
Prilikom projektiranja bilo kojeg sustava uvijek postoje zadana ograničenja koja se moraju ispoštovati. Najčešće su ta ograničenja financijske prirode. Kao primjere možemo navesti projektiranje računalnih mreža, postavljanje raznoraznih poslužitelja, projektiranje mrenžnih uređaja, itd. pri čemu je na raspolaganju ograničena količina opreme ili je unaprijed zadana količina financijskih sredstava koju je moguće utrošiti na projekt. U svakom od tih slučajeva uvijek se nameću ista pitanja: "Da li će sustav biti dovoljno brz?", "Da li će zadovoljiti potrebe u vremenu u kojemu se namjerava eksploatirati?", ...
Osim u najjednostavnijim slučajevima, odgovori na ta pitanja nisu jednostavni i dosta često se ne podudaraju sa našom intuicijom. U ekstremnim slučajevima male razlike u odlukama mogu dovesti do drastičnih posljedica. Npr., prilikom projektiranja preklopnika potrebno je odlučiti o parametrima tog preklopnika, kao npr. o količini memorije koju posjeduje taj preklopnik. Budući da se radi o uređaju koji se proizvodi u relativno velikoj seriji male razlike u slučaju jednog uređaja postaju velike u slučaju velikog broja uređaja. Zbog toga nam je potreban odgovarajući sistem uz pomoć kojega će se optimalno dimenzionirati sustav.
Postoji više mogućnosti na koje se može doći do odgovora. To su sljedeći načini:
Opcija pod 1. nije uopće opcija budući da je to upravo ono što želimo izbjeći. Problem sa opcijom 2 je činjenica da se radi o nelinearnom sustavu te je dosta lako napraviti velike pogreške u dizajnu. Opcija tri daje najtočnije rezultate no isplativa je tek za velike serije (kao npr. prijespomenuti preklopnik). Konačno, ostaje opcija 4 koja je za većinu primjena daje sasvim zadovoljavajuća rješenja.
Dosta dugo vremena primarni sistem za dimenzioniranje sustava bila je tzv. analiza uz pomoć redova, koja predstavlja temu ovih auditornih vježbi i koju ćemo detaljnije opisati nešto kasnije. U novije vrijeme (pod tim se podrazumijeva sredina 90-tih) otkrivena je samosličnost u mrežnom prometu što je pokazalo da su neke pretpostavke na kojima se temelji analiza uz pomoć redova netočne, te da zbog toga rezultati koje dobijamo ne odgovaraju stvarnosti. To je prvo uočeno snimajući i analizirajući promet koji se odvija po Ethernet LAN-u, a naknadno je utvrđeno da takvo ponašanje iskazuju i druge vrste prometa (kao npr. web). Ipak, uprkos tome analiza uz pomoć redova nam može dati zadovoljavajuće rezultate u većini slučajeva.
M/M/1 modeli
iskorištenje
srednja vrijednost
standardna devijacija
Budući da na prvim auditornim vježbama studeni još nisu upoznati sa nizom mrežnih uređaja, na prvim auditornim vježbama obrađuju se primjeri nevezani za mreže računala.
Lokalna mreža sastoji se od 100 osobnih računala i poslužitelja na kojemu se nalazi baza podataka neophodna za rad tih klijenata. Prosječno vrijeme potrebno poslužitelju da odgovori na upit je 0.6s, a standardna devijacija je procjenjena na isti iznos kao i srednja vrijednost. Prilikom najvišeg opterećenja broj upita koji stiže serveru je 20 u minuti. Zanimaju nas sljedeći odgovori:
Da bi dobili odgovore na postavljena pitanja pretpostavljamo da se radi o M/M/1 modelu, a pri čemu je SQL poslužitelj u tom modelu. Također, pretpostaviti ćemo da su sva kašnjenja koja unosi LAN zanemariva.
Prosječno vrijeme odgovora na upit iznosi:
|
(1) |
Očito nam nedostaje 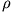 koji predstavlja iskorištenje
servera. Njega lako računamo pomoću sljedećeg izraza:
koji predstavlja iskorištenje
servera. Njega lako računamo pomoću sljedećeg izraza:
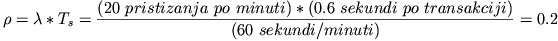 |
(2) |
Sada možemo odrediti i prosječno vrijeme odgovora:
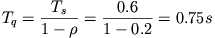 |
(3) |
Odgovor na ovo pitanje je malo teže odrediti budući da uvijek postoji neka vjerojatnost da će vrijeme nekog odgovora prijeći vrijednost od 1.5s bez obzira na iskorištenje servera. No, ono što možemo je tražiti da određeni broj odgovora padne ispod te granice. U našem slučaju recimo da želimo da 90% upita ima vrijeme odgovora manje od 1.5s. Opet kao i u prethodnom zadatku krećemo od sljedećeg izraza:
|
(1) |
U tom izrazu tražimo , imamo zadani
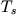 , dok nam nedostaje
, dok nam nedostaje
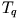 . možemo
saznati rješavanjem sljedećeg izraza:
. možemo
saznati rješavanjem sljedećeg izraza:
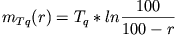 |
(4) |
U tom izraz, 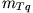 je maksimalno vrijeme koje
imamo zadano, r predstavlja postotak svih upita čije vrijeme obrade je manje
od , dok je
veličina koju tražimo. Kombinirajući prethodna dva izraza dolazimo do
vrijednosti za koja iznosi 0.08.
je maksimalno vrijeme koje
imamo zadano, r predstavlja postotak svih upita čije vrijeme obrade je manje
od , dok je
veličina koju tražimo. Kombinirajući prethodna dva izraza dolazimo do
vrijednosti za koja iznosi 0.08.
Prema tome, možemo zaključiti da iskorištenje servera mora biti manje od 8% da bi 90% svih pristiglih upita imalo vrijeme obrade manje od 1.5s.