obavlja na CPU-u, tada vremenski udjeli postaju znatno drugačiji. Evaluacija je i dalje daleko najskuplji operator, te uzima 83% vremena. Dio evaluacije koji se obavlja na procesoru (pretvorba byte[] - float) obuhvaća najveći dio vremena (76%), dok dio koji se obavlja na GPU-u uzima svega 7% vremena. Križanje je sljedeći najskuplji operator te uzima 11% vremena. CPU obavlja križanje 4% vremena, dok GPU troši 7%. Mutacija troši 6% vremena. U završnom programu implementirana je pretvorba iz byte[] u float na CPU-u.
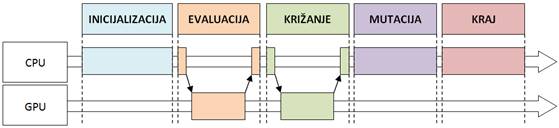
Slika 5-9 – Dijagram tijeka MPGA-a
Prilikom evaluacije i križanja, inicijalne radnje obavljaju se na CPU-u (kopiranje podataka, alokacija memorije na GPU-u i dr.). Zatim se poziva kernel koji obavlja funkciju pojedinog operatora na GPU-u. Nakon što GPU završi posao, na CPU-u se obavljaju finalizacijske radnje operatora (oslobađanje memorije, sortiranje i dr. ). Mutacija se u potpunosti izvršava na CPU-u.
Klasa GA je jedina klasa vidljiva prema van (public). Ona sadrži funkcije inicijalizacije i iteriranja genetskog algoritma. Funkcija inicijalizacije alocira potrebne memorije na grafičkoj kartici i računalu, inicijalizira populaciju i inicijalizira klasu za generiranje slučajnih brojeva.
Klasa RandomProvider generira slučajne brojeve. Klasa je statička, te tako omogućava svakoj iteraciji generiranje jedinstvenog niza brojeva.
Klasa CUDAProvider je statička klasa koja pruža pristup CUDA driveru. Također sadrži statičke pokazivače na alociranu memoriju na višestrukom grafičkom procesoru.
Klasa Constraints je statička klasa koja pruža podatke o ograničenjima faktora sinusoidalne funkcije.
Klasa Entity sadrži podatke o faktorima sinusoidalne funkcije. Svaki kromosom sastoji se od 32 bajta.
Klasa Population sadrži funkcije koje obavljaju genetske operatore, te inicijaliziraju populaciju.
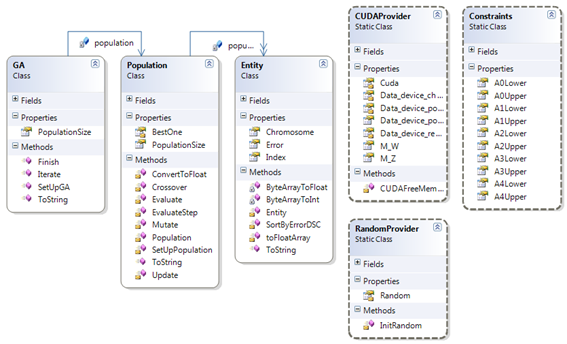
Slika 5-10 – Arhitektura programskog rješenja MPGA-a (Cellular GA)
U globalnom paralelnom genetskom algoritmu paralelizirana je evaluacija. Paralelizacija se izvršava u četiri bloka, čime se simulira postojanje četiri sluge. Takva paralelizacija je odabrana jer višestruki grafički procesor ima četiri procesorske jedinke. Svaka procesorska jedinka simulira jednog slugu. Evaluacija se pokreće s topologijom blokova 1x4, te topologijom dretvi 1x64.
Veličina populacije GA-a je 256 jedinki. Vjerojatnost mutacije jedinke je 0.15, pri čemu mogu mutirati jedan do tri gena. U svakoj iteraciji eliminira se trećina najlošijih jedinki, a one se nadomjeste križanjem među preostalim, jačim jedinkama. Broj iteracija GA-a je 10000. GPGA radi podjelu evaluacije na četiri sluge. Svaki sluga obavlja evaluaciju jedne četvrtine populacije.
