Most of the existing distributed visual tracking (DVT) systems focus on tracking humans in indoor environments [3,4,5,2,6]. These designs have been motivated either by surveillance [4,5,6] or general human-computer interaction [3,2] applications. An another important application field of DVT is the real time monitoring of various sport events. The information about the game status can be used for augmenting a broadcast TV edition by an overlay image showing the positions of the players or the ball [7], which are difficult to estimate from the current view. Additionally, the obtained data could be employed for a semi-automated direction of the TV edition. In such an arrangement, the viewing directions of all cameras covering the scene might be adjusted by the automated control system, in order to achieve an acceptable presentation of the event.
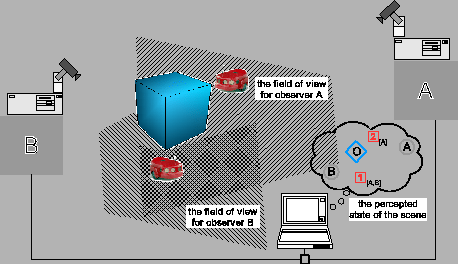
The proposed work has been directly inspired by a yet another application of DVT, and that is providing localization information to a group of simple autonomous mobile robots with modest equipment (see fig.1). This approach has been called global vision [8,9], distributed vision [10,1] and sensor network for mobile robotics [11], and has been classified with artificial landmark localization techniques [12], since it requires special interventions to the environment in which the navigation takes place. The approach is particularly suitable for applications requiring a large number of autonomous vehicles (e.g. an automated warehouse), because it allows trading fixed cost vision infrastructure for a per-vehicle savings in advanced sensor accessories [8]. Recently, global vision has become a popular method for coordinating ``players'' in small robot soccer teams (see e.g. [9]).
In most realistic global vision applications, it is feasible and favourable to place the cameras above the navigation area so that the objects appear relatively small in images acquired from each viewpoint (see fig.1). The proposed architecture therefore assumes that the position of each tracked ground object can be estimated from a single view. In order to improve the tracking quality and simplify the implementation of the overall control, it is advantageous to consider autonomous observers, capable of adjusting the viewing direction according to the movement of the tracked objects. Consequently, the observers are organized in a multiagent system [13], in which some of the actions are taken autonomously while others are done in coordination with other observers.
The following section gives a brief overview of the previous work in related research directions. The proposed multiagent architecture is outlined in section 3, while sections 4 and 5 provide some of the implementation details for the two types of agents within the system. Experimental results are shown in section 6, while section 7 contains a short discussion and directions for the future work.