1. UVOD
Mnoga postignuća na području računalne tehnologije u posljednja dva desetljeća omogućila su intenzivno korištenje višeprocesorskih sustava. U tim sustavima, ključ za postizanje visoke učinkovitosti je optimalno raspoređivanje paralelnog programa na više procesora. Paralelni program sastoji se od više poslova koji se mogu izvršavati paralelno uz poštivanje relacije prethođenja. Rasporediti paralelni program na više procesora znači dodijeliti poslove procesorima te odrediti njihov redoslijed izvršavanja. Optimalan raspored je raspored čije je ukupno vrijeme izvršavanja minimalno. Problem raspoređivanja poslova u višeprocesorskim sustavima zadaje se brojem procesora, trajanjem poslova te relacijom prethođenja poslova. U općem slučaju, problem raspoređivanja uključuje različite brzine procesora i njihovu međusobnu povezanost te vremena kašnjenja zbog komunikacije među poslovima koji se izvršavaju na različitim procesorima. Problem raspoređivanja spada u klasu NP-teških problema, čak i u slučaju kada su procesori potpuno povezani te nema komunikacijskog kašnjenja [2]. Zbog toga je dizajnirano mnogo heurističkih metoda kako bi se postigla rješenja bliska optimalnom. Genetski algoritmi često se koriste za rješavanje problema raspoređivanja [1].
Tema ovog rada je primjena jednostavnog genetskog algoritma na problem raspoređivanja poslova višeprocesorskog sustava. Zbog kompleksnosti općeg slučaja problema, problem raspoređivanja je pojednostavljen: pretpostavlja se da su procesori potpuno povezani i izvršavaju poslove jednakim brzinama te da nema komunikacijskog kašnjenja.
Praktični dio rada sastoji se od dva dijela. Prvi dio obuhvaća implementaciju genetskog algoritma za rješavanje problema raspoređivanja poslova i eksperimentiranje sa različitim parametrima genetskog algoritma. Korištena je programska izvedba genetskog algoritma za rješavanje problema rasporeda [2]. Program je prilagođen za izvršavanje na MS Windows operacijskim sustavima te proširen za potrebe grafičkog prikaza rasporeda. U okviru drugog dijela praktičnog rada izrađena je aplikacija za grafičko prikazivanje rješenja genetskog algoritma tj. rasporeda poslova.
Cilj rada je eksperimentalnim putem odrediti utjecaj parametara genetskog algoritma na kvalitetu dobivenih rješenja.
2. PROBLEM RASPOREĐIVANJA POSLOVA
Problemi raspoređivanja mogu se svrstati u kombinacijske probleme. Rješenje tih problema predstavlja raspored koji je izvediv, ali koji mora nastojati ispuniti niz dodatnih ograničenja. Bolje ili lošije ispunjavanje tih ograničenja definira kvalitetu samoga rješenja. Ovi problemi spadaju u klasu NP-potpunih problema [4].
Definicija pojednostavljenog problema raspoređivanja poslova [2]: Višeprocesorski sustav sastoji se od P identičnih procesora (njihove brzine procesiranja su jednake). Procesori su potpuno povezani i bez komunikacijskog kašnjenja. Svaki procesor može izvršavati najviše jedan posao istovremeno. Vrijeme izvršavanja poslova ne mora biti jednako. Paralelni program predstavljen je direktnim acikličkim grafom G=(V,E). V={Ti}, i = 1,2,...,N predstavlja skup poslova sa pridruženim težinama {ri} gdje ri označava trajanje izvršavanja posla Ti. E={eij} je skup usmjerenih bridova koji definiraju parcijalni poredak ili ograničenja prethođenja prilikom redoslijeda izvršavanja poslova iz skupa V.
U pojednostavljenom slučaju problema komunikacija između dva posla je zanemariva, odnosno trošak komunikacije između dva posla koja su dodijeljena istom procesoru je nula. Poslovi bez prethodnika zovu se ulazni poslovi, a poslovi bez sljedbenika su izlazni poslovi. Svaki posao je prisutan i pojavljuje se točno jedanput u rasporedu (potpunost i jedinstvenost). Problem optimalnog raspoređivanja grafa poslova na višeprocesorski sustav sa P identičnih procesora sastoji se od dodjeljivanja poslova procesorima, tako da svi poslovi budu izvršeni u najkraćem vremenu. Vrijeme završavanja posljednjeg posla zove se završno vrijeme rasporeda i označava se sa FT (eng. Finishing Time). Neka je P broj procesora, a Z broj poslova koje treba rasporediti. Primjer grafa poslova za Z=10 [2] prikazan je na slici 2.1.
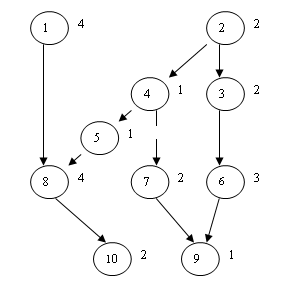
Slika 2.1. Primjer jednostavnog grafa poslova
Svaki posao je prikazan kružnicom. U kružnici je upisan indeks posla, a s desne strane kružnice njegovo trajanje. Relacija prethođenja je prikazana usmjerenom linijom (strelicom). Na primjer, za izvršavanje posla sa indeksom 4 potrebno je završiti posao s indeksom 2. Poslu s indeksom 8 prethode poslovi sa indeksima 1 i 5.
Postoji mnogo znanstvenih radova na
području raspoređivanja poslova. U većini tih radova se
različiti algoritmi raspoređivanja evaluiraju na slučajno generiranim
grafovima poslova ili na grafovima poslova koji su modelirani na temelju
stvarnih aplikacija [9]. Korišteni grafovi obično nisu dostupni drugim
istraživačima problema raspoređivanja. Kako bi se svim
istraživačima omogućilo evaluiranje algoritama pod istim uvjetima,
Kasahara Laboratory predlaže standardni skup grafova poslova, tzv. “Standard Task Graph Set” koji pokriva obje prethodno navedene metode
generiranja grafova [9]. Osim grafova poslova navedena su i završna vremena
njihovih optimalnih rasporeda, što omogućuje uspoređivanje kvalitete
algoritama.
Jedan od formata zapisa tih grafova je tzv. prototype format [9]. Primjer zapisa grafa poslova sa slike 2.1. uz 3 procesora prikazan je na slici 2.2.
|
10 3 1 4 0 2 2 0 3 2 1 2 4 1 1 2 5 1 1 4 6 3 1 3 7 2 1 4 8 4 2 1 5 9 1 2 6 7 10 2 1 8 11 0 2 9 10 |
Slika 2.2. Zapis grafa poslova sa slike 2.1. za 3
procesora u prototype formatu
Značenja pojedinih linija zapisa objašnjena su u sljedećoj tablici:
Tablica 2.1. Objašnjenje prototype formata zapisa
|
Linija |
Objašnjenje |
|
Sve linije |
Polje zapisa
brojeva sadrži 6 znakova |
|
Prva linija |
"10"
označava broj poslova, "3" označava broj procesora |
|
Druga linija |
"1"
označava posao broj 1. "4" znači da je trajanje tog posla
4 vremenske jedinice. "0"
znači da posao broj 1 nema prethodnika t.j. poslova koji moraju
završiti prije njega |
|
Četvrta linija |
"3"
označava posao broj 3. Trajanje tog posla je "2" vremenske
jedinice. "1" označava da taj posao ima 1 prethodinka.
"2" označava da je posao broj 2 prethodnik posla broj 3 |
|
Ostale linije |
predstavljaju
podatke za svaki posao prema gore navedenim objašnjenjima |
|
Zadnja linija |
sadrži podatke o
završnom "pomoćnom" čvoru, koji ima trajanje 0 tj.
predstavlja završetak svih poslova |
Budući je potpuno pretraživanje (eng. exhaustive search) prostora rješenja najčešće nepraktično, u većini radova se istražuju brze heurističke metode [5]. Heuristički algoritmi ne garantiraju nalaženje optimuma, ali mogu brzo naći rješenje koje je blizu optimalnog. Većina heurističkih metoda raspoređivanja poslova ubraja se u grupu raspoređivanja listama. Nakon što se svim poslovima dodijeli prioritet oni se dodaju u listu neraspoređenih poslova koja je sortirana prema padajućem prioritetu. Kako procesori završavaju sa izvršavanjem dodijeljenih poslova, iz liste se odabire posao s najvećim prioritetom i dodjeljuje najprikladnijem procesoru. Algoritmi u ovoj grupi razlikuju se prema strategiji dodjeljivanja prioriteta i načinu na koji se odabire najprikladniji procesor.
Druga skupina algoritama koji se primjenjuju u raspoređivanju poslova su genetski algoritmi. Po načinu djelovanja ubrajaju se u metode usmjerenog slučajnog pretraživanja prostora rješenja (eng. guided random search techniques) u potrazi za globalnim optimumom. Genetski algoritami sposobni su odrediti položaj globalnog optimuma u prostoru s više lokalnih ekstrema. Upravo u toj činjenici leži prednost genetskih algoritama nad algoritmima raspoređivanja listama. Klasične determinističke metode uvijek će se kretati prema lokalnom minimumu ili maksimumu, pri čemu on može biti i globalni. S druge strane, genetski algoritmi istovremeno istražuju prostor rješenja u više točaka, što im omogućuje da izbjegnu lokalne ekstreme.
3. JEDNOSTAVNI GENETSKI ALGORITAM
Genetski algoritmi predloženi su od strane Johna H. Hollanda još u ranim sedamdesetima. Holland je u svom radu predložio jednostavni genetski algoritam kao računalni proces koji imitira evolucijski proces u prirodi i primjenjuje ga na apstraktne jedinke.
Genetski algoritam je stohastička metoda optimiranja čiji se princip rada zasniva na oponašanju prirodnog procesa selekcije i evolucije. Darwinov zakon preživljavanja najjačega (najsposobnijega) koji opisuje procese evolucije u prirodi prenosom najkvalitetnijeg genetskog materijala iz generacije u generaciju, primjenjuje se nad umjetnim strukturama u računalnim sustavima radi traženja optimalnog rješenja određenog problema. Uvjet primjene genetskog algoritma je postojanje neodređenog (potencijalno velikog) broja rješenja optimizacijskog problema.
|
početak stvori populaciju P(0) ponavljaj odaberi P(t) iz P(t-1) primjeni genetske operatore na P(t) dok nije zadovoljen uvjet zaustavljanja Kraj |
Slika 3.1. Struktura genetskog algoritma [6]
Osnovne karakteristike genetskih algoritama su: predstavljanje rješenja, inicijalizacija i uvjet završetka evolucijskog procesa, definiranje funkcije dobrote, postupak selekcije tj. strategija izbora roditelja i zamjene potomcima te genetski operatori križanja i mutacije.
Jednostavni genetski algoritam koristi binarni prikaz rješenja, jednostavnu selekciju, križanje s jednom točkom prekida i jednostavni operator mutacije [3]. Binarni prikaz, jednostavna selekcija i spomenuti genetski operatori opisani su u poglavljima koja slijede.
3.1. Predstavljanje rješenja
Svako potencijalno rješenje problema optimiranja prikazuje se kao skup parametara, kodiran na odgovarajući način ovisno o tipu problema. Ovi se parametri nazivaju geni, a skup gena koji predstavljaju rješenje zove se kromosom.
Za razliku od klasičnih metoda, optimum se ne traži iz pojedinačne točke, već iz skupa točaka – kromosoma. Kromosomi čine populaciju. Skup kromosoma u nekom trenutku nazivamo generacijom.
