1. Uvod
U radu se predstavlja hibridni genetski algoritam kojim je riješen problem optimalnog grupiranja. Problem optimalnog grupiranja pripada kategoriji NP-teških problema, te pronalazi mnoge primjene u industriji. U radu je dan opis hibridnog genetskog algoritma i programskog ostvarenja. Programski sustav je detaljno opisan, analizirane su svojstva sustave, kvaliteta rješenja koje sustav stvara, te opisani utjecaji parametara hibridnog genetskog algoritma na performanse sustava.
Upoznavanje hibridnog genetskog algoritma dano je u drugom poglavlju. Uvod u genetski algoritam dan je u poglavlju 2.1. Poglavlje 2.2 daje uvod u hibridne genetske algoritme, poglavlje 2.3 daje motivaciju, dok poglavlje 2.4 opisuje sam algoritam koji se dodatno razmatra. Poglavlje 2.5 opisuje genetske operatore.
Problem optimalnog grupiranja rješava se u trećem poglavlju. Poglavlje 3.1 opisuje problem koji se rješava dok poglavlje 3.2 detaljno opisuje algoritam koji se koristi za rješavanje problema optimalnog grupiranja. Poglavlje 3.3 opisuje programsko ostvarenje koje se analizira u poglavlju 3.4. Poglavlje 3.5 daje primjenu programskog rješenja.
2. Hibridni genetski algoritam
2.1 Uvod u genetske algoritme
Kroz milijune godina različite vrste se razvijaju kako bi što bolje preživjele u okolišu koji ih okružuje. Razvijene prilagodbe se prenose unutar vrste kroz generacije, te se proces prilagodbe nastavlja. Prilagodbe su većinom takve da omogućuju jedinki bolje šanse za preživljavanje u svom okolišu. Promjene koje su štetne postepeno iščezavaju, dok promjene koje su korisne imaju veće šanse za očuvanjem jer osiguravaju preživljavanje jedinke koja ih posjeduje. Na taj način priroda uspijeva razviti sve naprednije organizme koji su sve sposobniji preživljavanju u okolišu koji ih okružuje.
Inspirirana procesom evolucije, znanost je
razvili računalnu paradigmu zvanu evolucijsko računarstvo (engl. evolutionary
computation) koja oponašanjem prirodnih evolucijskih procesa pokušava
riješiti razne procesorski zahtjevne računalne probleme. U području
umjetne inteligencije, evolucijski algoritmi predstavljaju podskup evolucijskog
računarstva [11]. Evolucijski algoritmi koriste neke mehanizme inspirirane
biološkom evolucijom: selekcija, reprodukcija, mutacija i rekombinacija, kako
bi pronašli što bolje rješenje određenog problema. Potencijalna rješenja
optimizacijskog problema kojeg evolucijski algoritam pokušava riješiti igraju
ulogu ![]() u
u ![]() . Pritom se potencijalna rješenje (jedinke) međusobno kombiniraju
i razvijaju na sličan način kao što to u prirodi čine biološke
jedinke neke vrste.
. Pritom se potencijalna rješenje (jedinke) međusobno kombiniraju
i razvijaju na sličan način kao što to u prirodi čine biološke
jedinke neke vrste.
Evolucijski algoritmi često dobro aproksimiraju rješenja bilo kojeg problema jer nemaju ugrađene pretpostavke o izgledu domene pretrage nad kojim se provode. To opće svojstvo čini evolucijske algoritme korisnim u raznovrsnim područjima poput: umjetnosti, ekonomije, marketinga, robotike, sociologije, fizike, politike i kemije [10]. Bitne komponente evolucijskih algoritama čine: genetski algoritmi, genetsko programiranje i evolucijske strategije [8].
Najpoznatiji primjer evolucijskih algoritama predstavlja genetski algoritam.
Genetski algoritmi su klasa računalnih metoda koje oponašaju principe prirodne evolucije za potrebe pretrage i optimizacije [4]. Genetski algoritmi koriste dvije bitne karakteristike prirodne evolucije:
- prenošenje informacija iz jedne generacije u drugu (nasljeđivanje) i
- nadmetanje za preživljavanje (preživljavanje najsposobnijih).
Glavne prednosti genetskih algoritama, koje ih čine podobnima za rješavanje problema iz stvarnog života su:
- Prilagodljivi su.
- Učinkoviti su u rješavanju kompleksnih problema u kojima je glavni cilj brzo naći dobro, no ne nužno i optimalno rješenje.
Posebno su podobni za aplikacije koje zahtijevaju pretragu i optimizaciju kada je prostor pretrage izrazito velik i kompleksan, te nema potrebe naći baš najbolje rješenje. Najviše se primjenjuju za razlikovanje uzoraka, procesiranje slika, prepoznavanje scena, dizajniranje neuronskih mreža, problem rasporeda, planiranje puta, optimizaciju problema trgovačkog putnika, bojanje grafova, numeričku optimizaciju, te mnoge druge probleme.
Genetski algoritmi (kratica GA) modeliraju
principe prirodnog genetskog sustava, pritom genetski materijal pojedine
jedinke (potencijalnog rješenja) biva zapisan u strukturu zvanu ![]() . GA koriste određeno znanje o prirodi problema kako bi oblikovali
funkciju dobrote, pomoću koje se pretraga usmjeruje u više
obećavajuća područja. Svaka jedinka (jedinku čini kromosom)
ima pridruženu vrijednost funkcije dobrote koja ocjenjuje koliko je jedinka
dobra u odnosu na rješenje koje predstavlja. Grupa jedinki se naziva
. GA koriste određeno znanje o prirodi problema kako bi oblikovali
funkciju dobrote, pomoću koje se pretraga usmjeruje u više
obećavajuća područja. Svaka jedinka (jedinku čini kromosom)
ima pridruženu vrijednost funkcije dobrote koja ocjenjuje koliko je jedinka
dobra u odnosu na rješenje koje predstavlja. Grupa jedinki se naziva ![]() . Različiti biološki inspirirani operatori poput selekcije,
križanja i mutacije bivaju primijenjeni na kromosome iz populacije, kako bi
stvorili potencijalno bolje rješenje danog problema.
. Različiti biološki inspirirani operatori poput selekcije,
križanja i mutacije bivaju primijenjeni na kromosome iz populacije, kako bi
stvorili potencijalno bolje rješenje danog problema.
Genetski algoritam se provodi sljedećim koracima [8]:
- Inicijalizira se populacija tako što se stvori određen broj jedinki sa slučajno popunjenim kromosomima (jedinke predstavljaju slučajno rješenje danog problema).
- Procjenjuje se dobrota pojedine jedinke (kvaliteta pojedinog rješenja koje jedinka predstavlja) pomoću funkcije dobrote.
- Selektiraju se jedinke koje se ne eliminiraju (provodi se selekcija).
- Nad selektiranim jedinkama se provode genetski operatori (križanje i mutacija).
- Novonastale i/ili promijenjene jedinke tvore novu populaciju.
- Prekida se algoritam ili nastavlja od 2. koraka.
U 2. koraku se svaka jedinka procjenjuje funkcijom dobrote koja brojčanom vrijednošću pokušava opisati sposobnost pojedine jedinke (potencijalnog rješenja) da riješi dani problem.
U 3. koraku se s većom vjerojatnošću odabiru bolje jedinke (preživljavanje najsposobnijih), kako bi sljedeća populacija imala bolju prosječnu dobrotu jedinki (napredak algoritma).
U 4. koraku se selektirane (preživjele) jedinke međusobno križaju i mutiraju kako bi stvorile nove jedinke.
Operatori križanja i mutacije se u genetskom
algoritmu provode na način sličan kao u prirodi. Mutacija se provodi
tako što se napravi manja promjena u strukturi koja zapisuje potencijalno
rješenje problema (kromosom), kao što se u prirodi napravi manja mutacija nad
genima jedinke. Pri križanju se pomoću dvije (ili više) jedinke (zvane ![]() ) stvara nova jedinka (zvana
) stvara nova jedinka (zvana ![]() ) čija struktura podatka (koja opisuje potencijalno rješenje danog
problema) nastaje kombiniranjem roditeljskih struktura podataka. Na sličan
način se u prirodi geni potomaka stvaraju kombiniranjem gena roditelja.
) čija struktura podatka (koja opisuje potencijalno rješenje danog
problema) nastaje kombiniranjem roditeljskih struktura podataka. Na sličan
način se u prirodi geni potomaka stvaraju kombiniranjem gena roditelja.
2.2 Hibridni genetski algoritmi
- Hibridni Genetski algoritmi (HGA) su klasa stohastičkih heuristika globalne pretrage u kojima se genetski algoritmi kombiniraju s tehnikama pretrage kako bi se popravila kvaliteta rješenja [13].
- Hibridni genetski algoritmi (HGA) su generalne metode pretrage korištene za navođenje heuristike [6]. Može se reći da je HGA strategija u kojoj se populacija optimizacijskih agenata sinergistički nadmeće i surađuje [1].
Za razliku od tradicionalnih evolucijskih
tehnika, hibridni genetski algoritam prvenstveno pokušava iskoristi sve
dostupno znanje o promatranom problemu [6]. Ugrađivanje znanja iz domene
problema u hibridni genetski algoritam nije opcionalan mehanizam nego
fundamentalna karakteristika algoritma. Takva filozofija se može odlično
opisati terminom ![]() . Termin je
uveo Richard Dawkins, a riječ
. Termin je
uveo Richard Dawkins, a riječ ![]() predstavlja analogiju gena u kontekstu kulturalne evolucije.
predstavlja analogiju gena u kontekstu kulturalne evolucije.
Engleski Oxford rječnik definira ![]() kao: "element kulture za koji se smatra da se prenosi
ne-genetskim načinima". To bi bili na primjer: zadnji trendovi u
modi, razmjena ideja među znanstvenicima, romani i poezija, čak se i
kod ptica primjećuje da imitiraju zvukove drugih ptica. Geni se prenose
biološki od kromosoma do kromosoma, dok se meme prenose imitacijom od mozga do
mozga.
kao: "element kulture za koji se smatra da se prenosi
ne-genetskim načinima". To bi bili na primjer: zadnji trendovi u
modi, razmjena ideja među znanstvenicima, romani i poezija, čak se i
kod ptica primjećuje da imitiraju zvukove drugih ptica. Geni se prenose
biološki od kromosoma do kromosoma, dok se meme prenose imitacijom od mozga do
mozga.
Prema Dawkinsovim riječima [6]: "Primjeri memea su zvukovi, ideje, fraze, moda, načini pravljenja jela ili gradnje lukova. Kao što se geni propagiraju u genetskom bazenu od tijela do tijela, tako se meme propagiraju u memetičkom bazenu od mozga do mozga procesom koji u širem smislu možemo nazvati imitacijom."
Navedeni citat ilustrira filozofiju hibridnog
genetskog algoritma: individualno popravljanje u kombinaciji sa suradnjom
unutar populacije [1]. Često se hibridni genetski algoritmi spominju pod
drugim imenima (![]() ,
, ![]() ,
, ![]() i
i ![]() samo su neki od popularnih izbora) [5]. (Naziv memetički
algoritam se u literaturi podjednako često spominje kao i termin hibridni
genetski algoritam)
samo su neki od popularnih izbora) [5]. (Naziv memetički
algoritam se u literaturi podjednako često spominje kao i termin hibridni
genetski algoritam)
Opis memea sugerira da se u kulturalnom evolucijskom procesu informacije ne prenose nepromijenjene među individuama. Naprotiv, informacije se procesiraju i poboljšavaju prilikom prenošenja. Poboljšavanje se u hibridnom genetskom algoritmu ugrađuje u obliku heuristika, aproksimacijskih algoritama, tehnika lokalne pretrage, specijaliziranih operatora križanja, kratkih egzaktnih metodama i sl. [6]. U suštini se većina hibridnih genetskih algoritama mogu promatrati kao strategije pretrage u kojoj se populacija optimizacijskih agenata nadmeće i surađuje. Uspjeh HGA može se tumačiti kao direktna posljedica sinergije različitih pristupa pretraživanju koje objedinjuje.
Najbitnija karakteristika HGA, korištenje znanja iz domene problema, također je poduprta mnogim teoretskim rezultatima [2]. Kao što David Wolpert i William G. Macready tvrde u takozvanom Nema-Besplatnog-Ručka teoremu (engl. No-Free-Lunch Theorem), performanse algoritma pretrage odgovaraju ugrađenoj količini (i kvaliteti) znanja iz domene problema [12]. Teorem podupire iskorištavanje znanja iz domene problema, što je svojstveno hibridnom genetskom algoritmu. Zato algoritam može rano u procesu pretraživanja stvoriti vrlo kvalitetna rješenja [7].
Genetski algoritam zbog ograničene veličine populacije često stvara rješenja lošije kvalitete od rješenjima koja se mogu dobiti metodama lokalne pretrage [9]. Genetski operatori su dobri u pronalaženja dobrog rješenja u najboljem području domene pretrage, te ih to ujedno ograničava pri pravljenju malih promjena u okolici trenutnih rješenja. Korištenjem metoda lokalne pretrage, u sklopu genetskog algoritma, mogu se popraviti sposobnosti pretraživanja bez da se uvedu ograničenja pri pretraživanju. Ukoliko se postigne pravi omjer globalnog i lokalnog pretraživanja (engl. exploitation and exploration) algoritam može stvoriti vrlo kvalitetna rješenja. Iako genetski algoritam može uspješno locirati područje u kojem se nalazi globalni maksimum, treba mu relativno mnogo vremena kako bi locirao točno mjesto lokalnog optimuma u području konvergacije. Kombinacija genetskog algoritma i metoda lokalne pretrage može ubrzati pretragu za točnom lokacijom globalnog optimumom. U takvom hibridu korištenje lokalne pretrage, nad rješenjima usmjerenim genetskim algoritmom prema najviše obećavajućim područjima, može precizno konvergirati prema globalnom optimumu. Vrijeme potrebno za pronalazak globalnog optimuma može se dodatno skratiti ukoliko se uz metode lokalne pretrage koristi i lokalno znanje, kako bi se ubrzalo lociranje najobećavajućih područja pretrage.