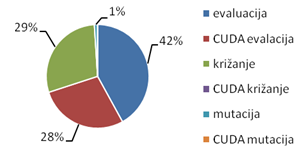
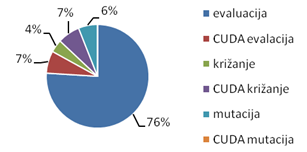
Slika 5-11 – Vremenski udjeli GPGA-a
Evaluacija je najskuplji operator, te ukupno uzima 70% vremena. Od tih 70%, čak 42% posla obavlja se na procesoru, dok se 28% posla obavlja na GPU-u. Križanje je sljedeći najskuplji operator, te uzima 29% vremena. Mutacija je najjeftiniji operator, te troši samo 1% ukupnog vremena.
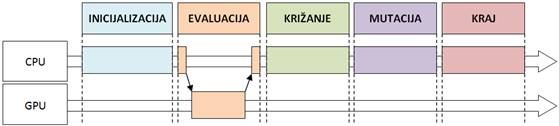
Slika 5-12 – Dijagram tijeka GPGA-a
Prilikom evaluacije inicijalne radnje obavljaju se na CPU-u (kopiranje podataka, alokacija memorije na GPU i dr.). Zatim se poziva kernel koji obavlja funkciju evaluacije na GPU-u. Nakon što GPU završi posao, na CPU-u se obavljaju finalizacijske radnje operatora (oslobađanje memorije, sortiranje i dr. ). Operatori mutacije i križanja obavljaju se u cijelosti na CPU-u.
Klasa GA je jedina klasa vidljiva prema van (public). Ona sadrži funkcije inicijalizacije i iteriranja genetskog algoritma. Funkcija inicijalizacije alocira potrebne memorije na grafičkoj kartici i računalu, te inicijalizira populaciju.
Klasa RandomProvider generira slučajne brojeve. Klasa je statička, te tako omogućava svakoj iteraciji da generira jedinstven niz brojeva.
Klasa CUDAProvider je statička klasa koja pruža pristup CUDA driveru. Također sadrži statičke pokazivače na alociranu memoriju na višestrukom grafičkom procesoru.
Klasa Constraints je statička klasa koja pruža podatke o ograničenjima faktora sinusoidalne funkcije.
Klasa Entity sadrži podatke o faktorima sinusoidalne funkcije. Svaki kromosom sastoji se od 32 bajta.
Klasa Population sadrži funkcije koje obavljaju genetske operatore, te inicijaliziraju populaciju.
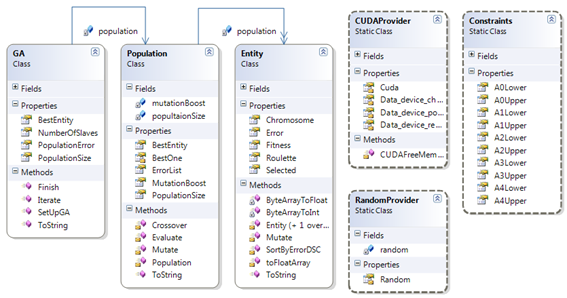
Slika 5-13 – Arhitektura programskog rješenja GPGA-a
Distribuirani genetski algoritam realiziran je kao distribuirani globalni paralelni genetski algoritam (DGA / GPGA). Populacija je podijeljena u četiri subpopulacije, a svaka subpopulacija ponaša se kao zasebni globalni paralelni genetski algoritam.
U distribuiranom genetskom algoritmu paraleliziran je najskuplji operator – evaluacija.
Veličina populacije GA-a je 256 jedinki. Vjerojatnost mutacije jedinke je 0.15, pri čemu mogu mutirati jedan do tri gena. Broj iteracija GA-a je 10000. U svakoj iteraciji eliminira se trećina najlošijih jedinki, a one se nadomjeste križanjem među preostalim, jačim jedinkama. Broj iteracija GA-a je 10000. GPGA radi podjelu evaluacije na četiri sluge. Svaki sluga obavlja evaluaciju jedne četvrtine populacije.