Prikaz odnosno predstavljanje rješenja može bitno utjecati na učinkovitost genetskog algoritma. Zbog toga je izbor prikaza izuzetno značajan. Većina teorije na području genetskih algoritama vezana je upravo uz binarni prikaz. U praksi se pokazalo da binarni prikaz daje najbolje rezultate u većini primjera gdje se on može koristiti.
U binarnom prikazu kromosom se predstavlja sa kodiranom vrijednošću xÎ[dg, gg]. Vrijednosti dg i gg označavaju donju i gornju granicu intervala, respektivno. Dužina n binarnog broja utječe na preciznost i označava broj bitova, odnosno broj jedinica ili nula u jednom kromosomu. Takvim vektorom je moguće zapisati 2n različitih kombinacija nula i jedinica, tj. moguće je zapisati bilo koji broj u intervalu [0, 2n-1]. Binarni vektor sa samim nulama predstavlja vrijednost x=dg, a vektor sa samim jedinicama predstavlja vrijednost x=gg. Općenito, ako je binarni broj bÎ[0, 2n-1] zapisan kao binarni vektor v(b)=[Bn-1Bn-2.....B1B0], gdje je BiÎ[0, 1], tada vrijedi [3]:
|
binarni broj: |
ekvivalentan realan broj: |
kodiranje: |
|
|
|
|
|
(3-1), (3-2), (3-3) |
Dekodiranje je proces pretvaranja binarnog broja u potencijalno rješenje. U ovom slučaju potencijalno rješenje je bilo koji realan broj x u intervalu [dg, gg]. Binarni vektor v(b) predstavlja vrijednost x koja se izračunava prema formuli (3-2). Kodiranje, odnosno određivanje binarnog broja b za zadani realan broj x obavlja se prema formuli (3-3).
Neka je rješenje x preciznosti p i neka je pÎN. To znači da x odstupa od točnog rješenja za maksimalno 10-p. Odnosno, rješenje x je točno na p decimala. Rješenje x je preciznosti p ako je zadovoljena nejednakost (3-4). Za zadanu preciznost p rješenja x, duljina kromosoma n mora zadovoljavati izraz (3-5) [3].
|
|
(3-4),(3-5) |
3.2. Inicijalizacija i uvjet završetka evolucijskog procesa
Različitost kromosoma se postiže na dva načina: stohastičkim stvaranjem prve generacije i operatorom mutacije. Operator mutacije opisan je u poglavlju 3.5.
Za početnu generaciju najčešće se kreiraju slučajno izabrana rješenja. Ako je takav skup rješenja teško ili nemoguće ostvariti na slučajan način tada se koristi neka druga metoda, npr. heuristički algoritam koji pronalazi dobra rješenja problema.
Uvjeti zaustavljanja mogu biti različiti: zadani broj iteracija, broj evaluacija funkcije dobrote, dostignuta vrijednost funkcije dobrote, broj iteracija bez poboljšanja, vremensko ograničenje. Najčešće se koristi unaprijed zadani broj iteracija a budući da je vrijeme izvođenja pojedine iteracije približno konstantno, time je zadano i trajanje optimiranja [3].
3.3. Funkcija dobrote
Osnovna informacija koja upravlja optimiranjem je mjera prilagođenosti pojedinog rješenja (kromosoma). Što je vrijednost mjere prilagođenosti bliža optimumu u odnosu na ostatak populacije, to je rješenje prilagođenije. Funkcija dobrote predstavlja brojčanu mjeru prilagođenosti pojedinih rješenja a time i veličinu koja upravlja genetskim algoritmima u konvergenciji prema najboljim rješenjima. U problemima traženja optimuma funkcije, mjera prilagođenosti nekog rješenja je upravo vrijednost funkcije za to rješenje. U drugim je problemima, uz pravilan odabir kodiranja kromosoma, bitna izgradnja funkcije dobrote koja će voditi prema najboljem dozvoljenom rješenju i potiskivati zabranjena rješenja.
Genetski algoritmi ne očekuju nikakve dopunske informacije o problemu optimiranja osim funkcije dobrote. Ona ne mora biti ni neprekidna, ni derivabilna, pa čak niti egzaktno definirana.
Kvaliteta jedinki mjeri se pomoću funkcije cilja f. Neki postupci selekcije zahtijevaju da funkcija cilja ne može biti negativna te da ne poprima samo velike, približno jednake, vrijednosti. Zbog toga se obično u svakoj iteraciji obavlja translacija funkcije cilja, tj. vrijednosti funkcije cilja pojedine jedinke oduzima se najmanja vrijednost funkcije cilja u cijeloj populaciji. Rezultat je funkcija dobrote d koja se računa prema izrazu:
|
d=f-fmin(t), |
(3-6) |
gdje je fmin(t) najmanja vrijednost funkcije cilja u generaciji t [7].
Funkcija dobrote se prema tome definira kao razlika između vrijednosti funkcije cilja jedinke i najlošije vrijednosti funkcije cilja populacije.
3.4. Postupci selekcije
Svrha selekcije je čuvanje i prenošenje dobrih svojstava na sljedeću generaciju jedinki. Selekcijom se odabiru dobre jedinke koje će sudjelovati u reprodukciji, tj. križanju. Na taj se način dobri geni čuvaju i prenose na sljedeću populaciju, a loši odumiru [3].
Postoji mnogo strategija selekcije, a razlikuju se po načinu odabira boljih jedinki. Zajedničko svojstvo svih vrsta selekcija je veća vjerojatnost odabira boljih jedinki za reprodukciju.
Dva su bitna kriterija za podjelu vrsta selekcija:
· način prenošenja genetskog materijala boljih jedinki u sljedeću iteraciju
· metoda odabira boljih odnosno lošijih jedinki
Prema prvom kriteriju postupci selekcije dijele se na:
· generacijske selekcije
· eliminacijske selekcije
Generacijskom selekcijom odabiru se bolje jedinke koje će sudjelovati u reprodukciji. Izabrane jedinke iz populacije iz prethodnog koraka prenose se u međupopulaciju koja sudjeluje u reprodukciji. Budući da je broj izabranih jedinki manji od veličine populacije, razlika u broju izabranih jedinki i veličine populacije najćešće se popunjava duplikatima izabranih jedinki. Glavni nedostaci generacijskih selekcija su postojanje dvije populacije jedinki i pojava duplikata u međupopulaciji koja samo usporava evolucijski proces i ne doprinose kvaliteti rješenja [7]. Jedinke iz međupopulacije sudjeluju u reprodukciji tj. stvaraju nove jedinke koje ulaze u sljedeću generaciju. Svaka jedinka egzistira točno jednu generaciju, te je time postavljena granica između generacija. Izuzetak je primjena elitizma u kojem se čuvaju najbolje jedinke koje se nepromijenjene prenose u sljedeću generaciju.
Kod eliminacijskih selekcija biraju se loše jedinke za eliminaciju, a bolje jedinke preživljavaju postupak selekcije. Budući da bolje jedinke egzistiraju kroz više generacija, stroge podjele između generacija nema. U svakoj iteraciji briše se M loših jedinki. Parametar M naziva se mortalitetom ili generacijskim jazom. Reprodukcijom preživjelih jedinki stvaraju se nove jedinke koje nadomještavaju izbrisane jedinke. Eliminacijskom selekcijom otklanjaju se oba nedostatka generacijske selekcije: ne koriste se dvije populacije u jednoj iteraciji i u postupku selekcije ne stvaraju se duplikati.
Prema metodi odabira boljih jedinki kod generacijskih selekcija, odnosno lošijih jedinki kod eliminacijskih selekcija, postupci selekcije dijele se na:
· proporcionalne selekcije
· rangirajuće selekcije
Zajednička karakteristika svih selekcija je veća vjerojatnost preživljavanja bolje jedinke od bilo koje lošije jedinke. Selekcije se razlikuju prema načinu na koji se određuje vrijednost vjerojatnosti selekcije određene jedinke. Podjela selekcija prikazana je na slici 3.2.
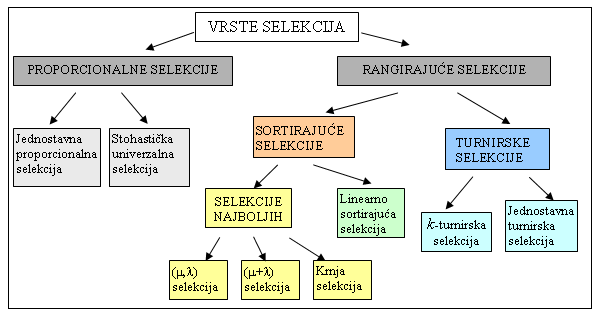
Slika 3.2. Vrste selekcija [8]
3.4.1. Proporcionalne selekcije
Kod proporcionalnih selekcija, vjerojatnost selekcije jedinke ovisi o kvocijentu dobrote jedinke i prosječne dobrote populacije. Analiza rada genetskih algoritama sa takvim selekcijama znatno je olakšana jer su generacijske proporcionalne selekcije predmet mnogih teorijskih razmatranja [8]. Međutim, proporcionalna selekcija obavlja u svakoj iteraciji izračunavanje srednje vrijednosti dobrote populacije i translaciju funkcije dobrote prema izrazu (3-6). Budući da proporcionalne selekcije ne čuvaju najbolje jedinke, obično se ugrađuje elitizam pa u svakoj iteraciji treba pronaći unaprijed zadan broj najboljih jedinki. To znači da se jedinke moraju barem djelomično sortirati prema dobroti. To sve troši stanovito procesorsko vrijeme i dosta usporava rad genetskog algoritma. Zbog tih nedostataka proporcionalnih selekcija u novije vrijeme se intenzivno razmatraju mogućnosti rangirajućih selekcija [8].
Postoje dvije vrste proporcionalnih selekcija:
· jednostavna proporcionalna selekcija
· stohastička univerzalna selekcija
Pri jednostavnoj proporcionalnoj selekciji
vjerojatnost preživljavanja jedinke proporcionalna je njezinoj dobroti.
Često se ova selekcija uspoređuje s kotačem ruleta. Svakoj
jedinki dodijeljen je odsječak kotača. Veličina odsječka proporcionalna
je dobroti jedinke. “Zavrtimo kotač”
i izaberemo jedinku na čijem se odsječku “kuglica” zaustavi. Mogući algoritam za
ostvarenje ove selekcije je:
1. zbrajaju se redom
vrijednosti dobrote svih jedinki u populaciji
2. generira se slučajan
broj između 0 i 1, pa se pomnoži sa sumom dobrota jedinki
3. odabere se prva jedinka
za koju je zbroj dobrota od prve jedinke do nje uključivo veća ili
jednaka izračunatom slučajnom broju u prethodnom koraku
Kod
generacijske proporcionalne selekcije taj postupak se primjenjuje sve dok se ne
izabere N jedinki koje će sudjelovati u reprodukciji, s tim da se
jedna te ista jedinka može izabrati proizvoljan broj puta.
Suprotno
tome, kod eliminacijske proporcionalne selekcije bira se jedinka koja će
se eliminirati. Vjerojatnost eliminacije jednike obrnuto je proporcionalna
njenoj dobroti. Umjesto funkcije dobrote definira se funkcija kazne kao razlika
između vrijednosti dobrota najbolje jedinke u populaciji i jedinke za koju
se računa vrijednost kazne. Time je implicitno ugrađen elitizam:
najbolja jedinka se čuva jer je vrijednost eliminacije najbolje jedinke (s
najvećim iznosom dobrote) jednaka nuli. Jednom odabrana jedinka za
eliminaciju ne može se više odabrati pa je u svakom koraku potrebno
računati kumulativne vrijednosti funkcije kazne.