Neispravan odabir parametra algoritma, zbog utjecaja na omjer globalnog i lokalnog pretraživanja, može predstavljati dodatno ograničenje za algoritam. Ovisno o odabranim parametrima algoritam može biti efektivan u pronalasku optimalnog rješenja, ili ograničen na pod-optimalna rješenja. Odabir dobrih parametara može biti vremenski vrlo zahtjevan problem. Korištenje krutih konstantnih kontrolnih parametara u sukobu je s evolucijskim principima genetskih algoritama, te se zato koriste dodatne tehnike pretrage kako bi se parametri podešavali dok je pretraga u tijeku.
2.3 Motivacija
Kao što je sugerirano u uvodu, vrlo je efikasno kombinirati evolucijsku tehniku s lokalnom pretragom koja popravlja pojedino rješenje. U ovom potpoglavlju dan je pregled nekih od teoretskih i praktičnih motiva za hibridizaciju [13].
- Mnogi se složeni problemi mogu rastaviti na manje složene probleme za koje možda već postoje optimalni postupci ili vrlo dobre heuristike. Zato je smisleno koristi najprikladniji postupak za rješavanje pojedinog potproblema. Poznati postupci mogu se ugraditi u algoritam kao lokala pretraga ili se mogu koristi u kombinaciji s hibridnim genetskim algoritmom kao predprocesori ili postprocesori dobivenih rezultata.
- Uspješne i efektivne opće ("crna kutija") tehnike ne postoje. To podupire rastući broj empirijskih dokaza te neki teoretski rezultati kao što je npr. Nema-Besplatnog-Ručka teorem [3][12]. Iz perspektive evolucijskog računarstva to implicira da sami EA nisu ultimativno rješenje globalnog pretraživanja. Nemoguće je imati algoritam koji je i generalan i dobar. Princip očuvanja kompetencije upućuje: što je algoritam bolji pri rješavanju jedne vrste problema to je gori pri rješavanju druge vrste problema. I empirijski rezultati ukazuju da kvaliteta rješenja ovisi o ugrađenoj količini znanja o domeni problema. Teško skupljeno znanje u obliku heuristika ili optimalnih postupaka treba iskoristiti pri dizajniranju evolucijskog postupka. Hibridni algoritam često ima bolja svojstva nego pojedini algoritam od kojeg je hibrid sastavljen.
- Iako su evolucijski algoritmi dobri u brzom identificiranju dobrih područja za istraživanje (engl. exploration), često su manje sposobni u poboljšavanju rješenja koje je skoro optimalno (engl. exploitation). Razlog je u tome što se mutacija gena provodi na slučajan način. Zato hibridi provode bolju pretragu, koristeći sistematičniji pristup u blizini dobrog rješenja.
- U praksi mnoštvo problema ima ugrađena domenska ograničenja, čineći većinu generiranih rješenja neispravnim. U takvim situacijama se lokalna pretraga može koristiti kao postupak popravljanja rješenja dobivenog genetskim operatorima. Takav pristup je često mnogo jednostavniji nego pokušati pronaći specijalizirane zapise rješenja i validne genetske operatore koji će garantirati ispravnost svih potomaka.
- Dawkinova ideja memea je česta motivacija za hibridizaciju. Memei se mogu vidjeti kao jedinice "kulturološkog prijenosa informacija", kao što su geni jedinice biološkog prijenosa informacija. Memei se odabiri za repliciranje ovisno o dodijeljenoj korisnosti ili popularnosti, te se kopiraju i prenose međukomunikacijom jedinki. Pojedina jedinka iz populacije sastoji se od gena i memea, pri čemu su memei odgovorni za lokalno poboljšanje jedinke.
2.4 Algoritam
U ovom potpoglavlju dana su dva pseudokoda hibridnog genetskog algoritma uz njihovu analizu. Prvi pseudokod je sastavljen od pojedinih pseudokodova koji se u sličnom obliku mogu pronaći u [1]. Drugi pseudokod je jednostavniji te je preuzet iz [13]. U potpoglavlju "Dodatna razmatranja" dana su razmatranja koja se nadovezuju na drugi pseudokod.
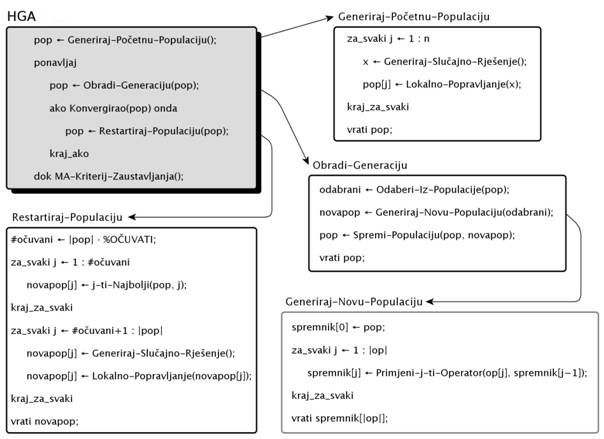
Slika 2.1: Pseudokod hibridnog genetskog algoritma
Na slici 2.1 prikazan je pseudokod hibridnog genetskog algoritma. Algoritam inicijalizira populaciju slučajnim rješenjima (jedinkama) koja se odmah popravljaju lokalnom pretragom. Također je smisleno inicijalizirati populaciju jedinkama koje su dobivene prijašnjim pokretanjem algoritma ili kombiniranjem novih i starih jedinki. Kombiniranje novih i starih jedinki koristi se pri Restartiraj-Populaciju. Ukoliko populacija previše konvergira prema kriteriju koji definira metoda Konvergirao, populacija se restartira tako da se ![]() najbolji dio populacije očuva, a ostali
dio populacije zamjeni s novim slučajno stvorenim (i popravljenim lokalnom pretragom) jedinkama.
najbolji dio populacije očuva, a ostali
dio populacije zamjeni s novim slučajno stvorenim (i popravljenim lokalnom pretragom) jedinkama.
Pojedina obrada generacije jedinki opisana je metodom Obradi-Generaciju. Ta metoda predstavlja samu srž algoritma te se izvodi većinu vremena. Prvo se napravi selekcija odabirom boljih jedinki iz populacije, zatim se primjenom operatora generira nova populacija, te se stara i nova populacija kombinira u novu populaciju. Primjena operatora opisana je u metodi Generiraj-Novu-Populaciju koja se generički odnosi prema svim operatorima. Skup operatora koji se provodi nad populacijom kombinira operatore koji se odnose na jednu jedinku (npr. mutacija), te operatore koji se odnose na više jedini (npr. križanje). Operator lokalne pretrage (ponekad više od jednog operatora) može se primjenjivati na pojedinu jedinku (unaran operator), ili na skup jedinki odjednom – omogućavajući međusobnu izmjenu memea. Osim križanje i mutacije u ovakav se model algoritma lagano uvode i dodatni genetski operatori.
INICIJALIZIRAJ populaciju;
EVALUIRAJ pojedinu jedinku;
Ponavljaj dok ( UVJET PREKIDA nije zadovoljen )
ODABERI roditelje;
KRIŽAJ kako bi stvorio potomke;
EVALUIRAJ potomke;
POPRAVI potomke pomoću Lokalne Pretrage;
MUTIRAJ potomke;
EVALUIRAJ potomke;
POPRAVI potomke pomoću Lokalne Pretrage;
ODABERI jedinke za sljedeću generaciju;
kraj ponavljanja
Slika 2.2: Pseudokod hibridnog genetskog algoritma
U pseudokodu sa slike 2.2 jedinke se dva puta popravljaju pomoću lokalne pretrage. Jedinke nastaju križanjem roditelja, zatim se evaluiraju, te popravljaju. Nakon prvog popravljanja provodi se mutacija nakon koje slijedi još jednom evaluiranje i popravljanje.
Ponekad je uobičajeno evaluiranje napraviti nakon drugog popravljanja kako bi se pri odabiru za sljedeću generaciju koristili rezultati dobiveni nakon druge evaluacije. Također je uobičajeno imati i samo jedan ciklus popravljanja, bilo između križanja i mutacija, bilo nakon mutacije. Ukoliko se koristi više popravljanja poželjno je primijeniti različite algoritme lokalne pretrage.
2.4.1 Dodatna razmatranja
Lamarckianov i Baldwinov postupak:
U navedenom pseudokodu pretpostavlja se da lokalna pretraga zamjenjuje jedinku koju obrađuje s boljim susjedom. U hibridnom genetskom algoritmu lokalnu pretragu može se smatrati fazom popravljanja ili fazom učenja unutar pojedine generacije. Postavlja se pitanje treba li
naučene promjene prihvatiti te promijeniti jedinku ili jedinku ostaviti nepromijenjenu ali ju nagraditi dodatnom dobrotom. Rasprava o tome može li jedinka naučena svojstva prenijeti u nasljedstvo vodila se u devetnaestom stoljeću, a Lamarck je zagovarao stajalište da je takav prenos znanja moguć
[16]. Baldwinov postupak (nazvan prema James Mark Baldwinu) sugerira mehanizam kojim se evolucijski napredak može usmjeriti prema favoriziranim adaptacijama i bez genetskog prijenosa naučenog znanja na potomke. Iako moderne genetske teorije čvrsto brane Baldwinov pogled, hibridni genetski algoritam može se implementirati tako da koristi Lamarckianovu ili Baldwinovu shemu nasljeđivanja. HGA se naziva ![]() ukoliko rezultati lokalne pretrage zamjenjuju jedinku u populaciji, a
ukoliko rezultati lokalne pretrage zamjenjuju jedinku u populaciji, a ![]() ako se originalna jedinka zadrži, ali joj dobrota odgovara rezultatima lokalne pretrage. (Baldwinov hibridni genetski algoritam, za razliku od Lamarckianovog, koristi lokalnu pretragu kako bi promijenio dobrotu jedinke, ali ne i njen genotip.)
ako se originalna jedinka zadrži, ali joj dobrota odgovara rezultatima lokalne pretrage. (Baldwinov hibridni genetski algoritam, za razliku od Lamarckianovog, koristi lokalnu pretragu kako bi promijenio dobrotu jedinke, ali ne i njen genotip.)
Baldwinistički pristup uvažuje činjenicu da se u prirodi genotip jedinke mijenja samo prilikom njenog nastanka, te se ne može promijeniti kasnije u životu jedinke. Ipak, život jedinke, a ne samo njen genotip, određuje njenu dobrotu, pa jedinka unatoč istom genotipu pod različitim utjecajima (lokalna pretraga) može razviti različitu dobrotu.
Razlog zašto se u prirodi genotip mijenja samo prilikom nastanak jedinke može se tumačiti nepostojanjem adekvatnog mehanizma u prirodi kojim bi jedinka sinkronizirano u svim stanicama tijela napravila istu promjenu genetskog materijala. Ipak, računala nemaju taj problem te mogu mijenjati genotip jedinke i tijekom života jedinke (Lamarckianov algoritam), što i dalje ne znači da je dobro raditi nešto što se ne događa prirodi. (Mijenjanjem jedinke za vrijeme lokalne pretrage uništavamo lošije gene, te stvaramo bolje gene. Budući da općenito postoji više loših nego dobrih gena, lokalnom pretragom smanjujemo genetsku raznolikost unutar populacije!)
U praksi se često koristi ili Lamarckianov pristup ili kombinirani pristup u kojem se koristi popravljena dobrota, a jedinka biva zamijenjena s određenom vjerojatnošću.
Očuvanje raznolikosti:
Problem prerane konvergacije, pri čemu populacija konvergira oko nekog suboptimalnog rješenja, može biti posebno problematičan za hibridni genetski algoritam. Ukoliko se lokalna pretraga provodi sve dok obrađivano rješenje ne završi u lokalnom optimumu, može doći do gubitka raznolikosti unutar populacije, osim ako se stalo iznova ne prolaze novi lokalni optimumi. Alternativno, čak i ako se lokalna pretraga prekida prije nego obrađivano rješenje u lokalnom optimumu, ukoliko velik dio područja pretrage gravitira prema nekom suboptimalnom rješenju, brzo će cijela populacija konvergirati. Razvijen je niz pristupa kako bi se suprotstavilo tom problemu:
▪ Pri inicijaliziranju populacije poznatim dobrim rješenjima može se koristiti samo relativno mali dio tih rješenja.
▪ Može se lokalnu pretragu primijeniti samo na mali dio populacije (tako da ostatak populacije ostane raznolik).
▪ Može se koristiti operatore križanja koji su dizajnirani da očuvaju raznolikost.
▪ Može se koristiti različite lokalne pretrage pri čemu svaka vidi drukčije područje pretrage s drukčijim lokalnim optimumima (lokalne pretrage mijenjaju rješenje u različitom smjeru).
▪ Može se modificirati operator selekcije tako da izbjegne duplikate.
▪ Može se modificirati operator selekcije ili operator prihvaćanja jedinke za lokalnu pretragu tako da koristi Boltzmannovu metodu kako bi očuvao raznolikost. Kad je populacija raznolika prihvatimo samo poboljšanja, a kad je konvergirana prihvatimo i bolja i gora rješenja.
Može se pisati:
|
|
|
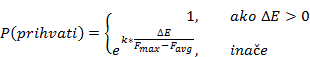
Pri čemu je ![]() normalizirana konstanta, te pretpostavljamo maksimizacijski problem,
normalizirana konstanta, te pretpostavljamo maksimizacijski problem, ![]() .
.