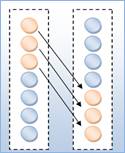
Slika 5-14 – Topologija razmjene realiziranoga distribuiranoga genetskog algoritma
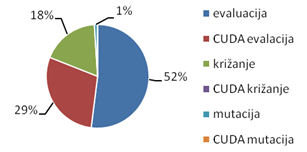
Slika 5-15 – Vremenski udjeli DGA-a
Evaluacija je najskuplji operator, te ukupno uzima 81% vremena. Od tih 81%, čak 52% posla obavlja se na procesoru, dok se 29% posla obavlja na GPU-u. Križanje je sljedeći najskuplji operator, te uzima 18% vremena. Mutacija je najjeftiniji operator, te troši samo 1% vremena.
Slika 5-16 – Dijagram tijeka DGA/GPGA-a
Prilikom evaluacije inicijalne radnje obavljaju se na CPU-u (kopiranje podataka, alokacija memorije na GPU-u i dr.). Zatim se poziva kernel koji obavlja funkciju evaluacije na GPU-u. Nakon što GPU završi posao, na CPU-u se obavljaju finalizacijske radnje operatora (oslobađanje memorije, sortiranje i dr. ). Operatori mutacije i križanja obavljaju se u cijelosti na CPU-u.
Klasa GA je jedina klasa vidljiva prema van (public). Ona sadrži funkcije inicijalizacije i iteriranja genetskog algoritma. Funkcija inicijalizacije alocira potrebne memorije na grafičkoj kartici i računalu, te inicijalizira populaciju.
Klasa RandomProvider generira slučajne brojeve. Klasa je statička, te tako omogućava svakoj iteraciji generiranje jedinstvenog niza brojeva.
Klasa CUDAProvider je statička klasa koja pruža pristup CUDA driveru. Također sadrži statičke pokazivače na alociranu memoriju na višestrukom grafičkom procesoru.
Klasa Constraints je statička klasa koja pruža podatke o ograničenjima faktora sinusoidalne funkcije.
Klasa Entity sadrži podatke o faktorima sinusoidalne funkcije. Svaki kromosom sastoji se od 32 bajta.
Klasa Population sadrži funkcije koje obavljaju genetske operatore, te inicijaliziraju populaciju.
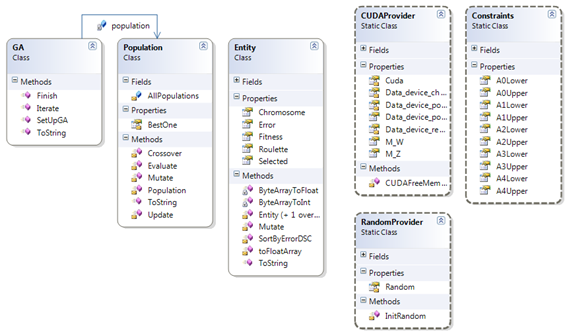
Slika 5-17 – Arhitektura programskog rješenja DGA/GPGA-a
Kao ocjena kvalitete pojedine aproksimacijske funkcije koristila se podjela prikazana u tabeli 5-1. Što je suma kvadrata odstupanja aproksimacijske funkcije od zadanih točaka manja, to je aproksimacijska funkcija bolja.
Za svaki implementirani algoritam obavljena su mjerenja uspješnosti u rješavanju problema. Raspodjela rezultata izvođenja pojedinog algoritma prema kategorijama iz tabele 5-1 prikazana je u tabeli 5-2.
Tabela 5-1 - Ocjena dobrote rješenja
| Kvadrat odstupanja: | Ocjena: |
| f>1000 | neupotrebljivo |
| 150>f>=1000 | loše |
| 50>f>=150 | dobro |
| f>=50 | zadovoljavajuće |
DGA je tijekom testiranja dao najbolje rezultate: više od 70% izvođenja dalo je zadovoljavajući rezultat. GPGA također je dao vrlo dobre rezultate: više od 50% izvođenja dalo je zadovoljavajući rezultat, dok je još 25% izvođenja dalo dobar rezultat. MPGA je dao najlošije rezultate: približno 6% izvođenja dalo je zadovoljavajuće rezultate. Ipak, nešto više od 55% izvođenja dalo je dobre rezultate.