Stohastička
univerzalna selekcija razlikuje se od jednostavne proporcionalne selekcije
prema načinu odabira jedinki. Vjerojatnost selekcije se računa na
isti način kao i u jednostavnoj selekciji. Dok se jednostavna
proporcionalna selekcija obavlja u N koraka (N puta se se
generira slučajan broj prema kojem se određuje koja jedinka je
selektirana), stohastička univerzalna selekcija obavlja odabir svih
jedinki u jednom koraku. Generira se N ekvidistantnih znački tako
da se interval [0,1] podijeli na N+1 jednakih odsječaka. Broj
znački koje se nalaze unutar odsječka jedne jedinke određuje
koliko će se njenih kopija prenijeti u sljedeću populaciju.
3.4.2. Rangirajuće selekcije
Kod rangirajućih selekcija vjerojatnost selekcije ne ovisi izravno o dobroti, već o položaju jedinke u poretku jedinki sortiranih po dobroti. Jedinke se mogu sortirati ili s rastućom ili padajućom dobrotom, odnosno po rastućim ili padajućim vrijednostima funkcije cilja. Pri sortiranju s padajućom dobrotom, najbolja jedinka ima indeks i=1, a najlošija i=N, te je i-1 broj jedinki koje su bolje od i-te jedinke.
Za rangirajuću selekciju nije važan iznos dobrote, već njen odnos prema dobroti ostalih jedinki. Isto tako nije važno da li je funkcija dobrote negativna ili poprima samo približno jednake vrijednost. Kod rangirajućih selekcija funkcija dobrote nema nikakvih ograničenja i jednaka je funkciji cilja. Ako dvije jedinke imaju jednake vrijednosti funkcije cilja, bilo koja od njih može se proglasiti boljom i prenijeti u novu generaciju.
U skupinu rangirajućih selekcija spadaju sortirajuće i turnirske selekcije. Sortirajuće selekcije obavljaju sortiranje jedinki prema njihovoj vrijednosti funkcije cilja. Postupak troši značajni dio od ukupnog procesorskog vremena, jer se ponavlja u svakoj iteraciji. S obzirom da je sortiranje vremenski zahtijevan posao u odnosu na trajanje same selekcije, sortirajuće selekcije se rijetko koriste. S druge strane, za turnirske selekcije važan je samo odnos između nekoliko slučajno odabranih jedinki i nije potrebno obavljati sortiranje cijele populacije.
Dvije su vrste sortirajućih selekcija:
· linearno sortirajuća selekcija
· selekcije najboljih
Kod linearno sortirajuće selekcije vjerojatnost selekcije je proporcionalna rangu, odnosno poziciji jedinke u poretku jedinki sortiranih po dobroti. Svojstvo te selekcije je da i-ta jedinka ima i puta veću vjerojatnost selekcije od jedinke sa oznakom 1. Kada bi se nacrtao graf ovisnosti vjerojatnosti selekcije o rednom broju jedinke, točke koje predstavljaju vjerojatnost selekcije nalazile bi se na pravcu – otuda i naziv linearna selekcija. Vjerojatnost selekcije najbolje ili najlošije jedinke može biti unaprijed zadana. Ako se elitizmom štiti najbolja jedinka od eliminacije, vjerojatnost eliminacije najbolje jedinke treba biti jednaka nuli.
Selekcije najboljih odabiru unaprijed zadani broj najboljih jedinki. Moguće su tri vrste selekcije: (m+l) selekcija, (m,l) selekcija i krnja selekcija. Navedene podvrste selekcije najboljih međusobno se razlikuju prema skupu jedinki iz kojeg se odabiru najbolje jedinke. Najbolje jedinke mogu se birati iz skupa samo roditelja, roditelja i djece te samo djece. Prvo se odabiru slučajnim postupkom roditelji, a zatim se njihova djeca (zajedno ili bez roditelja) sortiraju i preživljavaju samo određeni broj najboljih jedinki. m je veličina populacije roditelja, a l je veličina populacije djece.
Kod (m+l) selekcije slučajno se odabire m roditelja iz populacije. Njihovim se križanjem stvara l djece. Iz skupa roditelja i djece se zatim najboljih m jedinki selektira za sljedeću generaciju. Postupak se ponavlja sve dok se ne popuni nova generacija s N novih jedinki.
Pri (m,l) selekciji također se slučajno odabire iz populacije m roditelja i njihovim križanjem se stvara l djece. Međutim, djece je više od roditelja (l ³ m) i m najbolje djece se selektira za sljedeću generaciju.
Krnja selekcija odabire n najboljih jedinki i kopira ih N/n puta.
Turnirske selekcije dijele se na:
· k-turnirske selekcije
· jednostavna turnirska selekcija
k-turnirska selekcija s jednakom vjerojatnošću odabire k jedinki između kojih selektira najbolju ili najlošiju jedinku. Generacijska turnirska selekcija N puta slučajno odabire k jedinki, između njih selektira najbolju jedinku i kopira je u međupopulaciju. Eliminacijska turnirska selekcija M puta odabire k jedinki i eliminira najlošiju među njima. Parametar k naziva se veličinom turnira. Prema veličini turnira, turnirske selekcije se dijele na binarnu turnirsku selekciju (k=2), 3-turnirsku selekciju, 4-turnirsku selekciju, itd. Za turnirsku selekciju nije potrebno sortirati jedinke, iako vjerojatnost selekcije ovisi o rangu jedinke, kao i kod sortirajućih selekcija. U postupku turnirske selekcije važan je samo međusobni odnos između k slučajno odabranih jedinki. Prema vrijednosti funkcije cilja određuje se za svaki par jedinki koja je od njih bolja, odnosno lošija. Najbolja jedinka ne može se nikako eliminirati s bilo kojom eliminacijskom turnirskom selekcijom, jer će k-1 ostalih slučajno odabranih jedinki sigurno biti lošije od najbolje jedinke. Elitizam je kod eliminacijskih turnirskih selekcija inherentno ugrađen, tj. vjerojatnost eliminacije najbolje jedinke jednaka je nuli.
Jednostavna turnirska selekcija je specifičan oblik eliminacijske binarne turnirske selekcije. U jednom koraku slučajnim postupkom se odabiru dva para jedinki. U svakom paru se lošija jedinka selektira za eliminaciju. Križanjem preživjelih jedinki generira se dvoje djece, koja se potom mutiraju i evaluiraju. Taj par novostvorenih jedinki nadomješćuju eliminirane jedinke. Na taj način genetski algoritam s jednostavnom turnirskom selekcijom u istom koraku obavlja i selekciju i reprodukciju.
3.5. Genetski operatori
U reprodukciji sudjeluju dobre jedinke koje su preživjele proces selekcije. Reprodukcija je razmnožavanje pomoću genetskog operatora križanja. Tijekom procesa reprodukcije dolazi i do slučajnih promjena nekih gena ili mutacije [3].
Križanje je binarni operator čija je funkcija razmjena genetskog materijala. U procesu križanja sudjeluju dvije jedinke koje se nazivaju roditelji. Križanjem nastaje jedna ili dvije nove jedinke koje se nazivaju djeca. Najvažnija karakteristika križanja je da djeca nasljeđuju svojstva svojih roditelja. Ako su roditelji dobri tada će najvjerojatnije i dijete biti dobro, ako ne i bolje od svojih roditelja. Ukoliko se kombinacijom gena dobije lošiji potomak, on će ionako biti potisnut postupkom selekcije.
Križanje može biti definirano sa proizvoljnim brojem prekidnih točaka. Gene između dvije susjedne prekidne točke potomak nasljeđuje od jednog roditelja. Slijedeći blok gena do iduće susjedne točke nasljeđuje od drugog roditelja. Uniformno križanje je križanje s b-1 prekidnih točaka (b je broj bitova). Primjer križanja s jednom točkom prekida prikazan je na slici 3.3.
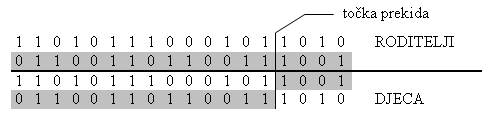
Slika 3.3. Križanje s jednom točkom prekida [3]
Pokazalo se korisnim provjeravati prije križanja da li su roditelji jednaki. Umjesto da se implementira posebni mehanizam otklanjanja duplikata, ovo je dobra prilika da se eliminacija duplikata izvede u okviru operatora križanja [3]. Ako su oba roditelja jednaka, mutira se jedan od roditelja, a dijete se dobiva slučajnim odabirom kromosoma.
Drugi genetski operator je mutacija. Osnovni cilj mutacije je slučajno unošenje raznolikosti u kromosome. Mutacija unosi elemente slučajnog traženja u genetske algoritme. Time svaka točka problemskog prostora ima barem malu vjerojatnost da bude posjećena.
Kod jednostavne mutacije, svaki gen potomaka mijenja se sa jako malom vjerojatnosti pm. Primjer jednostavne mutacije prikazan je na sljedećoj slici:

Slika 3.4. Jednostavna mutacija [3]
U jednostavnom genetskom algoritmu mutacija se primjenjuje nad djecom tj. jedinkama nastalim operatorom križanja. Postoji i miješajuća mutacija koje slučajno odabere kromosom iz populacije i ispremiješa mu gene.
4. OSTVARENI GENETSKI ALGORITAM
U ovom je poglavlju opisana programska implementacija genetskog algoritma za rješavanje problema rasporeda poslova [2]. Za svaki karakteristični dio genetskog algoritma, navodi se koja je varijanta izabrana.
Pretpostavlja se da je graf poslova topološki sortiran, odnosno za svaki par poslova (Ti, Tj) za koje vrijedi da je Ti prethodnik posla Tj slijedi da je indeks i manji od indeksa j. To znači da svi poslovi koji se moraju izvesti prije nekog posla imaju manji indeks od njega.
4.1. Predstavljanje rješenja
Svako rješenje (kromosom) je predstavljeno sa P sortiranih polja. Polje predstavlja niz poslova koji su dodijeljeni zadanom procesoru. Ako je to polje sortirano uzlazno po indeksima poslova, tada će uvjet prethođenja izvršavanja poslova samo na tom procesoru biti zadovoljen.
Na primjer, za graf sa slike 2.1. i P = 3, mogući kromosom je prikazan na slici 4.1.
|
S[1] |
2 |
4 |
5 |
6 |
|
|
S[2] |
1 |
7 |
9 |
|
|
|
S[3] |
3 |
8 |
10 |
|
|
Slika 4.1. Kromosom optimalnog rasporeda za graf sa slike 2.1. i 3 procesora
Kromosom ne predstavlja izravno raspored jer uvjet prethođenja poslova koji se nalaze na različitim procesorima nije zadovoljen. Pretvaranje kromosoma u raspored, odnosno računanje ukupnog trajanja izvršavanja poslova objašnjeno je u poglavlju 4.3.