Izbor operatora:
Pri dizajniranju hibridnog genetskog algoritma vrlo je važan dobar izbor operatora pomicanja pri lokalnoj pretrazi (ili odabir dobre heuristike popravljanja jedinke), tj. način na koji se istražuje skup susjednih točaka pri potrazi za boljim rješenjem. Kako bi se reducirala dužina izvođenja algoritma potrebno je odabrati metodu lokalne pretrage čiji operator pomicanja nije korišten u sklopu križanja i mutacije. Optimalan izbor operatora treba uključivati informacije iz domene problema koji rješava, te dodatno može dinamički ovisiti o stanju pretrage.
2.4.2 Teorem "Nema besplatnog ručka"
Prema "Nema besplatnog ručka " teoremu, čiji su autori David Wolpert i William G. Macready, u vezi problema optimizacije treba reći da nema besplatnog ručka (engl. no free lunch) [14]. U metafori "nema besplatnog ručka", svaki ![]() (algoritam) ima
(algoritam) ima ![]() koji povezuje svako
koji povezuje svako ![]() (problem) sa
(problem) sa ![]() (svojstvima algoritma prilikom rješavanja problema). Meniji raznih restorana su isti osim u jednom pogledu – cijene su izmiješane. Za posjetitelja restorana koji će s jednakom vjerojatnošću naručiti bilo koje jelo, prosječna cijena ručka ne ovisi o odabiru restorana. No, posjetitelj koji je spreman naručiti neko od jela koja mu se sviđaju, pažljivim biranjem restorana može uštedjeti novce. Dakle, poboljšavanje performansi prilikom rješavanja problema ovisi o korištenju poznatih informacija kako bi odgovarajuće povezali algoritme s problemima.
(svojstvima algoritma prilikom rješavanja problema). Meniji raznih restorana su isti osim u jednom pogledu – cijene su izmiješane. Za posjetitelja restorana koji će s jednakom vjerojatnošću naručiti bilo koje jelo, prosječna cijena ručka ne ovisi o odabiru restorana. No, posjetitelj koji je spreman naručiti neko od jela koja mu se sviđaju, pažljivim biranjem restorana može uštedjeti novce. Dakle, poboljšavanje performansi prilikom rješavanja problema ovisi o korištenju poznatih informacija kako bi odgovarajuće povezali algoritme s problemima.
Drugim riječima, "nema besplatnog ručka" u potrazi ako i samo ako je distribucija funkcije cilja invarijantna na permutacije prostora kandidata rješenja. Ovaj uvjet nije previše točan u praksi, ali "(skoro) nema besplatnog ručka" teorem ukazuje da uvjet otprilike vrijedi [12].
Određeni računarski problemi rješavaju se traženjem dobrog rješenja u prostoru potencijalnih rješenja. Za određeni problem, različiti algoritmi pretrage mogu postići različite rezultate, ali s obzirom na sve probleme, oni se ne razlikuju. Iz toga slijedi da algoritam koji postiže superiorne rezultate nad određenim problemom mora postići lošije rezultate na nekom drugom problemu. U tom smislu "nema besplatnog ručka" u pretrazi.
"No free lunch" teorem, kako su naveli Wolpert i Macready, tvrdi da su "bilo koja dva algoritma ekvivalentna kad se njihove performanse usrednje preko svih mogućih problema". Rezultati "No free lunch" teorema pokazuju da pridruživanje odgovarajućeg algoritama pojedinom problemu daje bolje prosječne rezultate, nego korištenje istog algoritma za sve probleme.
Originalan "no free lunch" teorem tvrdi da za bilo koji par algoritama ![]() i
i ![]() vrijedi:
vrijedi:
|
|
|
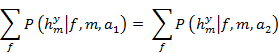
Ukratko, kad su sve funkcije ![]() jednako vjerojatne, vjerojatnost opažanja proizvoljnog slijeda od
jednako vjerojatne, vjerojatnost opažanja proizvoljnog slijeda od ![]() vrijednosti tijekom pretrage ne ovisi o algoritmu.
vrijednosti tijekom pretrage ne ovisi o algoritmu.
2.5 Genetski operatori
U ovom potpoglavlju dan je kratak osvrt na operatore mutacije i križanja.
Dobar odabir genetskih operatora može znatno utjecati na efikasnost algoritma. Razmotrimo operator mutacije. Mutaciju (barem u području genetskih algoritama) uobičajeno ima cilj stalno unositi u populaciju nove genetske materijale, ali u malim količinama (inače bi usmjerena pretraga degradirala na slučajnu šetnju kroz prostor rješenja). Mutacija mora generirati nova rješenja djelomičnom modifikacijom postojećih. Modifikacija može biti nasumična (što je čest slučaj), ili može baratati informacijama vezanim za domenu problema, te raditi promjene koje su očekivano korisne i usmjeruju pretragu prema boljim područjima [1]. Nema previše generalnih savjeta za konstrukciju dobrog operatora mutacije.
Operator križanja u širom smislu ne mora predstavljati jednostavno kopiranje genoma roditelja djetetu. Roditelj može na određen način utjecat na stvaranje djeteta bez da dijete i roditelj dijele zajedničke genome. Križanje se može tumačiti i kao mutaciju (zadanog intenziteta) jednog roditelja u smjeru drugog roditelja (ili skupa roditelja).
Razmotrimo svojstava koja operator križanja može imati [6]. Za operator križanja kažemo da je poštivajući (engl. respectful) ako stvara potomke koji sadrže sve značajke koje su zajedničke u oba roditelja. Ukoliko su roditelji identični poštivajući operator križanja mora stvoriti dijete jednako roditeljima (to svojstvo zovemo čistoća (engl. purity) i može se postići i kad operator križanja nije poštivajući). Za operator križanja kažemo da je valjano uređujući (engl. properly assorting) ako može generirati potomke koji sadrže bilo koju kombinaciju kompatibilnih značajki preuzetih od roditelja. Konačno, operator je prenoseći (engl. transmitting) ako je svaka značajka pronađena u potomku prisutna u barem jednom roditelju. Prenoseći operator križanja ne može uvesti novu informaciju u potomku (što se tada prepušta operatoru mutacije). Zato se za neprenoseći operator kaže da uvodi implicitnu mutaciju. Za operator križanja koji ne koristi nikakve dodatne informacije koje nisu sadržane u roditeljima kažemo da je slijep (engl. blind). Slijep operator ne koristi znanje o domeni problema koji rješava. Tipičan slijep operator je npr. uniformno križanje. Za operatore križanja koji koriste znanje o problemu koji rješavaju kaže se da su heuristički ili hibridni (takvi operatori se često koriste u hibridnim genetskim algoritmima).
Operator križanja preferirano treba biti hibridni i poštivajući, dok su ostala svojstva poželjna ovisno o domeni gdje se koriste (npr. neprenoseći operator je poželjan ukoliko je teško uvesti neki drugi smisleni oblik mutacije).
3. Problem optimalnog grupiranja
3.1 Problem
U radu rješava se problem optimalnog grupiranja ljudi. Cilj je grupirati ljude u određen broj grupa tako da ljudi budu što zadovoljniji rasporedom.
3.1.1 Opis problema
Sve osobe mogu izraziti koliko su zadovoljne ako ih se rasporedi tako da budu s nekom osobom u istoj grupi. Pojedina osoba može za svaku osobu definirati koliko želi ili ne želi biti s tom osobom u grupi tako što drugim osobama dodjeljuje težinske faktore. Ukoliko je dodijeljeni faktor pozitivan tada osoba želi biti s tom osobom u grupi, a ukoliko je faktor negativan osoba ne želi biti s tom osobom svrstana u istu grupu. Apsolutni iznos faktora označava intenzitet želje. Veličina brojeva (faktora) koje osoba dodjeljuje drugim osobama mogu biti proizvoljne veličine jer se za svaku osobu definira njena jačina glasa. Jačina glasa pojedine osobe predstavlja bitnost želja koje pojedina osoba izražava. Pri izračunu se svi faktori pojedine osobe linearno skaliraju tako da im suma apsolutnih vrijednosti bude jednaka jačini glasa te osobe. Budući da se koristi apsolutna vrijednost faktora, osoba može sama odabrati način iskazivanja želja (nekoj osobi može više odgovarati ukoliko definira s kim ne želi biti u grupi, dok je nekoj drugoj osobi možda važnije moći iskazati s kime želi biti u grupi).
Osim osoba i njihovim prioriteta definira se i broj grupa u koje osobe treba rasporediti (grupe mogu biti npr. hotelske sobe ili
momčadi za sportske igre). Za svaku grupu se zasebno definira koliko minimalno i koliko maksimalno osoba smije biti u toj grupi (ukoliko broj ljudi u grupi nije bitan može se postaviti minimum na ![]() a maksimum na ukupan broj ljudi).
a maksimum na ukupan broj ljudi).
3.1.2 Jednostavan primjer
Prikažimo jednostavan primjer problema koji se rješava:
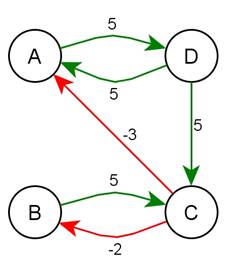
Slika 3.1: Jednostavan primjer
Raspoređujemo 4 osobe: osoba A, osoba B, osoba C i osoba D (slika 3.1).
(U primjeru se radi jednostavnosti koriste cjelobrojne vrijednosti.)
Neka osobe A, B i C imaju jačinu glasa 5, a osoba D ima jačinu glasa 10.
- Osoba A želi biti s osobom D (faktor 5).
- Osoba B želi biti s osobom C (faktor 5).
- Osoba C ne želi biti s osobom A (faktor -3) niti s osobom B(faktor -2).
- Osoba D želi biti s osobom A(faktor 5) i osobom C(faktor 5).
Osobe treba rasporediti u dvije grupe. U jednu grupu treba staviti 1 do 2 osobe, a u drugu 2 do 3 osobe.
Ukoliko grupiramo osobe A i D u jednu grupu, a osobe B i C u drugu tada je ukupna suma kvalitete grupiranja jednaka 5![]() 5
5![]() 5
5![]() 2
2 ![]() 13. Slično tome, grupiranje osoba D i C te A i B ima kvalitetu 5, grupiranje osoba A, B i C, te zasebno D ima kvalitetu 0, grupiranje osoba A,
C i D te zasebno B ima kvalitetu 12, itd.
13. Slično tome, grupiranje osoba D i C te A i B ima kvalitetu 5, grupiranje osoba A, B i C, te zasebno D ima kvalitetu 0, grupiranje osoba A,
C i D te zasebno B ima kvalitetu 12, itd.
Ista osoba može miješati i pozitivne i negativne faktore, što u primjeru nije pokazano.
Problem koji se rješava mora se moći zapisati u formatiranom obliku kako bi ga program mogao razumjeti. Opisani jednostavan problem s 4 osobe i 2 grupe se zapisuje kako je prikazano na slici 3.2.
4
1 4 5
1 3 5
2 1 -3 2 -2
2 1 5 3 5
5 5 5 10
2
1 2
2 3
Slika 3.2: Zapis problema
Prvi red predstavlja broj osoba. Sljedeća četiri retka opisuje redom želje osoba (osoba A je osoba 1, osoba B je osoba 2, itd.). Prvi broj u pojedinom retku (crveno) je broj želja, zatim slijedi toliko parova brojeva, pri čemu tamno plava brojka govori o kojoj osobi se radi (1-indeksirano), dok je crna brojka faktor. Nakon opisa želja osoba slijedi redak s po jedinim brojem za svaku osobu. Brojevi redom za svaku osobu iskazuje njenu jačinu glasa (kad apsolutna suma brojeva u opisu želja osobe ne bi bila jednaka jačini glasa osobe, faktori bi se linearno skalirali da odgovaraju jačini glasa). Sljedeći redak opisuje broj grupa. Nakon toga slijedi za svaku grupu po jedan redak s dva broja. Prvi broj je minimalan broj osoba u grupi, dok je drugi broj u retku maksimalan broj osoba u grupi.
3.2 Algoritam
Za rješavanje problema optimalnog grupiranja korišten je hibridni genetski algoritam koji je opisan u ovom poglavlju.
Ukratko o algoritmu:
- Genetski algoritam je eliminacijski.
- Selekcija je implementirana kao modificirani rullet-wheel (pojašnjeno u nastavku).
- Algoritam podržava elitizam najbolje jedinke.
- Hibridni genetski algoritam se može provoditi po Baldwinovom ili po Lamarckianovom postupku. (Baldwinov postupak heuristikama mijenja samo dobrotu jedinke, dok Lamarckianov postupak mijenja i dobrotu i genotip jedinke.)
- Algoritmu se može podešavati tijek izvođenja i način mijenjanja jedinki pri hibridizaciji, te se može birati implementacija svih korištenih genetskih operatora.
- Pri provođenju algoritma jednom iteracijom smatra se jedno križanje, te heuristike i mutacije koje slijede. Unutar jedne iteracije prvo se provodi selekcija, zatim križanje, opcionalno heuristika, mutacija te heuristika.
3.2.1 Selekcija
Selekcija se provodi pomoću modificiranog roulette-wheel postupka. Pri jednostavnoj selekciji (engl. roulette-wheel) jedinkama se dodjeljuje dio ruletnog kola, te je veličina dijela ruletnog kola linearno proporcionalna vjerojatnost da se pojedina jedinka odabere za selekciju.
Jedinkama se može dodijeliti dio ruletnog kola proporcionalno njihovim dobrotama ili proporcionalno poretku u sortiranom nizu jedinki. Pri računanju dijela ruletnog kola proporcionalno dobroti jedinke obično se sve dobrote jedinki skaliraju na interval od ![]() do
do ![]() tako da najbolja jedinka ima skaliranu dobrotu
tako da najbolja jedinka ima skaliranu dobrotu ![]() , najgora jedinka skaliranu dobrotu
, najgora jedinka skaliranu dobrotu ![]() , a jedinke između skaliranu dobrotu
, a jedinke između skaliranu dobrotu ![]() .