Tabela 5-2- Učestalost pojavljivanja rješenja pojedine kvalitete za svaki PGA
| Neupotrebljivo | Loše | Dobro | Zadovoljavajuće | Ukupno mjerenja | |
| GPGA | 6.7 % | 13.3 % | 26.7 % | 53.5 % | 15 |
| MPGA | 0 % | 37.5 % | 56.2 % | 6.3 % | 16 |
| DGA | 0 % | 7.1 % | 28.6 % | 71.4 % | 14 |
Prilikom testiranja korištene su točke: {(3, 16), (7, 5), (10, 33), (14, 35), (16, 24), (20, 66), (25, 55), (31, 100), (34, 14), (42, 55)}. Najmanji dobiveni zbroj kvadrata odstupanja aproksimacijske funkcije od zadanih točaka prilikom testiranja bio je ~ 0.3, te je dobiven DGA algoritmom.
Tabela 5-3 prikazuje trajanje izvođenja pojedinih paralelnih genetskih algoritama. Trajanje je izraženo u sekundama i postotcima.
Tabela 5-3 – Trajanje izvođenja GA-a, podaci označeni * dobiveni su izračunom prema vremenskim udjelima pojedinih operatora
| MPGA | GPGA | DGA/GPGA | ||||
| % | (s) | % | (s) | % | (s) | |
| Ukupno trajanje | 100 | 21.9 | 100 | 70.3 | 100 | 66.4 |
| Evaluacija CPU | 29 | 6.4 | 42 | 29.5 | 52 | 34.5 |
| Evaluacija GPU | 21 | 4.6 | 28 | 19.7 | 29 | 19.3 |
| Križanje CPU | 12 | 2.6 | 29 | 20.4 | 18 | 11.9 |
| Križanje GPU | 21 | 4.6 | - | - | - | - |
| Mutacija CPU | 16 | 3.5 | 1 | 0.7 | 1 | 0.6 |
| Mutacija GPU | 0 | 0 | - | - | - | - |
Svi algoritmi obavljaju deset tisuća iteracija. Globalni paralelni genetski algoritam i distribuirani genetski algoritam imaju otprilike jednako trajanje. Razlog tomu je što oba GA-a obavljaju iste operatore – DGA je zapravo skup više DPGA-a. Trajanje je nešto kraće kod DGA-a jer njegova sortiranja populacije rade nad više skupova manjeg broja elemenata.
MPGA ima znatno kraće trajanje od GPGA-a i DGA/GPGA-a. Za takav rezultat ima nekoliko razloga:
CUDA je vrlo moćan alat za paralelno izvođenje fine-grained algoritama. NVIDIA je otvaranjem pristupa GPU-u omogućila programerima jeftinu i učinkovitu opciju za paralelizaciju programa. Ostvareni paralelni algoritmi pokazali su se vrlo učinkovitima. Dodatna ubrzanja mogu se postići optimiranjem dohvata podataka (djelomični dohvat), pohranjivanjem podataka za blokove u priručnu memoriju, te optimiranjem poretka adresiranja podataka u priručnoj memoriji. Svaki podatak potrebno je uskladiti sa adresama (svaka 16., 32., 64. ili 128. adresa) kako bi dohvat bio efikasniji.
Razvijanjem TESLA jedinica, koje sadrže oko tisuću jezgri, NVIDIA nudi jeftinu alternativu superračunalima. Jedna TESLA S1070 jedinica postiže vršnu učinkovitost na 3.73 do 4.14 TFLOPs-a. Korištenjem nekoliko takvih jedinica mogu se postići vrlo visoke mogućnosti paralelnog računanja. Sljedeće generacije NVIDIA CUDA uređaja, omogućit će korisnicima pokretanje više različitih kernela u isto vrijeme, što se do sada nije moglo činiti. Taj korak će omogućiti razvoj asinkronih genetskih algoritama na grafičkim uređajima.