4.2. Inicijalizacija i uvjet završetka
Neka je N veličina populacije tj. broj kromosoma u svakoj generaciji. Prilikom inicijalizacije slučajno se generira N početnih kromosoma. Kromosomi se generiraju po algoritmu [2] sa slike 4.2.
|
inicijalizacija(P(0)) { for(i=0;i<N;i++){ // N – veličina populacije for(j=1;j<=Z;j++){ // Z – broj poslova skup poslova koje obavlja r-ti procesor proširi poslom Tj; //r-random broj: rÎ[1,P] //P-broj procesora } evaluiraj(i-ti kromosom); } } |
Slika 4.2. Algoritam generiranja kromosoma
Uvjet završetka evolucijskog procesa je unaprijed zadani broj iteracija. Nakon isteka zadnje iteracije genetskog algoritma, jedinka koja ima najveću vrijednost funkcije dobrote u populaciji se ispisuje kao najbolje pronađeno rješenje.
4.3. Funkcija dobrote
Vrijednost funkcije dobrote za neki kromosom je određena negativnom vrijednošću završnog vremena rasporeda koje predstavlja taj kromosom. S obzirom da genetski algoritam nastoji maksimizirati vrijednost funkcije dobrote, istovremeno se nastoji minimizirati završno vrijeme rasporeda, tj. traži se kromosom čiji raspored ima najmanje vrijeme izvršavanja poslova. Da bi se od kromosoma tj. prezentacije rješenja dobio raspored, potrebno je vremenski rasporediti poslove unutar procesora, tako da se oni ne počnu izvršavati prije njihovih prethodnika koji se nalaze na drugim procesorima. Algoritam implementirane funkcije dobrote [2] prikazan je na slici 4.3.
|
evaluiraj(kromosom K){ for(i=1;i<=P;i++) FTP[i]=0; // FTP[i] – završno vrijeme procesora i for(i=1;i<=Z;i++){ // TiÎ{sets of tasks processor p}, pÎ[1,P] FTP[p] += trajanje_posla(Ti); for(j=1;j<=P;j++){ if(j == p) continue; // relacija prethođenja se testira u ovoj liniji: if(((TxÎj)<Ti ) && (FTP[j]>pom)) // x je najveći indeks posla koji se izvršava na procesoru p, // a koji zadovoljava uvjet x<j. FTP[p] = FTP[j] + Ti; } } FT=maxiÎ[1,P]{FTP[i]}; } |
Slika 4.3. Algoritam evaluacije kromosoma
Raspored poslova za kromosom sa slike 4.1. prikazan je na slici 4.4. Završno vrijeme tog rasporeda je 10 vremenskih jedinica.
|
S[1] |
2 |
4 |
5 |
6 |
|
|||||
|
S[2] |
1 |
7 |
|
9 |
|
|||||
|
S[3] |
|
3 |
8 |
10 |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
vrijeme |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
Slika 4.4. Raspored poslova za kromosom sa slike 4.1.
4.4. Selekcija
Za strategiju selekcije odabrana je eliminacijska turnirska selekcija. Slučajno se odabiru 3 jedinke, eliminira najlošija i nadomješta se djetetom dviju preživjelih jedinki [3]. To je uočljivo iz strukture implementiranog genetskog algoritma [2] koja je prikazana na slici 4.5.
|
genetski algoritam { inicijalizacija(P(0)); for(i=0,i<I;i++) { // I-broj iteracija slučajno odaberi tri kromosoma iz P(i); označi najgori kromosom za eliminaciju; križaj preživjele kromosome; mutiraj dijete; evaluiraj dijete; zamijeni eliminirani kromosom novim djetetom } } |
Slika 4.5. Struktura implementiranog genetskog algoritma
4.5. Genetski operatori
Implementirana su dva genetska operatora, križanje i mutacija. Rješenja tj. kromosomi su prikazani na adekvatniji način kako bi se jednostavnije objasnili genetski operatori. Umjesto sortiranih lista poslova, po jedna za svaki procesor, neka je svaki kromosom predstavljen jednom listom koja za svaki posao sadrži indeks procesora na kojem se on izvodi.
|
S[1] |
2 |
4 |
5 |
6 |
|
|
S[2] |
1 |
7 |
9 |
|
|
|
S[3] |
3 |
8 |
10 |
|
|
Slika 4.6. Prikaz kromosoma u implementiranoj verziji
Prilagođeni prikaz kromosoma:
|
Posao |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Procesor |
2 |
1 |
3 |
1 |
1 |
1 |
2 |
3 |
2 |
3 |
Slika 4.7. Prilagođeni prikaz kromosoma
Iz ovakvog se prikaza može jednostavno dobiti originalni prikaz. Prolaskom kroz sve poslove po uzlaznim vrijednostima indeksa, svaki posao stavljamo na kraj pripadne liste procesora na kojem se taj posao izvodi. Zbog načina prolaska kroz poslove, pripadne liste procesora također će biti sortirane uzlazno po vrijednostima indeksa poslova.
Za algoritam operatora križanja odabrano je uniformno križanje. Slučajnim postupkom stvara se maska križanja, binarni niz čija je duljina jednaka duljini kromosoma roditelja. Svaka binarna varijabla tog niza označava sa kojeg roditelja će se kopirati pojedini gen. Primjer križanja prikazan je na slici 4.8. Maska križanja za gen koji odgovara poslu broj 5 sadrži vrijednost "1", što znači da se taj gen kopira u dijete iz prvog roditelja. Gen za posao broj 6 će se uzeti sa drugog roditelja, jer je vrijednost maske za taj gen jednaka "0".
|
Posao |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Maska križanja |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Roditelj 1 |
2 |
1 |
3 |
2 |
1 |
1 |
2 |
2 |
2 |
3 |
|
|
|
|
|
¯ |
¯ |
|
|
¯ |
¯ |
|
|
Dijete |
1 |
3 |
2 |
2 |
1 |
3 |
3 |
2 |
2 |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Roditelj 2 |
1 |
3 |
2 |
2 |
1 |
3 |
3 |
2 |
3 |
3 |
Slika 4.8. Primjer uniformnog križanja
Kromosom rezultata križanja (dijete) u normalnom obliku prikazan je na slici 4.9.
|
S[1] |
1 |
5 |
|
|
|
|
S[2] |
3 |
4 |
8 |
9 |
|
|
S[3] |
2 |
6 |
7 |
10 |
|
Slika 4.9. Kromosom djeteta prikazan normalnim načinom
Ako su oba roditelja jednaka, nad jednim roditeljem se primjenjuje operator mutacije a dijete se stvara po slučajnom principu. Na taj način se eliminiraju duplikati. Ovakvom izvedbom križanja postiže se elitizam, tj. osigurava da će najbolji kromosom uvijek preživjeti i prijeći u sljedeću generaciju. Operator mutacije mijenja vrijednost gena s nekom određenom, unaprijed zadanom vjerojatnošću. Iako postoje inačice u kojima se vjerojatnost mutacije s vremenom povećava, u cilju boljeg istraživanja područja rješenja, implementirana je varijanta s fiksnom vjerojatnošću. Ako se nad genom primjenjuje mutacija, tada se posao koji odgovara tom genu prebacuje sa procesora kojem je dodjeljen na drugi, slučajno određeni, procesor. Primjer ilustriraju slike 4.10. i 4.11.
|
|
|
položaj mutacije |
|
|
||||||
|
|
|
¯ |
|
¯ |
|
|
|
|
|
|
|
Posao |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Dijete |
1 |
3 |
2 |
2 |
1 |
3 |
3 |
2 |
2 |
3 |
|
Mutirano dijete |
1 |
1 |
2 |
3 |
1 |
3 |
3 |
2 |
2 |
3 |
Slika 4.10. Primjer mutacije djeteta
|
S[1] |
1 |
2 |
5 |
|
|
|
S[2] |
3 |
8 |
9 |
|
|
|
S[3] |
4 |
6 |
7 |
10 |
|
Slika 4.11. Kromosom djeteta nakon mutacije prikazan normalnim načinom
4.6. Implementacija
Programska implementacija genetskog algoritma za rješavanje problema rasporeda (nadalje: GA program) napisana je u jeziku C/C++ [2]. U okviru rada je GA program prilagođen za prevođenje u razvojnoj okolini Microsoft Visual C++ 6.0 i prepravljen da bi se mogao uspješno prevesti i pokrenuti. Sve promjene u GA programu su komentirane i potpisane u izvornom kodu. Pregled svih izmjena je zapisan u datoteci promjene.txt.
Program se pokreće iz komandne linije, na sljedeći način:
C:\>GA ulazna_datoteka izlazna_datoteka
Ulazna datoteka sadrži parametre genetskog algoritma te referencu na drugu datoteku sa samim opisom problema u Prototype Standard Task Graph formatu zapisa. Popis parametara i njihovo značenje navedeno je u tablici 4.1.
Tablica 4.1. Parametri genetskog algoritma
|
Parametar |
Predviđena
vrijednost |
Opis |
|
A |
0 |
Vrsta selekcije, 0
označava turnirsku selekciju |
|
P |
1 |
Broj dretvi |
|
VELPOP |
10-1000 |
Velicina populacije |
|
K_MUT |
0-30‰ |
Vjerojatnost
mutacije u promilima |
|
I |
1000-100000 |
Broj iteracija |
|
J |
1 |
Broj vrsta (koliko
puta se pokreće proces evolucije) |
|
O |
broj |
Ispis svakih x
iteracija |
|
S |
F |
Format ispisa, F
označava vrijednost funkcije cilja najboljeg kromosoma u iteraciji |
|
<datoteka> |
|
Ime datoteke sa
definicijom problema rasporeda u prototype formatu |
Izlazna datoteka sadrži nužne informacije o broju poslova i broju procesora te sam raspored poslova na procesore. Za svaki posao se definira trajanje posla, na kojem procesoru se izvodi te vremenski trenutak početka izvršavanja posla na tom procesoru. Na slikama 4.12. i 4.13. prikazana je ulazna datoteka i izvršavanje programa za primjer grafa poslova sa slike 2.2.
|
# /***********/ # /* ZADATAK */ # /***********/ # ======================================================================== # vrsta GA, PGA, definicija problema rasporeda ############################################## # A 0 /* 0 = Turnirska selekcija i nema potrebe za drugim */ # P 1 /* Broj dretvi, idealno: P = broj procesora */ # # parametri GA ############## # VELPOP 4 /* velicina populacije */ # K_MUT 10 /* vjerojatnost mutacije u promilima */ # I 50 /* broj iteracija */ # J 1 /* broj vrsta */ # O 2 /* ispisi svakih x iteracija */ # # ispis ####### # S F /* ispisuj samo vrijednost funkcije cilja */ # # definicija zadatka, tj. problema rasporeda ############################################ # "primjer.stg" /* datoteka sa opisom grafa poslova u prototype formatu */ |
Slika 4.12. Primjer ulazne datoteke genetskog
algoritma
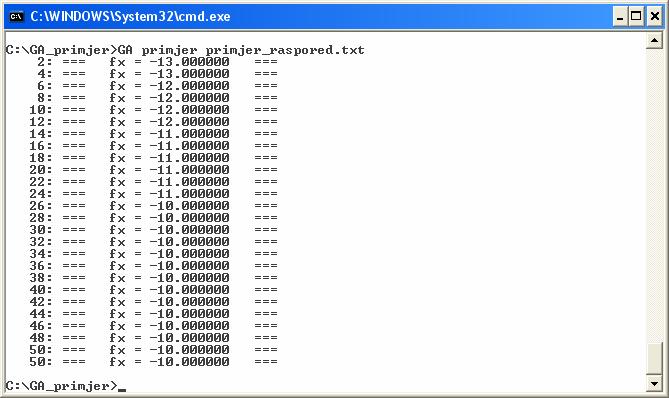
Slika 4.13. Primjer izvršavanja genetskog algoritma
Implementacija genetskog algoritma zapisana je u pet datoteka:
· main.cpp – glavna funkcija programa
· glava.h – sadrži deklaracije struktura i konstanti
· kromosom.cpp – implementacija strukture kromosom
· populaci.cpp – implementacija strukture populacija
· funkcije.cpp – sadrži pomoćne funkcije
Glavna funkcija programa inicijalizira generator slučajnih brojeva, poziva funkciju za učitavanje parametara iz ulaznih datoteka i nakon toga poziva funkciju vrsta() odgovarajući broj puta, kako je prikazano na slici 4.14.