.
|
|
|
Takav pristup izračunu udjela ruletnog kola ima dva problema:
Prvi problem stvara velika varijacija u dobroti najgore jedinke. Nakon što dobrota populacije poraste, najgora jedinka, često nastala lošom mutacijom, stvara velike oscilacije dobrote te joj vrijednost znatno odskače od vrijednosti dobrote ostatke populacije. Npr. ukoliko ![]() jedinki poprime vrijednost dobrote između
jedinki poprime vrijednost dobrote između ![]() i
i ![]() , najgora jedinka može poprimiti dobrotu
, najgora jedinka može poprimiti dobrotu ![]() , te time znatno poremetiti kvalitetu skaliranja jedinki jer se nakon skaliranja dobre jedinke čine približno jednako dobrima te pretraga počinje biti slijepa.
, te time znatno poremetiti kvalitetu skaliranja jedinki jer se nakon skaliranja dobre jedinke čine približno jednako dobrima te pretraga počinje biti slijepa.
Drugi problem pri skaliranju jedinki stvara udaljenost od globalno najbolje potencijalne dobrote. Pretpostavimo da jedinke mogu postići maksimalnu dobrotu iznosa ![]() , te u populaciji uspoređujemo jedinku
, te u populaciji uspoređujemo jedinku ![]() s kvalitetom
s kvalitetom ![]() i jedinku
i jedinku ![]() s kvalitetom
s kvalitetom ![]() , dok je prosječna dobrota populacije
, dok je prosječna dobrota populacije ![]() . Nema smisla reći da je jedinka
. Nema smisla reći da je jedinka ![]() za
za ![]() bolja od jedinke
bolja od jedinke ![]() (situacija kada jedinka
(situacija kada jedinka ![]() ima dobrotu
ima dobrotu ![]() a jedinka
a jedinka ![]() dobrotu
dobrotu ![]() postaje još besmislenija). Više bi imalo smisla reći da jedinka
postaje još besmislenija). Više bi imalo smisla reći da jedinka ![]() ima duplo veću dobrotu od jedinke
ima duplo veću dobrotu od jedinke ![]() jer je duplo bliže najvećem mogućem iznosu dobrote.
jer je duplo bliže najvećem mogućem iznosu dobrote.
Drugi način određivanja udjela ruletnog kola koji pripada pojedinoj jedinki jest sortirati jedinke po iznosu dobrote te svakoj jedinki dodijeliti udio ruletnog kola proporcionalan mjestu jedinke u sortiranom poretku. Ovakav pristup rješava dva prije spomenuta problema sa skaliranjem dobrote, ali uvodi novi problem neiskorištavanja dostupnih informacija o iznosima dobrote jedinki. Selekcija donosi odluku na temelju manje informacije nego pri skaliranju dobrote. Ukoliko raspolažemo s informacijama o iznosu dobrote pojedine jedinke, a ne samo njihovom relativnom poretku, treba tu informaciju uključiti u proces donošenja odluke, kako bi selekcija bila informiranija (time kvalitetnija).
Implementirano rješenje koristi hibridni oblik selekcije koji kombinira dva gore navedena pristupa određivanja udjela ruletnog kola pojedine jedinke:
Za svaku jedinku odredimo položaj u sortiranom poretku te na temelju tih vrijednosti stvorimo prvo ruletno kolo. Nakon toga stvorimo drugo ruletno kolo tako da skaliramo dobrotu na iznos
od ![]() do
do ![]() ali pri tome ne koristimo iznos dobrote najgore jedinke nego ga sami procijenimo:
ali pri tome ne koristimo iznos dobrote najgore jedinke nego ga sami procijenimo:
|
|
|
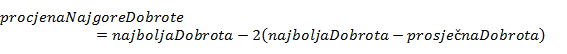
te skaliramo jedinke prema formuli:
|
|
|
Konačne udjele jedinki u ruletnom kolu dobijemo kombiniranjem oba ruletna kola tako da udio u konačnom ruletnom kolu bude jednak aritmetičkom prosjeku udjela u prvom i udjela u drugom ruletnom kolu.
Takvim oblikovanjem selekcije rješavamo ranije spomenute problem pri izgradnji ruletnog kola.
Pri izračunu iznosa kazne za pojedinu jedinku (ukoliko želimo selektirati lošu jedinku, a ne dobru) računamo ![]() , budući da je dobrota svih jedinki unutar intervala od
, budući da je dobrota svih jedinki unutar intervala od ![]() do
do ![]() .
.
3.2.2 Križanja
Algoritam raspolaže s tri različita načina križanja jedinki. Svako križanje prima dvije jedinke koje su roditelji, te stvara dvoje djece.
Prvo križanje uniformno odabire iz kojeg roditelja odabrati grupu osoba, te preuzima grupu iz jednog roditelja u prvo dijete, a iz drugog roditelja u drugo dijete. Nakon toga se dodato provede popravljanje djece tako da jedinke budu konzistentne s ograničenjima koje nameće problem koji se rješava (može se dogoditi da se neke osobe rasporede u dvije grupe, a neke uopće ne rasporede.)
Drugo križanje uniformno raspoređuje osobe (ne grupe) tako da se svaka osoba rasporedi u prvom djetetu u istu grupu u kojoj je u jednom roditelju, a u drugom djetetu u istu grupu u kojoj je u drugom roditelju. Nakon toga se provodi popravljanje djece tako da jedinke budu konzistentne s problemom koji rješavaju.
Treće križanje u oba djeteta prenose sve osobe koje su u oba roditelja raspoređene u iste grupe (zajednički geni roditelja), te se ostale osobe slučajno rasporede. Ovo križanje najviše održava zajednička svojstva roditelja, ali također uzrokuje ubrzanu konvergaciju populacije pa je preporučljivo uz ovo križanje povećati veličinu populacije i/ili vjerojatnost mutacije.
I u prvom i drugom križanju provodi se dodatno popravljanje jedinki (također i u prve dvije mutacije). Popravljanje jedinke mijenja jedinku tako do bude konzistentna s ograničenjima koje nameće problem (svaka jedinka se mora rasporediti u točno jednu grupu te broj osoba u svakoj grupi mora biti unutar dozvoljenog raspona za tu grupu). Pritom se pokušava što manje promijeniti jedinku (očuvati dobar genetski materijal).
Jedinka se popravlja tako da se prvo za svaku osobu koja se više puta pojavljuje po grupama slučajno odabere grupa u kojoj osoba ostane, dok se iz ostalih grupa ukloni. Zatim se stvori skup neraspoređenih osoba, iz kojeg će se osobe kasnije rasporediti po grupama. U skup neraspoređenih osoba se dodaju sve osobe koje nisu u niti jednoj grupi, te se iz svih grupa u kojim ima previše osoba slučajno odaberu osobe koje se uklone i dodaju u skup neraspoređenih osoba. Nakon toga se računa ima li u skupu neraspoređenih osoba dovoljno osoba da se popune minimalni zahtjevi grupa u kojima ima premalo osoba. U skup se dodaju osobe dok ih ne bude dovoljno (slučajno se vade osobe iz grupa u kojima se vađenjem broj osoba neće smanjiti ispod dopuštenog broja). Nakon toga se sve osobe iz skupa neraspoređenih osoba slučajnim redoslijedom raspoređuju po grupama u kojima nedostaje osoba. Zatim se sve preostale osobe iz skupa slučajnim redoslijedom raspoređuju po grupama pazeći pritom da se u pojedinu grupu ne stavi više osoba nego je dopušteno.
Ovaj pomalo kompliciran postupak vrlo je pažljivo implementiran kao ne bi nimalo mijenjao valjane jedinke, a minimalno promijenio neispravne jedinke.
3.2.3 Mutacija
Algoritam raspolaže s tri načina mutiranja jedinke. Svaka mutacija promjeni jedinku na drukčiji način uzimajući u obzir vjerojatnost mutacije koju je korisnik naveo. Pritom je vjerojatnost mutacije udio genetskog materijala jedinke koji će se očekivano promijeniti (npr. ako problem raspoređuje ![]() jedinki, a vjerojatnost mutacije je
jedinki, a vjerojatnost mutacije je ![]() , onda će se, neovisno o tome koji način mutacije odaberemo, očekivano
, onda će se, neovisno o tome koji način mutacije odaberemo, očekivano ![]() osoba prerasporediti).
osoba prerasporediti).
· Prva mutacija pomiče osobu po osobu u slučajno odabranu grupu, te nakon toga popravi jedinku.
- Druga mutacija pomiče podgrupu osoba (nekoliko osoba koje su dodijeljene u istu grupu) u neku drugu, slučajno odabranu grupu, te zatim popravi jedinku.
- Treća mutacija je najsofisticiranija. Slučajno se odabere određeni broj grupa s dovoljno mnogo osoba raspoređenih u te grupe, te se u svakoj grupi odabere podgrupa jednake veličine. Mutacija zarotira (zamjeni u krug) podgrupe osoba po odabranim grupama. Nakon ove mutacije nema potrebe provoditi popravljanje jedinke jer jedinke ostanu valjana rješenja rješavanog problema.
3.2.4 Heuristika
Algoritam raspolaže s tri različite heuristike pomoću kojih se može provoditi lokalna pretraga za boljim jedinkama. Od te tri verzije prve dvije su jednostavne, dok se treća temelji na sofisticiranom algoritmu.
- Prva heuristika pokušava popraviti jedinku ponavljajući pomicanja slučajno odabrane osobe iz grupe u grupu (pazeći protom da jedinka ostane valjana), dok god se time popravlja dobrota jedinke.
- Druga heuristika pokušava popraviti jedinku mijenjajući grupe kojima pripadaju dvije slučajno odabrane osobe. Ova heuristika ne mora paziti na valjanost jedinke jer broj osoba po pojedinim grupama uvijek ostaje isti.
- Treća heuristika se temelji na razradi problema grupiranja kao grafa kroz koji se pokušava optimirati cijena protoka (minimum cost maximum flow algoritam). Pri svakoj iteraciji heuristike izgrađuje se mreža za protok (engl. flow network) u kojoj se pokušava cikličkim zamjenama povećati dobrota jedinke. Ciklusi zamjena osoba koji povećavaju dobrotu raspodjele osoba po grupama detektiraju se pomoću prilagođene verzije algoritma poništavanja ciklusa (engl. cycle canceling algirithm) [15].
Heuristika u svakoj iteraciji garantirano pronalazi optimalniji raspored ukoliko je to moguće postići zamjenjujući u krug skup osoba koji su odabrani iz podskupa svih grupa, tako da se iz svake grupe se odabire jedna ili nijedna osoba. Odabrane osobe se ciklički zarotiraju tako da se prva odabrana osoba premjesti u grupu u kojoj se nalazi druga odabrana osoba, druga odabrana osoba u grupu u kojoj se nalazi treća odabrana osoba, itd.
Buduću da se u svakoj iteraciji ukupna dobrota jedinke popravi, te budući da znamo
da mora postojati neka maksimalna dobrota koju jedinka može postići (globalni maksimum) – u algoritam je ugrađena minimalna razlika dobrote ![]() (minimalni korak) koju jedinka mora postići u pojedinoj iteraciji – kako bi vrijedilo:
(minimalni korak) koju jedinka mora postići u pojedinoj iteraciji – kako bi vrijedilo:
|
|
|
pri čemu je ![]() jedinka nastala u
jedinka nastala u ![]() -toj iteraciji heuristike, a
-toj iteraciji heuristike, a ![]() dobrota te jedinke. Zato znamo da je uz nizu generiranih
dobrota te jedinke. Zato znamo da je uz nizu generiranih ![]() , funkcija
, funkcija ![]() Lyaponuv funkcija, te je zato garantirano da će pri iteriranju u nekom trenutku vrijediti
Lyaponuv funkcija, te je zato garantirano da će pri iteriranju u nekom trenutku vrijediti ![]() , te će heuristika završiti.
, te će heuristika završiti.
Navedene su tri različite heuristike koje je dobro koristiti zajedno kako bi se pronašao globalni optimum. Objasnimo pomoću primjera zašto je primjenjivanje različitih heuristika iznimno korisno za hibridni genetski algoritam.
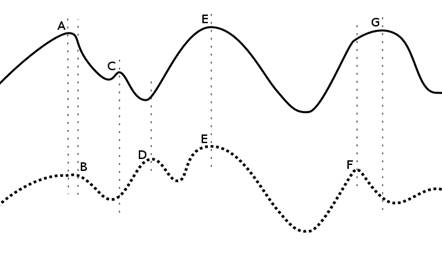
Slika 3.3: Primjena više različitih heuristika
Slika 3.3 prikazuje primjer dvije različite heuristike koje rješavaju isti problem. Domena koju
se optimiraju je zbog jednostavnosti prikazana kao jednodimenzionalna funkcija (možemo zamisliti da se radi o dvije funkcije koje su projekcije nekog višedimenzionalno problema, npr. projekcije dvodimenzionalne domene na koordinatne osi). Prva od dvije heuristike je prikazana punom liniju, dok je druga prikazana točkastom linijom. Obje heuristike traže maksimalnu vrijednost i imaju isti globalni optimum, ali se razlikuju u lokalnim optimumima. Ukoliko npr. Gornja heuristika (puna linija) zapadne u optimumu ![]() , donja heuristika (točkasta linija) će iz te točke pomaknuti rješenje u točku
, donja heuristika (točkasta linija) će iz te točke pomaknuti rješenje u točku ![]() koja je za donju
heuristiku lokalni optimum. Nastavi li gornja heuristika obrađivati rješenje koje je dobila od donje heuristike (točka
koja je za donju
heuristiku lokalni optimum. Nastavi li gornja heuristika obrađivati rješenje koje je dobila od donje heuristike (točka ![]() ), penjajući se po grafu završiti će u globalnom optimumu
), penjajući se po grafu završiti će u globalnom optimumu ![]() (koji dijele obje funkcije).
(koji dijele obje funkcije).
Korištenje više različitih heuristika osigurava bolju raznolikost populacije (jer se populacija optimira u različitim smjerovima), te lakše napuštanje lokalnih optimuma.
3.2.5 Zaustavljanja algoritma
Algoritam se može zaustaviti na tri načina ovisno o želji korisnika.
- nakon određenog, unaprijed definiranog vremena izvršavanja,
- nakon što se provede određen broj iteracija algoritma, ili
- nakon što se određen broj iteracija algoritma dobrota najbolje jedinke ne popravi.
3.3 Programsko ostvarenje
Algoritam je ostvaren u Javi uz pomoć integriranog razvojnog okružja Eclipse 3.7 (za razvoj grafičkog korisničkog sučelja) unutar operacijskog sustava Windows 7, te pomoću integriranog razvojnog okružja NetBeans 7.0.1 (za razvoj svega ostalog) unutar operacijskog sustava openSUSE 11.4. Program se sastoji od 25 klasa raspoređenih unutar dva paketa:
![]() i
i ![]() .
.
Program je vrlo robustan (otporan na neočekivane radnje korisnika) i pruža intuitivno sučelja korisniku.
Pojednostavljeni klasni dijagram paketa ![]() prikazan je na slici 3.4.
prikazan je na slici 3.4.
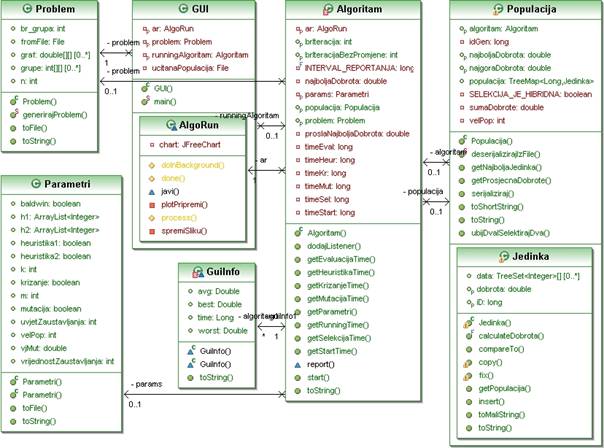
Slika 3.4: Klasni dijagram
Klasa ![]() opisuje problem koji se rješava (osobe i njihove želje, te grupe i njihova ograničenja). Klasa ima statičku metodu za generiranje problema, pomoću koje se mogu stvarati slučajni problemi sa željenim brojem osoba i grupa, te željenim brojem želja osoba. Konstruktor klase prima
opisuje problem koji se rješava (osobe i njihove želje, te grupe i njihova ograničenja). Klasa ima statičku metodu za generiranje problema, pomoću koje se mogu stvarati slučajni problemi sa željenim brojem osoba i grupa, te željenim brojem želja osoba. Konstruktor klase prima ![]() u kojem je zapisan problem, te se iz podataka zapisanih u primljenoj datoteci popunjavaju članovi klase. Klasa također može metodom
u kojem je zapisan problem, te se iz podataka zapisanih u primljenoj datoteci popunjavaju članovi klase. Klasa također može metodom ![]() zapisati svoje stanje u datoteku.
zapisati svoje stanje u datoteku.
Klasa ![]() opisuje parametre s kojima se pokreće algoritam. Parametri se definiraju kroz grafičko sučelje programa, te se mogu zapisati u datoteku pomoću metode
opisuje parametre s kojima se pokreće algoritam. Parametri se definiraju kroz grafičko sučelje programa, te se mogu zapisati u datoteku pomoću metode ![]() i učitati iz datoteke pomoću odgovarajućeg konstruktora klase
i učitati iz datoteke pomoću odgovarajućeg konstruktora klase ![]() . Klasa ima i dodatan konstruktor koji prima vrijednosti za sve članove klase.
. Klasa ima i dodatan konstruktor koji prima vrijednosti za sve članove klase.
Objekte klasa ![]() i
i ![]() stvara klasa
stvara klasa ![]() i prosljeđuje klasi
i prosljeđuje klasi ![]() kako bi algoritam znao koji problem rješava i kojim postupcima.
kako bi algoritam znao koji problem rješava i kojim postupcima.
Klasa ![]() ostvaruje grafičko korisničko sučelje te pokreće radnje koje korisnik zahtijeva. Klasa
ostvaruje grafičko korisničko sučelje te pokreće radnje koje korisnik zahtijeva. Klasa ![]() je odgovorna za pokretanje algoritma, praćenje njegovog napretka i prikazivanje napretka korisniku. Klasa
je odgovorna za pokretanje algoritma, praćenje njegovog napretka i prikazivanje napretka korisniku. Klasa ![]() sadrži javnu unutrašnju klasu
sadrži javnu unutrašnju klasu ![]() koja implementira interface
koja implementira interface ![]() .
. ![]() je zadužen za dretve koji su pokrenute za vrijeme izračunavanja algoritma, te također pruža metodu
je zadužen za dretve koji su pokrenute za vrijeme izračunavanja algoritma, te također pruža metodu ![]() preko koje prima nove informacije o napretku algoritma, i te informacije prosljeđuje klasi
preko koje prima nove informacije o napretku algoritma, i te informacije prosljeđuje klasi ![]() .
. ![]() također ima odgovornost prikazivanja, osvježivanja i pohranjivanja grafa koji se iscrtava pomoću klase
također ima odgovornost prikazivanja, osvježivanja i pohranjivanja grafa koji se iscrtava pomoću klase ![]() dostupne iz vanjske biblioteke
dostupne iz vanjske biblioteke ![]() .
.
Klasa ![]() osim što može upravljati algoritmom pomoću grafičkog sučelja, također ima mogućnost upravljati algoritmom bez korištenja grafičkog sučelja ako kroz komandnu liniju primi argumente koji opisuju put do datoteka za izgradnju objekata klasa
osim što može upravljati algoritmom pomoću grafičkog sučelja, također ima mogućnost upravljati algoritmom bez korištenja grafičkog sučelja ako kroz komandnu liniju primi argumente koji opisuju put do datoteka za izgradnju objekata klasa ![]() i
i ![]() (te opcionalno i
(te opcionalno i ![]() kako bi nastavila algoritam s prije pohranjenom populacijom).
kako bi nastavila algoritam s prije pohranjenom populacijom).
Klasa ![]() provodi HGA na način opisan u primljenom objektu klase
provodi HGA na način opisan u primljenom objektu klase ![]() , te rješava problem opisan u primljenom objektu klase
, te rješava problem opisan u primljenom objektu klase ![]() (konstruktor klase
(konstruktor klase ![]() osim klasa
osim klasa ![]() i
i ![]() također može primiti i
također može primiti i ![]() koji opisuje prije pohranjenu populaciju s kojom treba nastaviti izvođenje algoritma). Za stvaranje objekta klase
koji opisuje prije pohranjenu populaciju s kojom treba nastaviti izvođenje algoritma). Za stvaranje objekta klase ![]() i pokretanje algoritma metodom
i pokretanje algoritma metodom ![]() zadužen je
zadužen je ![]() .
. ![]() stvara željene genetske operatore i primjenjuje ih nad objektom klase
stvara željene genetske operatore i primjenjuje ih nad objektom klase ![]() .
. ![]() također prati uvjete zaustavljanja algoritma i vrijeme koje se potroši na provođenje selekcije, križanja, mutacije, heuristike i izračun dobrote.
također prati uvjete zaustavljanja algoritma i vrijeme koje se potroši na provođenje selekcije, križanja, mutacije, heuristike i izračun dobrote. ![]() pomoću objekata klase
pomoću objekata klase ![]() šalje klasi
šalje klasi ![]() informacije o napretku algoritma i stanju populacije, te dodatno osluškuje je li korisnik naredio prijevremeno prekidanje algoritma. Klasa
informacije o napretku algoritma i stanju populacije, te dodatno osluškuje je li korisnik naredio prijevremeno prekidanje algoritma. Klasa ![]() je zadužena, nakon što
je zadužena, nakon što ![]() završi izvođenje, serijalizirati populaciju i rezultate u odgovarajuće datoteke.
završi izvođenje, serijalizirati populaciju i rezultate u odgovarajuće datoteke.
Klasa ![]() je odgovorna brinuti se o stanju populacije, provoditi selekciju nad populacijom, voditi statistiku o stanju populacije, te generirati jedinstvene
je odgovorna brinuti se o stanju populacije, provoditi selekciju nad populacijom, voditi statistiku o stanju populacije, te generirati jedinstvene ![]() -ove pomoću kojih se jedinke mogu međusobno razlikovati. Klasa
-ove pomoću kojih se jedinke mogu međusobno razlikovati. Klasa ![]() implementira interface
implementira interface ![]() te se osim konstruktorom koji stvara novu populaciju (generira potreban broj jedinki i računa statistiku), može stvorit i deserijalizacijom iz datoteke (metoda
te se osim konstruktorom koji stvara novu populaciju (generira potreban broj jedinki i računa statistiku), može stvorit i deserijalizacijom iz datoteke (metoda ![]() ) u koju je populacija prije serijalizirana (pomoću metode
) u koju je populacija prije serijalizirana (pomoću metode ![]() ). Populacija je usko povezana sa svojom javnom unutrašnjom klasom
). Populacija je usko povezana sa svojom javnom unutrašnjom klasom ![]() .
.
Klasa ![]() se brine o zapisu genotipa jedinke, izračunu dobrote jedinke, kopiranju jedinke i popravljanju jedinke koja nije valjana (metoda
se brine o zapisu genotipa jedinke, izračunu dobrote jedinke, kopiranju jedinke i popravljanju jedinke koja nije valjana (metoda ![]() ).
).
Pojednostavljeni klasni dijagram paketa ![]() prikazan je na slici 3.5.
prikazan je na slici 3.5.
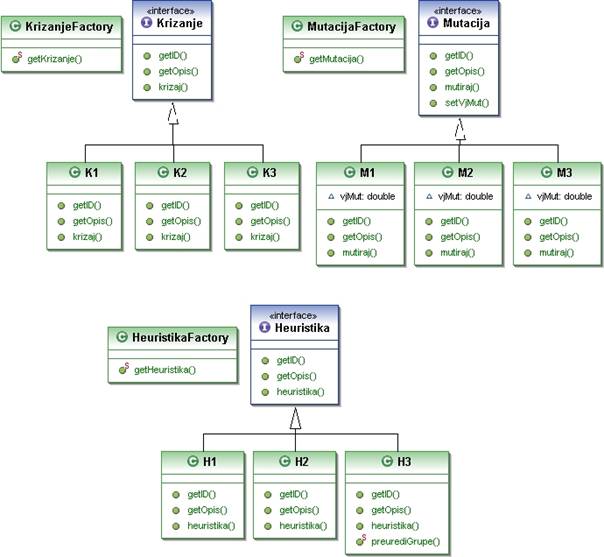
Slika 3.5: Klasni dijagram operatora
Paket sadrži klase koje implementiraju genetske operatore za križanje, mutaciju te heuristike.
Svaki tip operatora stvara se preko statičke metode odgovarajuće ![]() klase koja prima
klase koja prima ![]() genetskog operatora. Svi operatori implementiraju odgovarajući interface. Kod stvaranja objekta tipa
genetskog operatora. Svi operatori implementiraju odgovarajući interface. Kod stvaranja objekta tipa ![]() potrebno je statičkoj metodi klase
potrebno je statičkoj metodi klase ![]() proslijediti i vjerojatnost mutacije koju zatim
proslijediti i vjerojatnost mutacije koju zatim ![]() postavi metodom
postavi metodom ![]() .
.
Svi operatori dijele metodu ![]() pomoću koje
pomoću koje ![]() dohvaća opis operatora, koji se prikazuje na grafičkom sučelju ukoliko korisnik zadrži miš nad pojedinim genetskim operatorom.
dohvaća opis operatora, koji se prikazuje na grafičkom sučelju ukoliko korisnik zadrži miš nad pojedinim genetskim operatorom.
3.3.1 Zapis problema
Prije je ukratko spomenut izgled datoteke koja zapisuje problem koji se rješava. Općeniti izgled datoteke je dan na slici 3.6.
n
k1 o1 f1 o2 f2 ... ok1 fk1
k2 o1 f1 o2 f2 ... ok1 fk2
...
kn o1 f1 o2 f2 ... ok1 fkn
j1 j2 ... jn
g
min1 max1
min2 max2
...
ming maxg
Slika 3.6: Zapis problema
n je broj osoba. Svaka linija koja počinje s ki opisuje osobu i s ki želja opisanih pomoću ki parova brojeva oj i fj, pri čemu je oj osoba s kojom osoba ki želi biti s faktorom fj. ji je jačina glasa osobe i. g je broj grupa. mini i maxi su minimalan i maksimalan broj osoba koji smiju biti u grupi i.
3.3.2 Korištenje programa
Program se pokreće iz jar datoteke (može se pokrenuti izravno ili pomoću komandne linije naredbom "java -jar naziv.jar"). Za pokretanje je potreban instaliran JRE 1.6 ili noviji.
Nakon pokretanja potrebno je učitati problem koji se rješava, prije nego se pokrene algoritam. Problem se učitava pomoću neke od tipki pri vrhu lijevog dijela grafičkog sučelja. Algoritam se pokreće pomoću tipke ![]() . Algoritam, nakon što završi, stvori u
tekućem direktoriju (u kojem je pokrenuta jar datoteka) datoteku s rezultatima, te datoteku s pohranjenim stanjem populacije nakon izvršavanja algoritma.
. Algoritam, nakon što završi, stvori u
tekućem direktoriju (u kojem je pokrenuta jar datoteka) datoteku s rezultatima, te datoteku s pohranjenim stanjem populacije nakon izvršavanja algoritma.
Program se može pokrenuti i bez grafičkog korisničkog sučelja ukoliko mu se kroz komandnu liniju proslijede argumenti koji opisuju put do datoteka koje opisuju parametre (datoteka s rezultatima izvođenja se može koristiti kao datoteka s parametrima) i problem koji se rješava (te opcionalno i put do datoteke s pohranjenom populacijom – ukoliko se želi koristiti prije pohranjena populacija).