|
/********************************************************/ /* MAIN.C - "GA stroj" za rješavanje PROBLEMA RASPOREDA */ /********************************************************/ #include "glava.h" int BR_VRSTA; char *ime_dat; char *ime_izl_dat; //Ognjen: dodao za potrebu grafickog prikaza rasporeda int main(int argc,const char *argv[]){ int i; init_sluc(); // inicijalizacija generatora sluc. brojeva if( argc==3 ) { ime_dat = (char *)argv[1]; ime_izl_dat = (char *)argv[2]; //Ognjen: dodao za potrebu grafickog prikaza } else{ printf("Treba navesti imena ulazne i izlazne datoteke\n"); exit(1); } ucitaj_parametre(); for(i=0;i<BR_VRSTA;i++) vrsta(); // neka zive razne vrste return 1; } |
Slika 4.14. Glavni dio programa
Sučelje strukture kromosom nalazi se u datoteci glava.h:
|
struct KROMOSOM{ public: int mbr; // mbr kromososma int z,p,*k; // broj zadataka i procesora, kromosom double fx; // vrijednost funkcije cilja kromosoma KROMOSOM(void); // konstuktor KROMOSOM(const KROMOSOM &); // copy konstruktor ~KROMOSOM(void); // destruktor void ispisi(void); //ispis sadrzaja kromosoma void ispisi_detaljno(void); // ispisuje raspored kromosoma u izlaznu datoteku void operator =(const KROMOSOM &); // operator pridjeljivanja KROMOSOM operator +(KROMOSOM &); // genetski operator krizanje void operator <=(int); // genetski operator mutacija void evaluiraj(void); // evaluacija kromosoma, racuna zavrsno vrijeme rasporeda private: void umetni(int,int); // ubacuje zadani posao u dani procesor void izbaci(int,int); // izbacije zadani posao sa danog procesora int gdje_je(int); // trazi kojem procesoru je dodijeljen zadani posao }; |
Slika 4.15. Sučelje strukture kromosom
Sučelje strukture populacija prikazano je na sljedećoj slici:
|
class POPULACIJA{ int VEL_POP, // velicina populacije public: KROMOSOM *a[MAX_VPOP]; // polje kromosoma za predstavljanje populacije POPULACIJA(int); // konstuktor ~POPULACIJA(); // destuktor void ispisi(void); // ispisuje vrijednost funkcije cilja najboljeg kromosoma int najbolji(void); // vraca indeks najboljeg kromosoma void TurnirGA(void); // izvrsava jedan turnir void Zivite_i_mnozite_se(void); // glavna funkcija, radi jedan evolucijski proces }; |
Slika 4.16. Sučelje strukture populacija
U datoteci funkcije.cpp nalazi se funkcija vrsta koja kreira početnu populaciju i pokreće proces evolucije kromosoma:
|
void vrsta(void){ p = (POPULACIJA*)new POPULACIJA(V_POP); // inicijalizacija populacije p p->Zivite_i_mnozite_se(); // poziva glavnu funkciju populacije delete p; // destruktor populacije } |
Slika 4.17. Implementacija funkcije vrsta()
5. APLIKACIJA ZA GRAFIČKI PRIKAZ RASPOREDA
U okviru praktičnog dijela rada izrađena je aplikacija za grafički prikaz rješenja GA programa, nazvan “Grafički Prikaz Rasporeda” (nadalje: GPR). Aplikacija je napisana u jeziku C#, u programskom alatu Microsoft Visual Studio .NET.
Program Grafički Prikaz Rasporeda na jednostavan način prikazuje raspored poslova te nudi osnovne informacije o rasporedu: broj poslova, broj procesora, završno vrijeme rasporeda te prosječno iskorištenje procesora. Grafički prikaz rasporeda se sastoji od više traka, po jedna za svaki procesor. U traci su pojedini poslovi prikazani pravokutnikom. Poslovi su naizmjence obojani dvjema osnovnim bojama kako bi se raspoznala granica između poslova. Za svaki posao dostupne su dodatne informacije o njemu (redni broj posla, trajanje posla te vrijeme početka izvršavanja) u obliku hinta, teksta koji se pojavljuje kada se pokazivač zadrži neko vrijeme nad prostorom grafičkog prikaza posla. Program GPR se poziva iz komandne linije na način:
C:\>GPR ulazna_datoteka
Ulazna datoteka u GPR program je izlazna datoteka programa GA.
Izgled aplikacije za raspored poslova sa slike 4.4. prikazan je na slici 5.1.
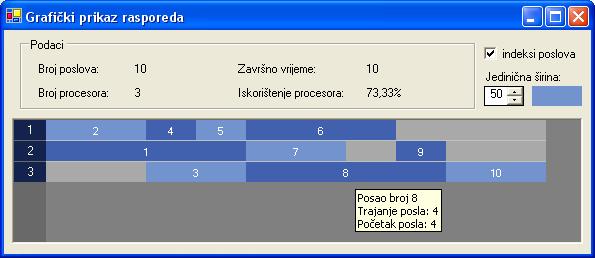
Slika 5.1. Grafički prikaz rasporeda sa slike 4.4.
U gornjem dijelu prozora nalaze se osnovne informacije o rasporedu: broj poslova, broj procesora, završno vrijeme rasporeda te prosječno iskorištenje procesora. Desno od informacija nalazi se kontrola kojom se regulira širina jedne vremenske jedinice.
U donjem dijelu prozora je grafički prikaz rasporeda. Svakom procesoru dodijeljena je traka na čijem lijevom kraju piše broj procesora. U traci se prikazuju poslovi dodijeljeni procesoru. Poslovi su prikazani kao pravokutnici čija je duljina proporcionalna trajanju posla. Poslovi u jednoj traci bojaju se naizmjence sa dvije boje, kako bi se vizualno prikazala granica između dva posla. Svaki posao na sebi ima prikazan indeks. Dodatne informacije o poslu prikazuju se u pomoćnom info prozorčiću koji se pojavi kada se kursor zadrži iznad područja posla. Da bi raspored bio pregledan i u slučaju većeg broja poslova, moguće je isključiti ispis indeksa poslova.
6. ISPITIVANJE GENETSKOG ALGORITMA
Cilj ispitivanja primjenjenog genetskog algoritma je:
· odrediti utjecaj broja iteracija na kvalitetu dobivenih rješenja
· odrediti utjecaj veličine populacije na kvalitetu dobivenih rješenja
· odrediti utjecaj vjerojatnosti mutacije na kvalitetu dobivenih rješenja
Da bi se eksperimentiranjem dobili referentni rezultati, korišten je standardni skup grafova poslova dostupan na [9]. Za ispitivanje genetskog algoritma odabrana su dva grafa poslova, čije su karakteristike navedene u tablici 6.1.
Tablica 6.1. Karakteristike ispitnih grafova poslova [9]
|
Naziv
datoteke grafa poslova |
proto000.stg |
proto065.stg |
|
Broj poslova |
452 |
681 |
|
Broj procesora |
20 |
6 |
|
Optimalno završno vrijeme |
537 |
1196 |
Prvi graf poslova, nazovimo ga proto000.stg, odabran je da bi se rezultati eksperimentiranja mogli usporediti s poznatim rezultatima iz [2], budući se u tom radu koristio isti graf poslova. Kako bi se ispitalo ponašanje genetskog algoritma u slučaju većeg broja poslova a manje procesora, za drugi graf poslova odabran je proto065.stg. Skraćeni sadržaji datoteka sa grafovima poslova prikazani su na slikama 6.1. i 6.2.
6.1. Parametri izvođenja genetskog algoritma
U traženju globalnog optimuma mogu se koristiti dvije tehnike:
· pretraživanje - ispitivanje novih područja problemskog prostora
· iskorištavanje - korištenje znanja stečenog u prethodno ispitanim točkama za pronalaženje boljih točaka
Budući su zahtjevi ovih dvaju tehnika kontradiktorni, kvalitetna tehnika optimiranja mora pronaći pravi kompromis među njima. Slučajno pretraživanje je metoda koja ima izrazito svojstvo pretraživanja, ali nema iskorištavanja prije stečenog znanja. Gradijentne metode dobro iskorištavaju znanje o pronađenim točkama, ali slabo pretražuju problemski prostor. Kombinacija dviju tehnika trebala bi dati dobre rezultate, ali problem je kako postići ravnotežu među njima.
Genetski algoritmi koriste obje metode primjenom genetskih operatora. Mutacija osigurava istraživanje novih područja problemskog prostora, dok križanje omogućava korištenje prethodno stečenog znanja. Budući je genetski algoritam u principu jednostavan, za optimalni omjer istraživanja i iskorištavanja potrebno je podesiti parametre algoritma.
Parametri za podešavanje korištenog genetskog algoritma su: veličina populacije (N), vjerojatnost mutacije (pm) i broj iteracija (I). Veličina populacije utječe na kvalitetu rješenja. Za postizanje rješenja iste kvalitete uz veću populaciju, potrebno je više iteracija [8]. Populacija predstavlja pronađene točke, stoga veličina populacije utječe na svojstvo iskorištavanja. S druge strane, vjerojatnost mutacije utječe na svojstvo pretraživanja.
|
452 20 1 6 0 2 3 0 3 12 0 4 12 0 5 9 0 6 5 1 5 7 5 0 8 11 1 2 9 10 0 10 9 1 5 11 9 0 12 12 0 13 5 0 14 12 0 15 7 3 2 10 12 . . . 443 7 12 24 26 35 116 163 180 212 227 232 250 425 ... 444 14 12 50 211 280 300 306 335 350 381 390 409 431 ... 445 11 8 8 17 221 231 259 336 377 396 446 6 13 9 117 155 159 172 318 352 387 399 403 410 ... 447 4 18 7 23 37 41 153 157 185 236 241 245 293 ... 448 12 14 1 133 151 165 215 219 220 258 260 287 306 ... 449 14 13 31 80 109 150 246 314 360 363 371 418 422 ... 450 11 9 109 194 222 294 326 409 425 433 440 451 2 14 131 141 151 174 203 237 241 352 374 402 406 ... 452 9 14 61 78 108 131 152 166 183 192 196 210 242 ... 453 0 20 380 405 417 423 424 427 430 432 437 438 441 ... |
Slika 6.1. Prvi ispitni graf poslova - proto000.stg
|
681 6 1 18 0 2 11 1 1 3 20 0 4 3 0 5 15 0 6 15 0 7 5 0 8 12 0 9 12 0 10 13 0 11 18 1 1 12 3 0 13 14 1 10 14 15 0 15 5 0 . . . 673 3 12 202 203 328 433 469 490 530 534 537 557 566 ... 674 13 13 36 156 248 252 296 319 391 479 566 573 592 ... 675 20 21 157 196 225 230 291 292 294 300 406 412 444 ... 676 1 18 128 180 190 194 243 323 358 373 405 409 422 ... 677 2 16 56 184 253 340 348 372 383 430 443 523 555 ... 678 14 15 55 204 257 263 291 347 377 452 503 516 536 ... 679 8 17 162 196 290 292 321 382 405 479 502 518 523 ... 680 19 19 49 128 166 205 293 296 318 324 357 409 417 ... 681 15 16 47 49 82 149 193 210 241 320 362 402 455 ... 682 0 26 544 579 580 595 614 627 644 648 650 651 656 ... |
Slika 6.2. Drugi ispitni graf poslova - proto065.stg
Broj iteracija genetskog algoritma ograničen je na sto tisuća. Trajanje izvođenja za taj broj iteracija je približno sat vremena. Kako bi se pokrio veći opseg veličina populacija, korištene su sljedeće vrijednosti: 10, 20, 40, 80, 200, 500 i 1000 jedinki. Prilikom ispitivanja utjecaja veličine populacije na konvergenciju, vjerojatnost mutacije je bila konstantna i iznosila 10‰. Za utvrđivanje utjecaja vjerojatnosti mutacije na konvergenciju korišten je sljedeći postupak:
1. Za konstantne vrijednosti parametara veličine populacije i broja iteracija grubo se odredilo u kojem području genetski algoritam daje najbolje rezultate. Preciznost vjerojatnosti mutacije u ovom koraku je u postocima. Korištene su vrijednosti: 0‰, 10‰ i 20‰.