Slika 3.7: Grafičko korisničko sučelje
Slika 3.7 prikazuje izgled grafičkog korisničkog sučelja programa. S lijeve strane sučelja, pri vrhu, nalaze se dvije tipke pomoću kojih se može učitati problem koji se rješava ili generirati novi problem (generirani problem se i učita).
S lijeve strane se nalazi okvir unutar kojeg se podešavaju parametri algoritma. Nakon retka s poljem za unos veličine populacije slijede četiri retka koji počinju s kvačicom kojom se odgovarajući redak uključuje u tijek izvođenja algoritma (jedna iteracija algoritma). Prvo se provodi križanje, odgovarajuća kvačica se ne može ukloniti. Provodi se ona inačica križanja koja je označena radiogumbom. Nakon toga se provodi heuristika, ukoliko je odgovarajuća kvačica postavljena. Pritom se provode one heuristike koje su odabrane kvačicama s desne strane retka. Nakon toga se, ukoliko je odgovarajuća kvačica postavljena, provodi mutacija. Odabir inačice križanja može se napraviti pomoću radiogumba s desne strane retka, dok se vjerojatnost mutacije upisuje u polje ispod. Nakon mutacije može se provesti još jedna heuristika, ukoliko je kvačica postavljena. Opis pojedinog genetskog operatora iskoči ukoliko korisnik zadrži miš nad pojedinim operatorom.
Nakon uređivanja iteracije algoritma može se odabrati želi li se HGA provodit pomoću Baldwinovog ili Lamarckianovog postupka (ukoliko se ne odabere niti jedna heuristika provoditi će se običan GA). Pritom treba primijetiti da se Baldwinov postupak ne može provoditi s heuristikom prije mutacije, već sam s heuristikom nakon mutacije.
Donji dio okvira za podešavanje parametara algoritma omogućuje izbor načina zaustavljanja algoritma.
Ispod okvira za podešavanja algoritma nalaze se tipke pomoću kojih se učinjene promjene u okviru za podešavanje parametara algoritma mogu spremiti u datoteku i učitati iz datoteke.
Tipka ![]() omogućuje odabir datoteke iz koje se učitava populacija s kojom se pokreće algoritam (ne stvara se nova populacija nego se učitava prije snimljena populacija).
omogućuje odabir datoteke iz koje se učitava populacija s kojom se pokreće algoritam (ne stvara se nova populacija nego se učitava prije snimljena populacija).
Desno od tipke za učitavanje populacije moguće je unijeti broj pokretanja algoritma. Moguće je više puta uzastopno pokrenuti algoritam s istim parametrima (korisno ukoliko je potrebno odrediti prosječno ponašanje algoritma – budući da je algoritam stohastičke prirode).
Velika zelena tipka ![]() pokreće algoritam i mijenja se za vrijeme izvođenja u crvenu tipku
pokreće algoritam i mijenja se za vrijeme izvođenja u crvenu tipku ![]() pomoću koje se može nasilno prekinuti izvođenje algoritma.
pomoću koje se može nasilno prekinuti izvođenje algoritma.
U okviru ![]() prikazuje se graf izvođenja algoritma, kao što je prikazano na slici 3.8.
prikazuje se graf izvođenja algoritma, kao što je prikazano na slici 3.8.
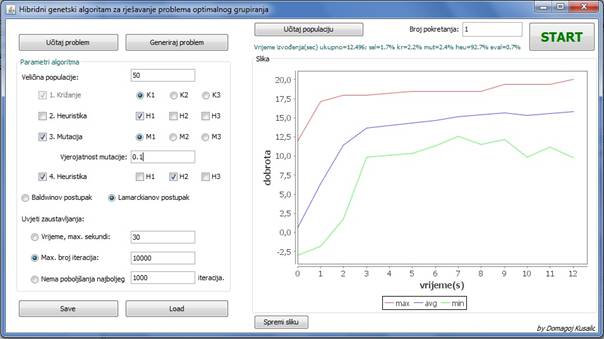
Slika 3.8: Izvođenje programa
Na grafu ![]() -os opisuje proteklo vrijeme, a
-os opisuje proteklo vrijeme, a ![]() -os dobrotu jedinke. Tri krivulje prikazuju dobrotu najbolje jedinke (crveno), prosječnu dobrotu jedinke (plavo) i dobrotu najgore jedinke (zeleno). Krivulja najgore dobrote korisna je kako bi se pratio unos novog genetskog materijala u populaciju, te konvergiranost populacije.
-os dobrotu jedinke. Tri krivulje prikazuju dobrotu najbolje jedinke (crveno), prosječnu dobrotu jedinke (plavo) i dobrotu najgore jedinke (zeleno). Krivulja najgore dobrote korisna je kako bi se pratio unos novog genetskog materijala u populaciju, te konvergiranost populacije.
Graf se može snimiti u datoteku pomoću tipke ![]() , nakon što algoritam završi izvođenje. Primjer izgleda spremljene slike grafa prikazan je na slici 3.9.
, nakon što algoritam završi izvođenje. Primjer izgleda spremljene slike grafa prikazan je na slici 3.9.
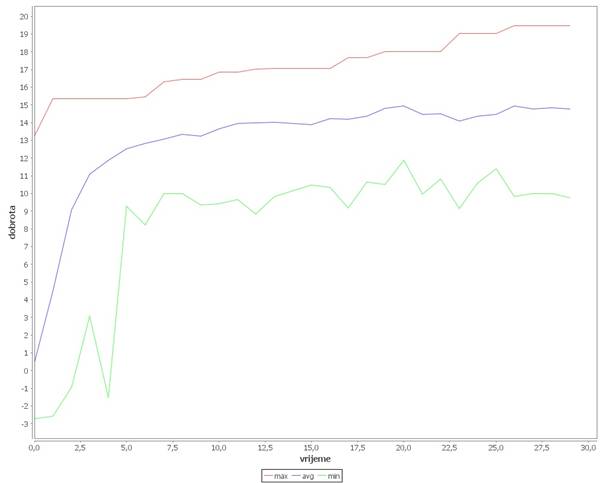
Slika 3.9: Grafički prikaz izvršavanja algoritma
Algoritam nakon što završi izvođenje automatski generira dvije datoteke. Jedna datoteka sprema stanje populacije kako bi se kasnije mogao nastaviti izračun s istom populacijom. Druga datoteka opisuje rezultate izvođenja.
Primjer izgleda datoteke s rezultatima izvođenja prikazan je na slici 3.10.
50
true 1 true 1 0.2
true 1
true 2
false
1 30
----------
Problem: C:/Users/Domagoj/Desktop/problem100_10a.txt
----------
Izgled populacije: C:/sourceEclipse/Diplomski/Populacija[2011-12-12_03.09.43]_50.pop
----------
Rezultati: iteracija 496; Vrijeme[ms]: (uku,sel,kr,mut,heu) = (30786,727,374,508,28216,146) Populacija[pop=50 best=19.472 avg=14.464 worst=9.772]
Izgled najbolje jedinke:[[37, 42, 60, 67, 71], [4, 14, 16, 22, 34, 56, 82, 83, 85, 95], [0, 74, 91], [6, 10, 30, 33, 44, 45, 50, 52, 64], [1, 7, 11, 13, 17, 23, 25, 29, 31, 32, 35, 41, 46, 47, 49, 57, 63, 72, 76, 77, 78, 86, 87, 96, 97, 99], [12, 21, 80, 93], [3, 5, 9, 15, 24, 26, 36, 38, 39, 40, 48, 53, 55, 58, 61, 65, 66, 68, 69, 75, 79, 81, 88, 92], [8, 19, 20, 27, 51, 54, 62, 70, 89, 94], [2, 28, 90], [18, 43, 59, 73, 84, 98]]
Slika 3.10: Datoteka s rezultatima izvođenja
Prvih 6 linija
datoteke opisuje parametre izvođenja algoritma (parametri se mogu učitati iz datoteka s rezultatima pomoću tipke ![]() ).
).
Datoteka navodi datoteku iz koje je učitan problem i datoteku u koju je serijalizirana populacija. Rezultati opisuju broj iteracija algoritma, vremena izvođenja u milisekundama, statistiku o populaciji (veličinu populacije i dobrotu najbolje, prosječne i najgore jedinke), te prikazuje izgled najbolje jedinke.
Izgled najbolje jedinke opisuje raspodjelu osoba po grupama (grupe su obilježene uglatim zagradama, osobe su ![]() -indeksirane). Primjer izgleda rješenja problema grupiranja
-indeksirane). Primjer izgleda rješenja problema grupiranja ![]() osoba u
osoba u ![]() grupa prikazan je na slici 3.11.
grupa prikazan je na slici 3.11.
[37, 42, 60, 67, 71],
[4, 14, 16, 22, 34, 56, 82, 83, 85, 95],
[0, 74, 91],
[6, 10, 30, 33, 44, 45, 50, 52, 64],
[1, 7, 11, 13, 17, 23, 25, 29, 31, 32, 35, 41, 46, 47, 49, 57, 63, 72, 76, 77, 78, 86, 87, 96, 97, 99],
[12, 21, 80, 93],
[3, 5, 9, 15, 24, 26, 36, 38, 39, 40, 48, 53, 55, 58, 61, 65, 66, 68, 69, 75, 79, 81, 88, 92],
[8, 19, 20, 27, 51, 54, 62, 70, 89, 94],
[2, 28, 90],
[18, 43, 59, 73, 84, 98]
Slika 3.11: Primjer rješenja problema grupiranja
Program se može dodatno detaljnije podešavati pomoću konstanti ugrađenih u kod programa:
- Želi li se isključiti hibridnu selekciju i koristiti jednostavnu selekciju koja skalira dobrotu jedinki na interval od
 do
do 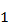 – potrebno je u klasi
– potrebno je u klasi 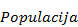 konstantu
konstantu 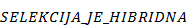 postaviti na
postaviti na 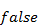 .
. - Želi li se podešavati brzina ispisa informacija u komandnu liniju potrebno je u klasi
 podesiti konstantu
podesiti konstantu  koja pamti interval između dva ispisa u milisekundama.
koja pamti interval između dva ispisa u milisekundama. - Želi li se podešavati intenzitet primjene pojedine heuristike potrebno je u odgovarajućoj klasi (
 ili
ili  ) podesiti konstantu
) podesiti konstantu 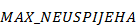 . Konstanta određuje broj uzastopnih neuspješnih pokušaja popravljanja jedinke nakon kojeg heuristika prekida rad.
. Konstanta određuje broj uzastopnih neuspješnih pokušaja popravljanja jedinke nakon kojeg heuristika prekida rad.
3.4 Analiza
Utjecaj brojčanih parametara genetskog algoritma:
- Veličina populacije utječe na brzinu konvergacije algoritma prema lokalnom optimumu. Što je populacija veća to više genetskog materijala sadrži, te je potrebno više iteracija algoritma kako bi se populacija ujednačila. Zato velika populacija sporije konvergira od male populacija. S druge strane, velika populacija sadrži veću genetsku raznolikost od manje populacije, te zato bolje pretražuje prostor pretrage i s većom vjerojatnošću pronalazi globalni optimum. Više jedinki bolje pretraže prostor pretrage, te je populacija "otpornija" na konvergiranje prema lokalnom optimum. Algoritam se sporije izvršava s većom populacijom.
- Vjerojatnost mutacije utječe na unos novog genetskog materijala u populaciju. Mutacija unosi novi genetski materijal u populaciju, te omogućava jedinkama da izađu iz lokalnog optimuma i pronađu potencijalno bolja područja pretrage. Ukoliko se vjerojatnost mutacije postavi na previše malu vrijednost, algoritam češće zapada u lokalne optimume. Ukoliko se pak vjerojatnost mutacije postavi na previše veliku vrijednost, algoritam teško otkriva globalni maksimum jer gubi sposobnost konvergacije, te provodi slučajnu pretragu prostora potencijalnih rješenja. Preporučena vjerojatnost mutacije je u intervalu
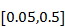 , ovisno o korištenim operatorima i korištenom postupku (Baldwinov postupak treba manje mutacije nego Lamarckianov jer sporije provodi konvergaciju genetskog materijala).
, ovisno o korištenim operatorima i korištenom postupku (Baldwinov postupak treba manje mutacije nego Lamarckianov jer sporije provodi konvergaciju genetskog materijala). - Uvjeti zaustavljanja algoritma su u direktnoj vezi s trajanjem izvođenja programa. Nakon što algoritam zapadne u neki optimum, nema previše smisla nastaviti provedbu algoritma jer je mala vjerojatnost pronalaska boljeg rješenja. Broj koraka potreban kako bi algoritam konvergirao vezan je za veličinu populacija i vjerojatnost mutacije. Što je populacija veća to joj treba više vremena za konvergaciju. Što je mutacija vjerojatnija, to populacija teže konvergira. Za veliku populaciju često je potrebna manja vjerojatnost mutacije i duže izvršavanje algoritam jer se očekuje sporija konvergacija.
U nastavku se navodi analiza operatora,
popraćena grafičkim prikazima izvršavanja algoritma. Analiza se
provodi nad slučajno generiranim problemom u kojem se treba rasporediti ![]() ljudi u
ljudi u ![]() grupa koje
primaju očekivano od
grupa koje
primaju očekivano od ![]() do
do ![]() osoba. U
praktičnoj primjeni programa se ne očekuje potreba za grupiranje više
od
osoba. U
praktičnoj primjeni programa se ne očekuje potreba za grupiranje više
od ![]() ljudi.
Moguć broj različitih jedinki za ovaj problem je reda veličine
ljudi.
Moguć broj različitih jedinki za ovaj problem je reda veličine ![]() . Pri analizi valja uvažiti informaciju da je globalni maksimum za dani
problem
. Pri analizi valja uvažiti informaciju da je globalni maksimum za dani
problem ![]() (maksimum koji
je dobiven nakon 3 dana izvršavanja programa).
(maksimum koji
je dobiven nakon 3 dana izvršavanja programa).