2. Ovisno uz koju vjerojatnost mutacije iz prethodnog koraka su dobiveni najbolji rezultati, odgovarajući interval vjerojatnosti se dalje dijelio na manje podintervale. U ovom koraku korištene su sljedeće vjerojatnosti mutacije: 2‰, 4‰, 7‰, 13‰ i 16‰.
6.2. Rezultati eksperimentiranja
Eksperimentiranjem se nastojao utvrditi optimalan iznos veličine populacije za pojedine iznose broja iteracija. Za svaki iznos veličine populacije, genetski algoritam je pokrenut sedam puta. Vrijednost funkcije cilja ispisivala se svakih tisuću iteracija kako bi se odredio utjecaj parametara algoritma na konvergenciju. Srednje vrijednosti funkcije cilja zabilježene su u tablicama.
Rezultati eksperimentiranja za prvi graf poslova navedeni su u tablici 6.2.
Tablica 6.2. Srednja vrijednost funkcije cilja najboljih jedinki u 7 eksperimenata
za određeni broj iteracija i veličinu populacije
|
proto000.stg |
|||||||
|
broj |
veličina populacije |
||||||
|
iteracija |
10 |
20 |
40 |
80 |
200 |
500 |
1000 |
|
0 |
732,1 |
720,0 |
713,3 |
697,4 |
695,6 |
680,8 |
672,8 |
|
3000 |
597,5 |
600,9 |
589,1 |
597,6 |
627,3 |
655,5 |
660,4 |
|
5000 |
594,9 |
593,3 |
576,8 |
579,9 |
601,5 |
634,1 |
650,6 |
|
7000 |
593,1 |
592,5 |
570,0 |
574,0 |
588,8 |
623,4 |
639,9 |
|
10000 |
593,0 |
590,4 |
568,3 |
566,9 |
576,1 |
607,5 |
630,5 |
|
15000 |
591,5 |
590,1 |
566,1 |
562,5 |
565,4 |
590,3 |
613,9 |
|
30000 |
585,8 |
590,1 |
566,0 |
561,1 |
556,3 |
569,4 |
586,1 |
|
50000 |
578,1 |
590,1 |
566,0 |
561,1 |
555,1 |
560,1 |
567,8 |
|
70000 |
574,3 |
590,1 |
566,0 |
561,0 |
554,5 |
556,4 |
558,5 |
|
100000 |
574,1 |
590,1 |
566,0 |
561,0 |
554,4 |
555,5 |
553,3 |
Rezultati iz tablice 6.2. prikazani su na dva načina na slikama 6.3. i 6.4. Na slici 6.3. prikazana je ovisnost dobivene kvalitete rješenja o broju iteracija. Prikazana je cijela evolucija rješenja za 105 iteracija. Kvaliteta rješenja je veća što je srednja vrijednost dobivenih rješenja manja. Slika 6.4. prikazuje ovisnost kvalitete rješenja o veličini populacije.
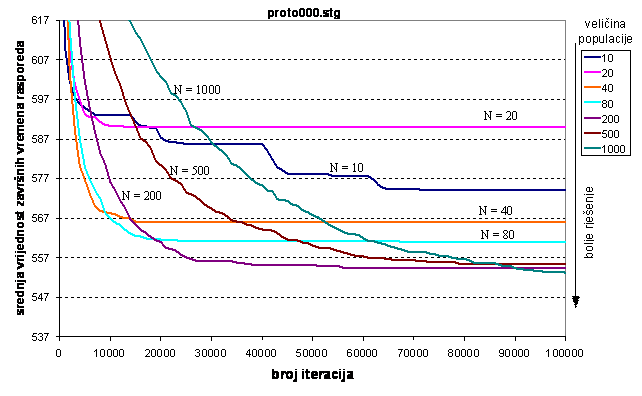
Slika 6.3. Evolucija rješenja u ovisnosti o
veličini populacije
Veličina populacije 20 jedinki je premala pa genetski algoritam konvergira k lokalnom optimumu i u njemu ostaje. Za 10 jedinki također konvergira k lokalnom optimumu međutim u njemu ne ostaje, već svakih nekoliko tisuća iteracija otkriva bolja rješenja zahvaljujući operatoru mutacije. Na slici se to može vidjeti u obliku naglih padova krivulje. Za veličine populacije od 40 i 80 jedinki konvergencija je znatno brža i postižu se bolja rješenja, međutim ne postižu se zadovoljavajuća rješenja. Što je populacija veća to je sporija konvergencija ali je vjerojatnost zaglavljivanja u lokalnom optimumu manja i za dovoljan broj iteracija postiže se bolje rješenje. Za populaciju od 200 jedinki postiže se zadovoljavajuće rješenje već za 25000 iteracija. Za populaciju od 500 jedinki potrebno je primjerice 60000 iteracija a populaciju od 1000 jedinki treba 80000 iteracija da bi se postiglo isto rješenje. Broj iteracija 90000 je za veličinu populacije od 1000 jedinki premalo, jer genetski algoritam sa 200 jedinki postiže isto rješenje za jednaki broj iteracija.
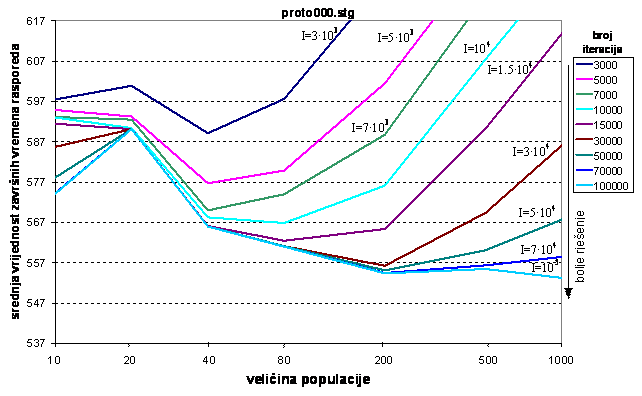
Slika 6.4. Kvaliteta rješenja u ovisnosti o veličini populacije i broju iteracija
Na slici 6.4. se vidi da se za veće populacije postiže bolje rješenje, ali za znatno veći broj iteracija. Na primjer, za 5000 iteracija, optimalna veličina populacije je oko 40 jedinki. Za veće populacije, npr. od 200 jedinki potrebno je barem 30000 iteracija kako bi se postiglo bolje rješenje od manjih populacija. S druge strane, ne isplati se povećavati broj iteracija, a veličinu populacije ostaviti na istoj vrijednosti. Ako se već odradi 30000 iteracija, onda je populacija od 80 jedinki premala jer se bolje rješenje postiže za 200 jedinki. Iz slike 6.4. se vidi da su krivulje konkavne, osim za dio krivulja koji se odnosi na veličinu populacije od 10 jedinki. To je posljedica otkrivanja novih, boljih rješenja nakon kratkog zadržavanja u lokalnom optimumu. Na temelju eksperimenata zaključuje se da kvaliteta konvergencije značajno ovisi o veličini populacije i broju iteracija. Kod većih iznosa iteracija postižu se bolji rezultati primjenom većih populacija. Vjerojatnost mutacije se za vrijeme eksperimentiranja držala konstantnom, na iznosu 10‰.
Da bi se utvrdio utjecaj vjerojatnosti mutacije odabrane su dvije kombinacije broja iteracija i veličine populacije. Za prvi par odabran je broj iteracija 20000 i veličina populacije 80, budući da se s njom postižu najbolja rješenja do tog broja iteracija. Analiza slike 6.3. pokazuje da je za drugi par najbolje odabrati 60000 iteracija i veličinu populacije 200 jedinki. Prosječne vrijednosti dobivenih rješenja navedene su u tablici 6.3.
Tablica 6.3. Srednja vrijednost funkcije cilja za različite vjerojatnosti mutacije
|
proto000.stg |
||||||||
|
broj iteracija, |
Vjerojatnost mutacije |
|||||||
|
veličina populacije |
0 |
2 |
4 |
7 |
10 |
13 |
16 |
20 |
|
I=20000, N=80 |
655,4 |
- |
567,9 |
566,6 |
557,0 |
565,7 |
571,3 |
573,2 |
|
I=60000, N=200 |
646,1 |
559,6 |
559,1 |
553,6 |
560,7 |
- |
- |
566,6 |
Podaci iz tablice prikazani su grafički na slici 6.5.
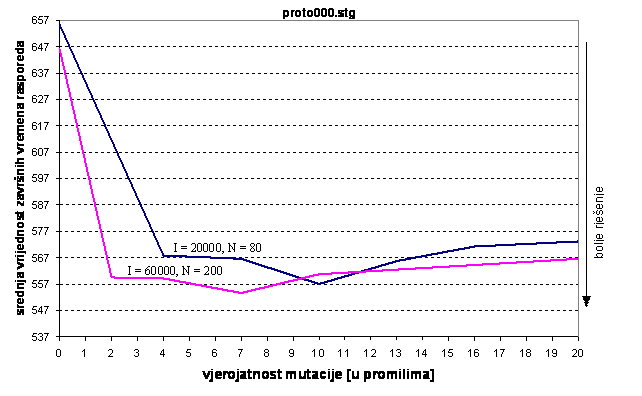
Slika 6.5. Kvaliteta rješenja u ovisnosti o vjerojatnosti mutacije
Iz slike 6.5. je uočljivo da se uz 20000 iteracija i veličinu populacije od 80 jedinku najbolji rezultati postižu za vjerojatnost mutacije oko 10 promila. Za veću populaciju, od 200 jedinki optimalna vjerojatnost mutacije je manja i iznosi oko 7 promila.
Rezultati eksperimentiranja za drugi graf poslova navedeni su u tablici 6.4.
Tablica 6.4. Srednja vrijednost funkcije cilja za određeni broj iteracija i veličinu populacije
|
proto065.stg |
|||||||
|
broj |
veličina populacije |
||||||
|
iteracija |
10 |
20 |
40 |
80 |
200 |
500 |
1000 |
|
0 |
2116,8 |
2088,2 |
2082,4 |
2020,2 |
2022,9 |
1990,1 |
1984,8 |
|
3000 |
1849,4 |
1823,3 |
1790,4 |
1804,1 |
1879,8 |
1932,0 |
1959,8 |
|
5000 |
1847,4 |
1810,2 |
1764,1 |
1766,7 |
1824,1 |
1897,1 |
1940,2 |
|
7000 |
1831,4 |
1806,2 |
1752,7 |
1746,5 |
1793,0 |
1855,0 |
1906,3 |
|
10000 |
1829,3 |
1804,1 |
1746,1 |
1729,3 |
1759,8 |
1825,3 |
1882,7 |
|
15000 |
1829,3 |
1802,6 |
1740,0 |
1714,6 |
1728,3 |
1790,8 |
1843,1 |
|
30000 |
1790,8 |
1802,5 |
1737,7 |
1704,8 |
1696,3 |
1726,2 |
1771,2 |
|
50000 |
1776,1 |
1802,5 |
1737,0 |
1703,8 |
1681,7 |
1697,0 |
1724,9 |
|
70000 |
1774,8 |
1785,6 |
1736,4 |
1703,3 |
1676,3 |
1683,6 |
1700,8 |
|
100000 |
1770,6 |
1741,8 |
1736,4 |
1703,2 |
1673,5 |
1672,3 |
1676,8 |
Kao i za prvi graf poslova, rezultati iz tablice 6.4. prikazani su na dvije slike, 6.6. i 6.7.
Slika
6.6. Evolucija rješenja u ovisnosti o
veličini populacije
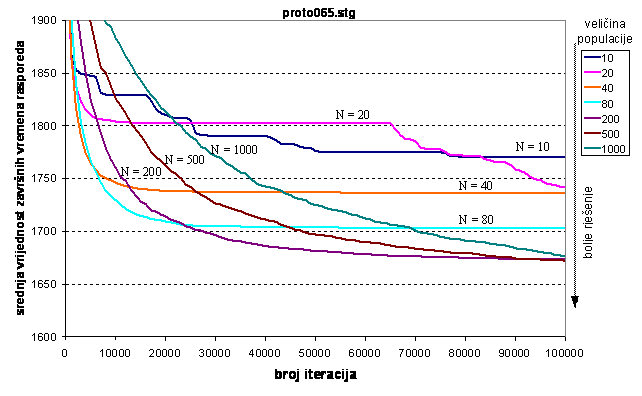
Uz male veličine populacije algoritam konvergira k lokalnom optimumu ali za razliku od prvog grafa poslova, događa se nagli proboj kod dvije veličine populacija od 10 i 20 jedinki. Za veličine populacije od 40 i 80 jedinki algoritam brže konvergira ali i brzo zaglavi u lokalnom optimumu. Obećavajuće su veličine populacija od 200, 500 i 1000 jedinki budući da one konvergiraju do zadnje iteracije. Uzevši u obzir da završno vrijeme optimalnog rasporeda iznosi mnogo manje od dobivenih rješenja (1196 naspram dobivenih 1673), rješenja nisu zadovoljavajuća. Za veličine populacije 500 i 1000 jedinki, 100000 iteracija je premalo budući da se rješenje iste kvalitete postiže sa veličinom populacije 200 jedinki.
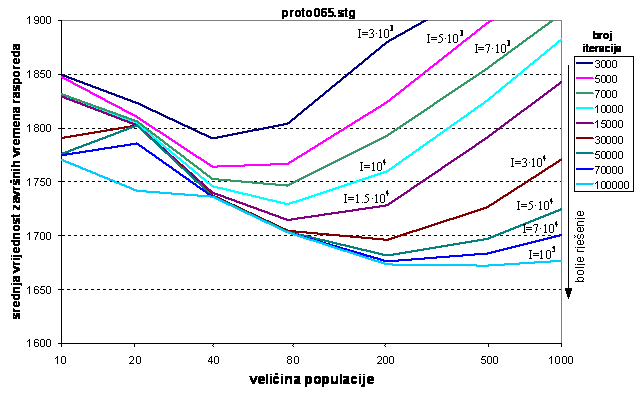
Na slici 6.7. vidi se da je se do 3000 iteracija postižu najbolji rezultati uz veličinu populacije 40. Ta veličina populacije je premala za veće iznose iteracija, što se vidi premještanjem minimuma krivulja udesno kako se povećava broj iteracija. Za interval od 7000 do 15000 iteracija optimalno je izabrati veličinu populacije 80 jedinki. Za 30000 i više iteracija najbolja rješenja daje populacija od 200 jedinki.
Slika 6.7. Kvaliteta rješenja u ovisnosti o veličini populacije i broju iteracija
Za mjerenje utjecaja vjerojatnosti mutacije korištene su iste vrijednosti parametara kao i za prvi graf poslova: 20000 iteracija s veličinom populacije 80 i 60000 iteracija s populacijom 200. Srednje vrijednosti završnih vremena rješenja navedene su u tablici.
Tablica 6.5. Srednja vrijednost funkcije cilja za različite vjerojatnosti mutacije
|
proto065.stg |
||||||||
|
broj iteracija, |
Vjerojatnost mutacije |
|||||||
|
veličina populacije |
0 |
2 |
4 |
7 |
10 |
13 |
16 |
20 |
|
I=20000, N=80 |
1940,5 |
- |
1701,5 |
1682,3 |
1718,7 |
1748,0 |
1760,9 |
1787,5 |
|
I=60000, N=200 |
1925,3 |
1643,3 |
1636,4 |
1659,1 |
1678,7 |
- |
- |
1759,1 |
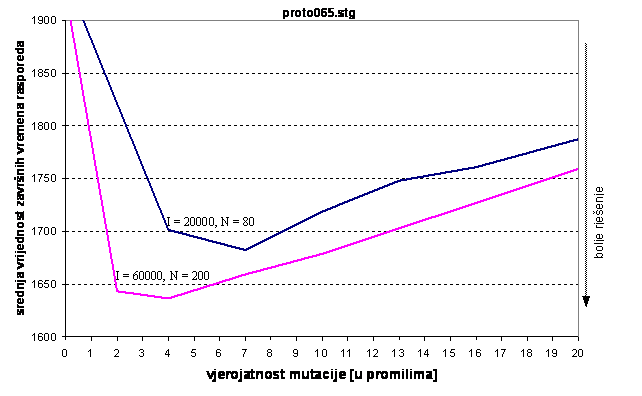
Podaci iz tablice prikazani su grafom na slici 6.8. Za 20000 iteracija i 80 jedinki najbolja rješenja postižu se uz vjerojatnost mutacije oko 7 promila. Uz veličinu populacije 200 jedinki i 60000 iteracija, optimalno je odabrati vjerojatnost mutacije oko 4 promila. U odnosu na prvi graf poslova, optimalne vrijednosti mutacije za iste kombinacije broja iteracija i veličine populacije manje su nego u ovom slučaju.
Slika 6.8. Kvaliteta rješenja u ovisnosti o vjerojatnosti mutacije
6.3. Grafički prikaz dobivenih rješenja
Kako bi se grafički predočili rezultati optimiranja, na sljedećim slikama prikazani su rasporedi poslova dobiveni prilikom ispitivanja genetskog algoritma. Za oba ispitna grafa poslova odabrana su po tri karakteristična rješenja:
· neoptimirano rješenje – slučajno rješenje t.j. rješenje dobiveno za nula iteracija
· najlošije rješenje – rješenje s najkasnijim završnim vremenom rasporeda
· najbolje rješenje – rješenje s najranijim završnim vremenom rasporeda
Najlošije rješenje odabrano je među svim rješenjima dobivenim uz 100000 iteracija i razne veličine populacije. Najbolje rješenje odabrano je među svim rješenjima dobivenim prilikom eksperimentiranja.
Neoptimirano rješenje za prvi graf poslova dobiveno je uz 0 iteracija, veličinu populacije 10 jedinki i vjerojatnost mutacije 10‰. Raspored je prikazan na slici 6.9. Završno vrijeme tog rasporeda je 770 vremenskih jedinica.
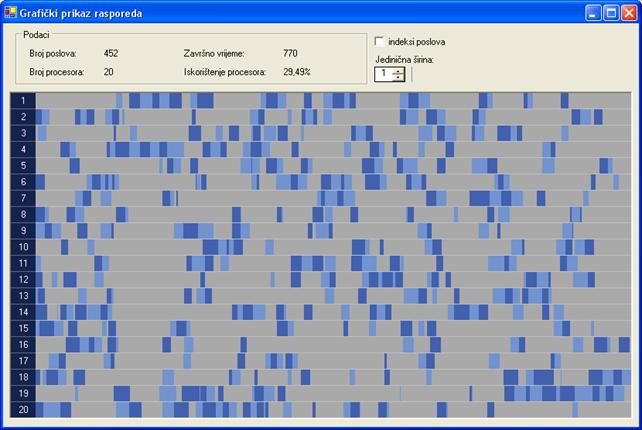
Slika 6.9. Neoptimirano rješenje za proto000.stg (FT=770; I=0, N=10, pm=10‰)
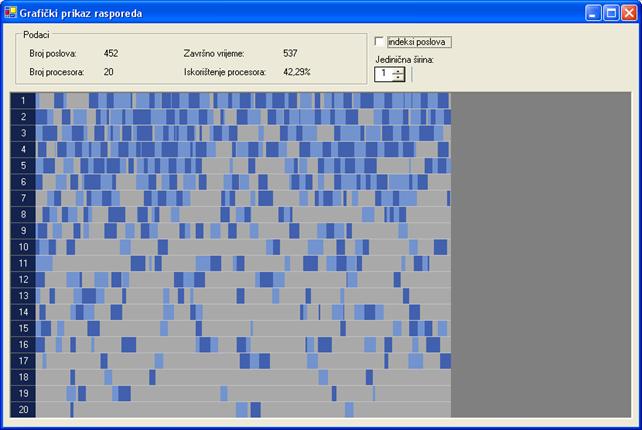
Završno vrijeme rasporeda najlošijeg rješenja za prvi graf poslova je 705 vremenskih jedinica. Rješenje je dobiveno uz 100000 iteracija, veličinu populacije 20 jedinki i vjerojatnost mutacije 10‰. Raspored je prikazan na slici 6.10. Najbolje rješenje ujedno je i optimalno, a dobiveno je uz 30000 iteracija, veličinu populacije 80 jedinki i vjerojatnost mutacije 10‰. Optimalni raspored prikazan je na slici 6.11. Završno vrijeme rasporeda je 537 vremenskih jedinica.
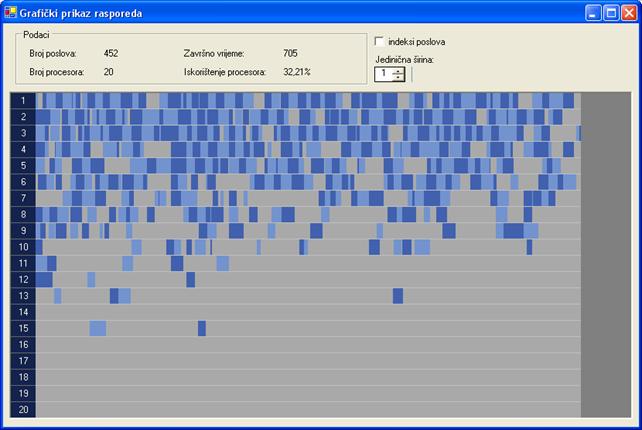
Slika 6.10. Najlošije rješenje za proto000.stg (FT=705; I=100000, N=20, pm=10‰)
Slika
6.11. Optimalno rješenje za proto000.stg
(FT=537; I=30000, N=80, pm=10‰)
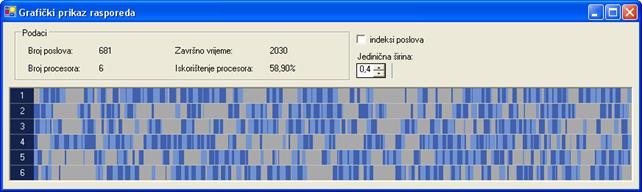
Kako bi se rasporedi za drugi graf poslova mogli prikazati u cjelosti, parametar aplikacije jedinična širina smanjen je na 0,4. Neoptimirano rješenje dobiveno je s 0 iteracija, veličinom populacije 10 jedinki i vjerojatnošću mutacije 10‰. Završno vrijeme rasporeda neoptimiranog rješenja iznosi 2030 vremenskih jedinica. Raspored je prikazan na slici 6.12.