Usporedba različitih vjerojatnosti
mutacije dana je na slikama 3.12 do 3.19. Pritom se koristi populacija od ![]() jedinki, te običan genetski algoritam s prvom verzijom križanja i
prvom verzijom mutacije.
jedinki, te običan genetski algoritam s prvom verzijom križanja i
prvom verzijom mutacije.
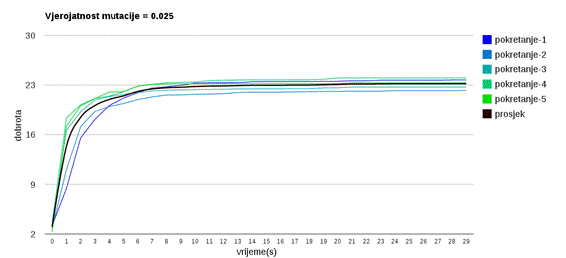
Slika 3.12: Ponašanje algoritma uz vjerojatnost mutacije 0.025
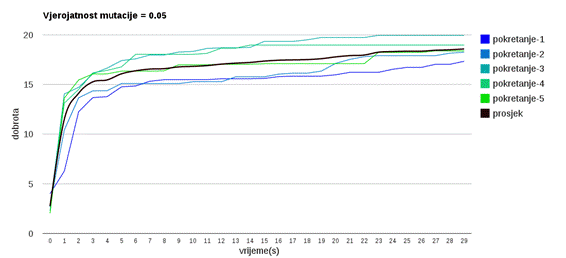
Slika 3.13: Ponašanje algoritma uz vjerojatnost mutacije 0.05
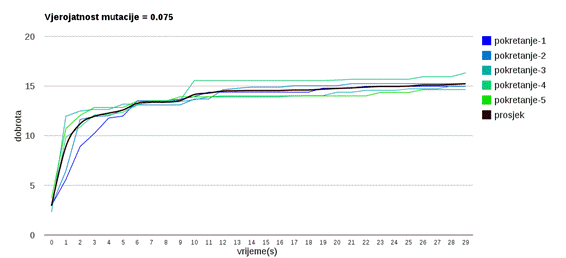
Slika 3.14: Ponašanje algoritma uz vjerojatnost mutacije 0.075
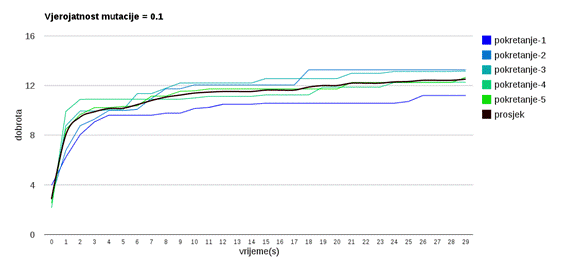
Slika 3.15: Ponašanje algoritma uz vjerojatnost mutacije 0.1
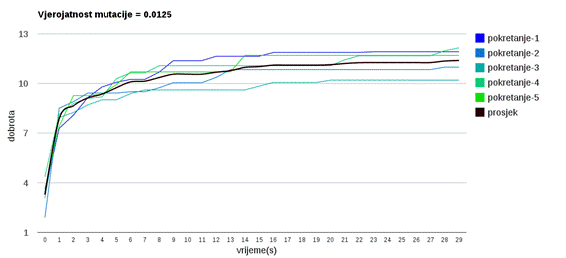
Slika 3.16: Ponašanje algoritma uz vjerojatnost mutacije 0.125
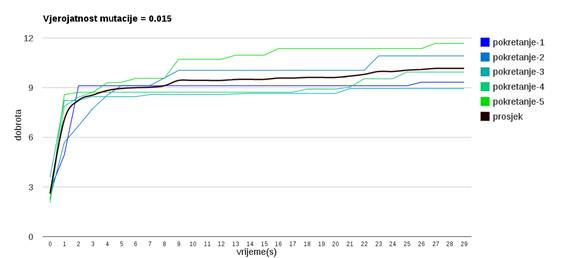
Slika 3.17: Ponašanje algoritma uz vjerojatnost mutacije 0.15
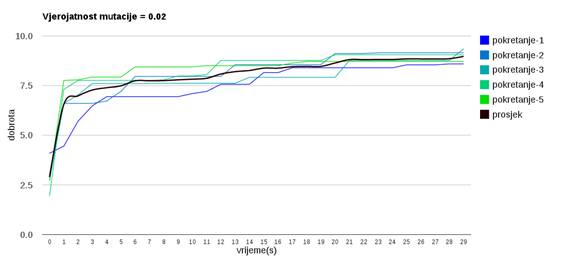
Slika 3.18: Ponašanje algoritma uz vjerojatnost mutacije 0.2
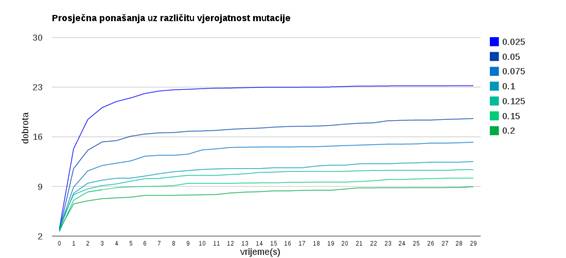
Slika 3.19: Usporedba prosječnog ponašanja algoritma uz različite vjerojatnosti mutacije
Slike 3.12 do 3.18 prikazuju pet izvršavanja
algoritma za danu vrijednost vjerojatnosti mutacije, te prosjek tih pet
izvršavanja (prikazan debljom crnom linijom) kroz vrijeme od ![]() sekundi.
sekundi.
Slika 3.12 prikazuje ponašanje uz vrlo malu vjerojatnost mutacije koja uzrokuje jaku konvergaciju populacije te brz gubitak genetskog materijala – što rezultira nemogućnošću napredovanja prema boljim rješenjima nakon što se dostigne neki lokalni optimum.
Veća vjerojatnost mutacije (slike 3.13 do 3.18) omogućava algoritmu da napreduje prema boljim rješenjima te nekonvergira prerano u lokalni optimum.
Slika 3.19 prikazuje usporedbu prosječnih ponašanja algoritma za različite vjerojatnosti mutacije.
U nastavku se (slike 3.20 do 3.23) prikazuje ponašanje algoritma za svaki od tri načina provedbe operatore križanja.
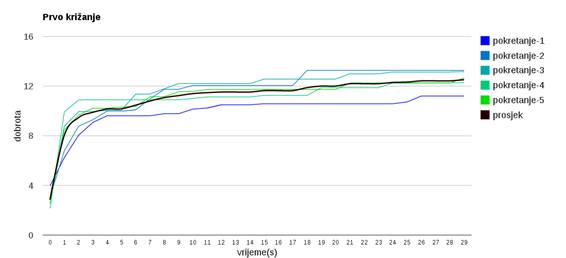
Slika 3.20: Ponašanje algoritma uz prvi operator križanja
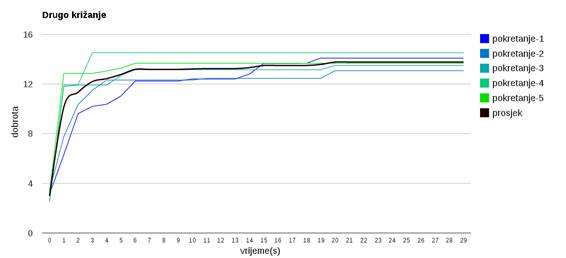
Slika 3.21: Ponašanje algoritma uz drugi operator križanja
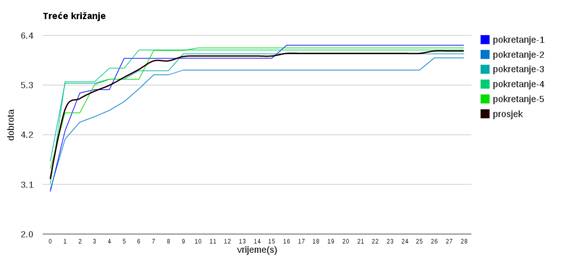
Slika 3.22: Ponašanje algoritma uz treći operator križanja
Slika 3.20 prikazuje prvu verziju križanja. Provodi se uniformno križanje pri kojem jedinke dobiju pojedinu grupu osoba od jednog ili drugog roditelja, te se jedinke nakon toga urede kako bi predstavljale valjana rješenja.
Slika 3.21 prikazuje drugu verziju križanja. Provodi se uniformno križanje pri kojem svaka osoba bude smještena u grupu u kojoj se nalazi kod nekog od roditelja. Moglo bi se pomisliti da će takvo križanje imali lošije osobine jer se ne očuva integritet grupe, međutim, takvo križanje očuva dovoljno dobrih svojstava dok ujedno omogućuje dobro istraživanje sličnog genotipa kako bi se pronašla bolja rješenja.
Slika 3.22 predstavlja treću verziju križanja, u kojem se osobe koje su u istim grupama kod oba roditelja prenose djeci, dok se sve ostale slučajno raspoređuju (ovo križanje uzrokuje jaku konvergaciju te zato treba jaču vjerojatnost mutacije).
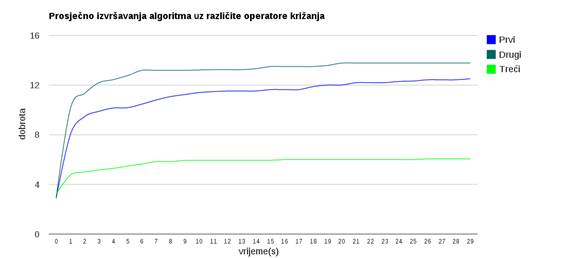
Slika 3.23: Usporedba prosječnog ponašanja algoritma uz različite odabir križanja
Slika 3.23 prikazuje usporedbu prosječnih ponašanja algoritma uz različit operator križanja.
U nastavku se (slike 3.24 do 3.26) prikazuje ponašanje algoritma za svaki od tri načina provedbe operatore mutacije.
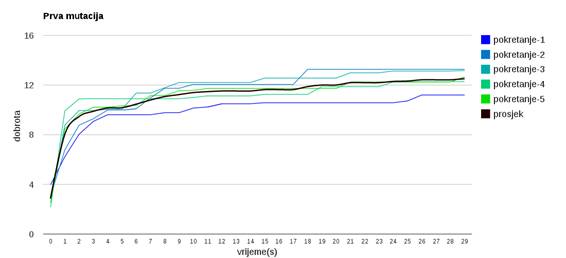
Slika 3.24: Ponašanje algoritma uz prvi operator mutacije
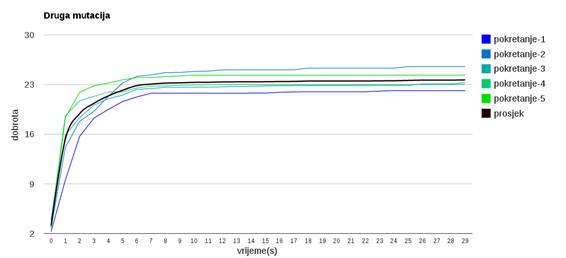
Slika 3.25: Ponašanje algoritma uz drugi operator mutacije
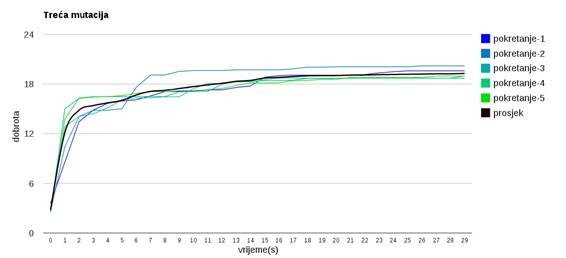
Slika 3.26: Ponašanje algoritma uz treći operator mutacije
Slika 3.24 prikazuje jednostavnu mutacija koja miče osobu po osobu u slučajnu grupu.
Slika 3.25 prikazuje mutacija koja pomiče dvije ili više osoba u slučajnu grupu.
Slika 3.26 prikazuje mutacija koja pomiče od dvije do pet osoba u krug unutar određenog broja grupa.
Različit napredak algoritma pri odabiru različitih operatora mutacije uzrokovan je različitim intenzitetom konvergacije koju pojedini operator uzrokuje.
U nastavku se (slike 3.27 do 3.29) prikazuje ponašanje algoritma uz Baldwinov i Lamarckianov postupak.
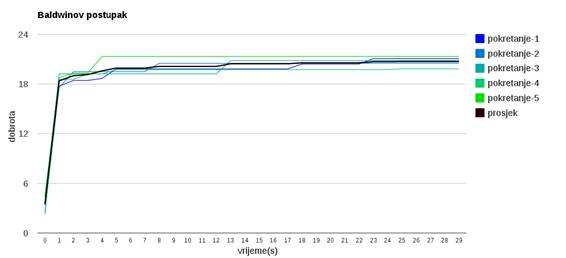
Slika 3.27: Baldwinov postupak
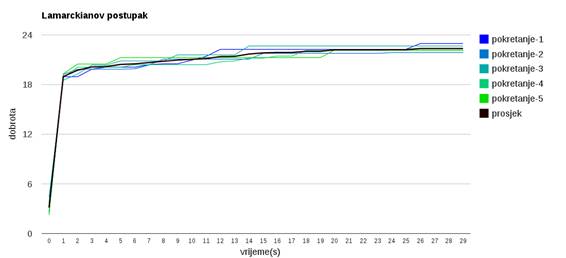
Slika 3.28: Lamarckianov postupak
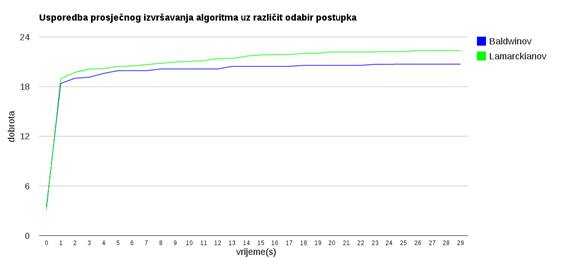
Slika 3.29: Usporedba Baldwinovog i Lamarckianovog postupak
Slika 3.29 pokazuje da Lamarckianov postupak
(koji mijenja i dobrotu i genotip jedinke) uspješnije pronalazi bolja rješenja,
te ne zapada u lokalnim optimumima. Usporedba Baldwinovog i Lamarckianovog
postupka pokazuje da Lamarckianov postupak dolazi do ![]() bliže globalnom maksimumu (
bliže globalnom maksimumu (![]() ) nego Baldwinov postupak.
) nego Baldwinov postupak.
U nastavku se (slike 3.30 do 3.33) prikazuje ponašanje algoritma uz različit odabir heurističke funkcije korištene u hibridnom genetskom algoritmu.
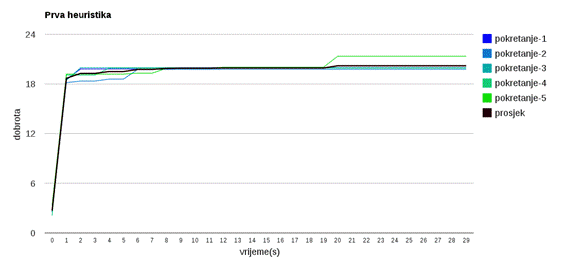
Slika 3.30: Prva heuristika
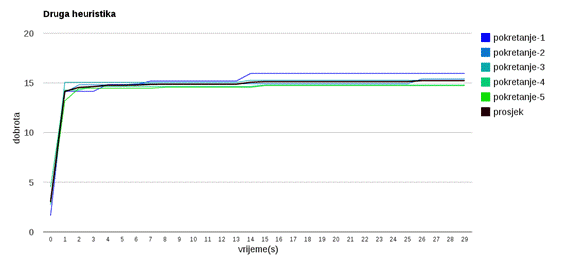
Slika 3.31: Druga heuristika
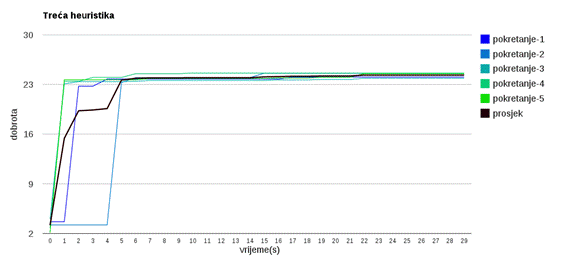
Slika 3.32: Treća heuristika
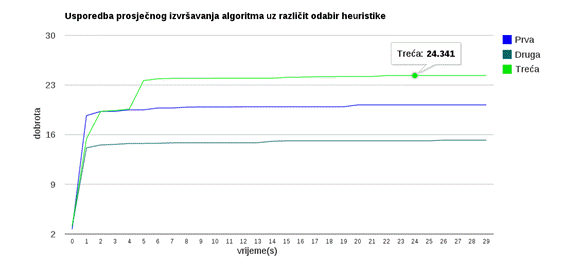
Slika 3.33: Usporedba prosječnog izvršavanje heuristika
Slika 3.30 prikazuje heuristiku koja slučajno pomiće odabranu osobu dok god se isplati pomicati.
Slika 3.31 prikazuje heuristiku koja slučajno zamjenjuje dvije osobe dok god se isplati.
Slika 3.32 prikazuje pametnu heuristiku. Pri korištenju pametna heuristika prvi poziv heurističke funkcije može trajati nekoliko sekundi (jer se jedinka može puno popraviti).
Slika 3.33 jasno pokazuje koliko je treća
heuristika bolja od prve dvije. Treća heuristika vrlo brzo postiže
rješenje s vrijednošću većom od ![]() (maksimum je
(maksimum je ![]() , dobiven nakon 3 dana izvršavanja programa).
, dobiven nakon 3 dana izvršavanja programa).
Kvalitetu treće heuristike dobro
prikazuje njena primjena pri rješavanju velikog problem u kojem treba ![]() osoba rasporediti u
osoba rasporediti u ![]() grupa (opis problema je velik
grupa (opis problema je velik ![]() ). Pametna heuristika unutar
). Pametna heuristika unutar ![]() minuta postiže gotovo optimalno rješenje (izvođenje je prikazano
na slici 3.34).
minuta postiže gotovo optimalno rješenje (izvođenje je prikazano
na slici 3.34).
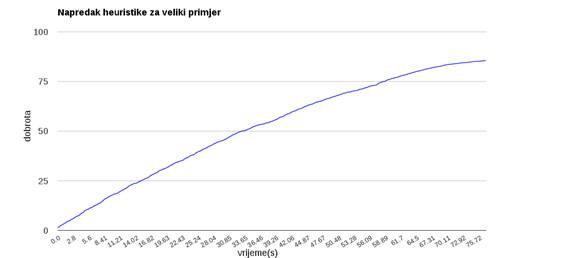
Slika 3.34: Heuristika za veliki primjer
Za problem od ![]() osoba (korišten za usporedbu svih operatora) najbolje rezultate postiže
hibridni genetski algoritam uz Lamarckianov postupak uz odabir drugog križanja,
druge mutacije, treće heuristike i vjerojatnosti mutacije
osoba (korišten za usporedbu svih operatora) najbolje rezultate postiže
hibridni genetski algoritam uz Lamarckianov postupak uz odabir drugog križanja,
druge mutacije, treće heuristike i vjerojatnosti mutacije ![]() . Algoritam unutar
. Algoritam unutar ![]() sekunda uspijeva pronaći rješenje s dobrotom većom od
sekunda uspijeva pronaći rješenje s dobrotom većom od ![]() . Slika 3.35 prikazuje isječak izvođenje algoritma.
. Slika 3.35 prikazuje isječak izvođenje algoritma.
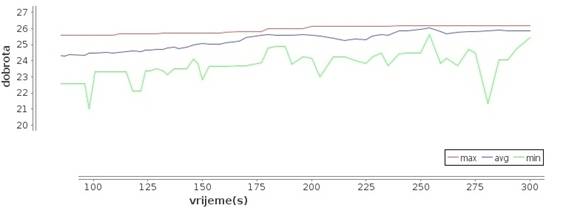
Slika 3.35: Algoritam podešen za primjer od 100 ljudi
Zanimljivo je primijetiti na slici da
algoritam uspješno pronalazi sve bolja rješenja kad god se prosječna
dobrota populacije približi dobroti najbolje jedinke (unatoč vjerojatnosti
mutacije od čak ![]() ). Izvršavanje
algoritma prikazano na slici 3.35 pronalazi jedinku dobrote
). Izvršavanje
algoritma prikazano na slici 3.35 pronalazi jedinku dobrote ![]() što je samo
što je samo ![]() manje od
globalnog optimuma. To je fascinantno budući da je prostor pretrage
manje od
globalnog optimuma. To je fascinantno budući da je prostor pretrage ![]() , a opis problema sadrži
, a opis problema sadrži ![]() veza između osoba, od kojih je podjednako pozivnih i negativnih, dok
je prosječna težina veze samo
veza između osoba, od kojih je podjednako pozivnih i negativnih, dok
je prosječna težina veze samo ![]() . Drugim riječima – ukupan zbroj svih pozitivnih veza u rješavanom
primjeru je manji od
. Drugim riječima – ukupan zbroj svih pozitivnih veza u rješavanom
primjeru je manji od ![]() , a algoritam
uspješno pronalazi raspored koji uspijeva preferiranjem pozitivnih veza nad
negativnim dobiti sumu
, a algoritam
uspješno pronalazi raspored koji uspijeva preferiranjem pozitivnih veza nad
negativnim dobiti sumu ![]() , raspoređujući ljude u
, raspoređujući ljude u ![]() zasebnih grupa unutar kojih se sve veze sumiraju (i negativne i
pozitivne).
zasebnih grupa unutar kojih se sve veze sumiraju (i negativne i
pozitivne).
3.5 Primjena
Rješavanje problema optimalnog grupiranja ima vrlo široku primjenu.
Rješenje se može primijeniti za optimalno grupiranje:
- zaposlenika po smjenama u kojima rade,
- zaposlenika po prostorijama u kojima rade,
- zaposlenika po timovima u kojima rade,
- raspoređivanje ljudi po fizičkim lokacijama (po hotelskim sobama, ili po stolovima za svečane večere),
- raspoređivanje djece po timovima za igranje timskih sportova,
- za grupiranje profila socijalnih mreža kako bi se postiglo što manje mrežne (izvanserverske) komunikacije,
- za grupiranje raznih drugih povezanih računalnih resursa.
Rezultat optimalnijeg grupiranje je veća produktivnost grupe ljudi (ili resursa) koji surađuju, te time i optimalnije raspolaganje danim resursima. Što rezultira sretnijim zaposlenicima i većom produktivnosti u poslovnom procesu.
4. Zaključak
Hibridni genetski algoritmi predstavljaju spoj lokalnih pretraga i genetskog algoritma u funkciji globalne pretrage. U lokalne pretraga ugrađuje se postojeće znanje o specifičnosti problema koji se rješava. Za razliku od tradicionalnih evolucijskih tehnika, hibridni genetski algoritmi prvenstveno pokušavaju iskoristiti sve dostupno znanje o rješavanom problemu.
U radu je opisan problem optimalnog grupiranja. Osmišljen je i ostvaren programski sustav koji hibridnim genetskim algoritmom rješava problem optimalnog grupiranja. Ostvareno rješenje koristi različite genetske operatora koji su u radu detaljno analizirani. Kroz ostvareno grafičko sučelje upravlja se podešavanjem parametara i izvođenjem programa, te se vizualizira napredovanje algoritma. Programski sustav uspješno rješava problem optimalnog grupiranja, te u vrlo kratkom vremenu daje kvalitetne rezultate. Programski sustav je primjenjiv na stvarne probleme grupiranja.
Literatura
[1] Carlos Cotta. Intro to Memetic Algorithms, 2002.
[2] Jianyong Sun and Jonathan M. Garibaldi. A Novel Memetic Algorithm for Constrained Optimization, 2010.
[3] Manuel Lozano, Francisco Herrera, Natalio Krasnogor, Daniel Molina. RealCoded Memetic Algorithms with Crossover Hill-Climbing. Evolutionary Computation, 12(3):273–302, 2004.
[4] Marin Golub. Genetski algoritam, skripta – 1. dio, 1997. URL http://www. zemris.fer.hr/~golub/ga/ga_skripta1.pdf.
[5] Natalio Krasnogor. Memetic Algorithms, 2009.
[6] Pablo Moscato, Carlos Cotta. A gentle introduction to Memetic Algorithms, 2000.
[7] Pablo Moscato, Carlos Cotta. Memetic Algorithms, 2005.
[8] Sanghamitra Bandyopadhyay & Sankar K. Pal. Classification and Learning Using Genetic Algorithms. Springer, 2007.
[9] Tarek A. El-Mihuob, Adrian A. Hopgood, Lars Nolle, Alan Battersby. Hybrid Genetic Algorithms: A Review. Engineering Letters, 13:2, 2006.
[10] Wikipedia. Evolutionary algorithm, 2010. URL http://en.wikipedia. org/wiki/Evolutionary_algorithm.
[11] Wikipedia. Evolutionary computation, 2010. URL http://en.wikipedia. org/wiki/Evolutionary_computation.
[12] Wikipedia. No free lunch in search and optimization, 2010. URL http://en.wikipedia.org/wiki/No_free_lunch_in_search_and_optimization.
[13] William E. Hart, N. Krasnogor, J. E. Smith. Recent Advances in Memetic Algorithms. Springer, 2005.
[14] Wolpert, D.H., Macready, W.G. No Free Lunch Theorems for Optimization, 1997.
[15] Xiuzhen Huang, Negative-Weight Cycle Algorithms, 2006.
[16] Y.S. Ong and A.J. Keane. Meta-Lamarckian Learning in Memetic Algorithms, 2003.
Hibridni genetski algoritam za rješavanje problema optimalnog grupiranja
Sažetak
Hibridni Genetski algoritmi (HGA) su klasa stohastičkih heuristika globalne pretrage u kojima se genetski algoritmi kombiniraju s lokalnim pretragama kako bi se popravila kvaliteta rješenja. Za razliku od tradicionalnih evolucijskih tehnika, hibridni genetski algoritmi prvenstveno pokušavaju iskoristiti sve dostupno znanje o rješavanom problemu. U ovom radu se hibridnim genetskim algoritmom pristupa rješavanju problema optimalnog grupiranja. Problem optimalnog grupiranja pripada kategoriji NP-potpunih problema, te pronalazi mnoge primjene u industriji. Programski je ostvaren hibridni genetski algoritam koji rješava problem optimalnog grupiranja. Programski sustav je detaljno opisan, analizirane su svojstva sustave, kvaliteta rješenja koje sustav stvara, te opisani utjecaji parametara hibridnog genetskog algoritma na performanse sustava. Ostvareni programski sustav uspješno rješava problem optimalnog grupiranja.
Ključne riječi: hibridni genetski algoritam, problem optimalnog grupiranja
Solving Optimal Grouping Problem with Hybrid Genetic Algorithm
Abstract
Hybrid Genetic Algorithms (HGA) are a class of stochastic global search heuristics in which the genetic algorithm is combined with local search to improve the quality of the solutions. Unlike traditional evolutionary techniques, hybrid genetic algorithms try to utilize all available knowledge about the problem. In this paper, the hybrid genetic algorithm is used to solving optimal grouping problem. The optimal grouping problem belongs to the category of NP-complete problems, and it finds many applications in the industry. The hybrid genetic algorithms that solves the optimal grouping problem has been implemented. The software system is described in detail. System performance and quality of solutions are analyzed. Influence of hybrid genetic algorithm parameters on the performance of the system are described. The software system successfully solves the optimal grouping problem.
Keywords: Hybrid Genetic Algorithm, Optimal Grouping Problem