Slika 6.12. Neoptimirano rješenje za proto065.stg (FT=2030; I=0, N=10, pm=10‰)
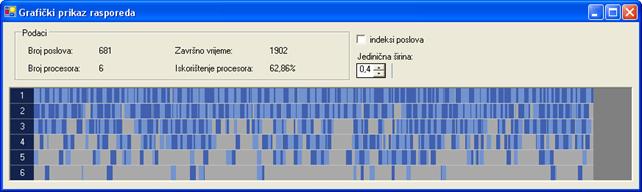
Na slici 6.13. prikazan je raspored najlošijeg rješenja za drugi graf poslova. Završno vrijeme iznosi 1902 vremenske jedinice. Rješenje je dobiveno uz 100000 iteracija, veličinu populacije 40 jedinki i vjerojatnost mutacije 10‰.
Slika 6.13. Najlošije rješenje za proto065.stg (FT=1902; I=100000, N=40, pm=10‰)
Završno vrijeme rasporeda najboljeg rješenja za drugi graf poslova iznosi 1613 vremenskih jedinica. Najbolje rješenje dobiveno je uz 100000 iteracija, veličinu populacije 200 jedinki i vjerojatnost mutacije 4‰. Raspored tog rješenja prikazan je na slici 6.14.
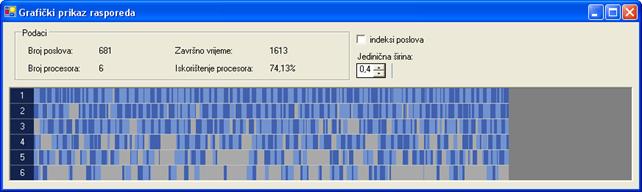
Slika 6.14. Najbolje rješenje za proto065.stg (FT=1613; I=100000, N=200, pm=4‰)
6.4. Analiza rezultata
Veličina populacije i broj iteracija su međusobno zavisni. Za veću populaciju treba odraditi više iteracija kako bi se postiglo rješenje iste kvalitete. Osim što se za veće populacije treba obaviti više iteracija i vjerojatnost mutacije mora biti manja. Prema tome, svi su parametri genetskog algoritma međusobno zavisni. Drugim riječima, promjenom jednog parametra moraju se podesiti svi ostali parametri, želi li se zadržati ista kvaliteta dobivenog rješenja. Predloženi skup parametara za primjenjeni genetski algoritam naveden je u tablici 6.6.
Tablica 6.6. Predloženi skup parametara
|
Broj iteracija I |
Veličina populacije N |
Vjerojatnost mutacije pm [‰] |
|
1000 - 30000 |
80 |
7-10 |
|
30000 - 100000 |
200 |
4-7 |
Optimalni raspored dobiven je samo za prvi graf poslova i to u sedmom testu za veličinu populacije 80 jedinki. Zanimljivo je da se optimum pronašao već nakon 17000 iteracija. Konvergencija algoritma za taj test prikazana je na slici 6.15.
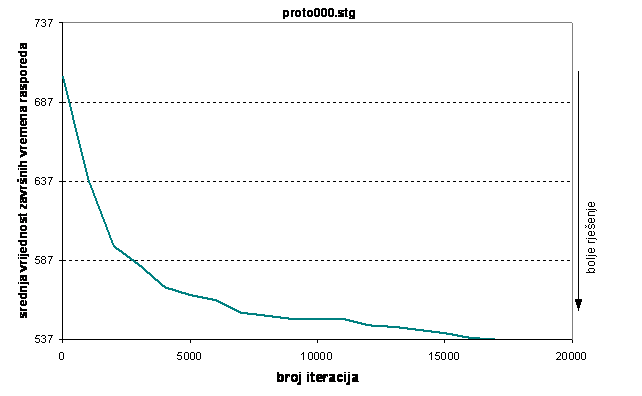
Slika 6.15. Konvergencija algoritma za slučaj pronađenog optimuma
Autori referentnog rada koristili su isti algoritam te su za isti graf poslova dobili znatno bolja rješenja: postigli su optimum u 85 posto slučajeva uz 10000 iteracija i veličinu populacije 20 jedinki [2]. U završnoj fazi eksperimentiranja otkrivena je pogreška u implementiranom genetskom algoritmu: operator križanja je u slučaju jednakih roditelja jednog od njih mutirao ali ga nije ponovno evaluirao. Mutirani roditelji su preživljavali i u slučaju da su operatorom mutacije bili degradirani, budući da su imali pripadnu vrijednost funkcije cilja od originalnog roditelja. Ta greška bi mogla objasniti lošija rješenja u odnosu na [2]. Utjecaj te greške na konvergenciju genetskog algoritma teško je procijeniti kvantitativno. Pretpostavljeno je da je utjecaj manji za veće vjerojatnosti mutacije i veličine populacije. Pokrenuto je nekoliko eksperimenata sa ispravljenom inačicom genetskog algoritma te je ta pretpostavka i potvrđena. U operator križanja ugrađen je brojač događaja jednakih roditelja: od 100000 iteracija greška se događala u nekoliko stotina do tisuću iteracija, ovisno o veličini populacije i vjerojatnosti mutacije. Usporedbom dobivenih rješenja za nekoliko veličina populacija ustanovljeno je da postoje odstupanja između ispravljene i neispravljene inačice programa, no nije bilo dovoljno vremena da se ponove svi eksperimenti.
Za drugi graf poslova nije pronađen optimum, čak ni približno dobro rješenje. Potrebno je znatno povećati broj iteracija kako bi se postigao optimum.
Analizom grafičkih prikaza rasporeda ustanovljeno je da su u optimiranim rasporedima procesori nižeg indeksa popunjeniji poslovima u odnosu na ostale procesore. To je zanimljiva posljedica budući da implementirani genetski algoritam eksplicitno ne preferira procesore nižeg indeksa.
7. ZAKLJUČAK
Genetski algoritam je robustna metoda za rješavanje problema raspoređivanja poslova. Međutim, kvaliteta rješenja značajno ovisi o parametrima genetskog algoritma. Potrebno je napraviti velik broj eksperimenata kako bi se odredili optimalni parametri, što oduzima puno vremena.
Ostvaren je jednostavni genetski algoritam s turnirskom eliminacijskom selekcijom za rješavanje problema raspoređivanja. Eksperimentalnim putem utvrđena je ovisnost pojedinih parametara genetskog algoritma na kvalitetu dobivenih rješenja. S većim brojem iteracija postižu se bolja rješenja, no, potrebno je odabrati veću vrijednost veličine populacije kako bi se spriječilo prerano konvergiranje u lokalni optimum. Za veće populacije potrebno je smanjiti vjerojatnost mutacije kako bi se postigli bolji rezultati. Svi parametri genetskog algoritma međusobno su zavisni.
Za potrebe eksperimentiranja, korišten je standardni skup grafova poslova. Odabrana su dva ispitna grafa poslova sa različitim karakteristikama. Optimalni raspored poslova pronađen je samo za prvi graf. Otkrivena greška u implementaciji mogla bi biti uzrok lošim rezultatima za drugi graf poslova.
Pomoću izrađene aplikacija za grafički prikaz rasporeda utvrđeno je da su procesori s manjim indeksom više popunjeni poslovima u optimiranim rasporedima. Kod neoptimiranih rasporeda raspodjela poslova po procesorima je podjednaka.
LITERATURA
[1] Y. LEE, C. CHEN, A Modified Genetic Algorithm for Task Scheduling in Multiprocessor Systems, Compiler Techniques for High-Performance Computing, 2003. URL: http://parallel.iis.sinica.edu.tw/cthpc2003/
[2] M. GOLUB, S. KASAPOVIĆ, Scheduling Multiprocessor Tasks With Genetic Algorithms, Proceedings of the IASTED International Conference, (2002), pp 273-278, Innsbruck
[3] M. GOLUB, Genetski algoritam - prvi dio, skripta, Fakultet elektrotehnike i računarstva, Zagreb, 2002. URL: http://www.zemris.fer.hr/~golub/ga/
[4] W. STEMBERGER, Uporaba genetskih algoritama u problemima raspoređivanja, Magistarski rad, Fakultet elektrotehnike i računarstva, Zagreb, 1997.
[5] R. C. CORREA, A. FERREIRA, P. REBREYEND, Scheduling Multiprocessor Tasks with Genetic Algorithms, IEEE Transactions on Parallel and Distributed systems, 8(1999), pp 825-837.
[6] D. JAKOBOVIĆ, Genetski algoritmi - predavanje, skripta, Fakultet elektrotehnike i računarstva, Zagreb, 2003. URL: http://www.zemris.fer.hr/predmeti/apr/
[7] M. GOLUB, Vrednovanje uporabe genetskih algoritama za aproksimaciju vremenskih nizova, Magistarski rad, Fakultet elektrotehnike i računarstva, Zagreb, 1996. URL: http://www.zemris.fer.hr/~golub/ga/
[8] M. GOLUB, Genetski algoritam - drugi dio, skripta, Fakultet elektrotehnike i računarstva, Zagreb, 2004. URL: http://www.zemris.fer.hr/~golub/ga/
[9] Advanced Computing Systems, Standard Task Graph Set. URL: http://www.kasahara.elec.waseda.ac.jp/schedule/
DODATAK A
Na priloženom CD-u nalaze se četiri direktorija:
- GA - Genetski Algoritam
- GPR - Grafički Prikaz Rasporeda
- Pisani dio - tekst ovog rada u PDF, MS Word i html formatu zapisa
- Eksperimenti - mapa sa rezultaima eksperimentiranja
- Arhiva - izvršne verzije programa u zip arhivama
U direktorijima GA i GPR nalaze se implementacije genetskog algoritma i aplikacije za grafički prikaz rasporeda.
Datoteka sa popisom izmjena originalnog kôda nalazi se u \GA\dokumenti\promjene.txt. Originalna implementacija nalazi se u \GA\dokumenti\problem_rasporeda.zip [2].
U mapi Eksperimenti nalaze se dva direktorija: proto000 i proto065, svaki za jedan ispitni graf poslova. Svaki od tih direktorija sadrži:
- protoXXX.stg - datoteka sa grafom poslova u prototype formatu zapisa
- protoXXX.xls - datoteka sa rezultatima i analizom ispitivanja u MS Excel formatu zapisa
- experiment_svi - direktorij za eksperiment određivanja utjecaja veličine populacije
- experiment_N80 - direktorij za određivanje utjecaja vjerojatnosti mutacije, uz N=80
- experiment_N200- direktorij za određivanje utjecaja vjerojatnosti mutacije, uz N=200
Svi direktoriji za eksperimente sadrže datoteke sa ulaznim parametrima genetskog algoritma, batch datoteke za pokretanje niza eksperimenata te direktorij sa rasporedima dobivenih rješenja.