SVEUČILIŠTE U ZAGREBU
FAKULTET ELEKTROTEHNIKE
I RAČUNARSTVA
DIPLOMSKI RAD br. 1752
Proširivi programski sustav za rješavanje optimizacijskih problema
Zvonimir Kunetić
0036401389
Voditelj: Doc.dr.sc. Marin Golub
Source
code (Visual Studio 2005 Solution)
Optimization
Framework Setup (.msi)
Zagreb, rujan, 2008.
U ovom radu opisuje se jednostavan genetski algoritam s turnirskom selekcijom. Nakon toga definirano je nekoliko NP-teških optimizacijskih problema poput problema trgovačkog putnika (TSP), P-median problema, problem kvadratičnog pridruživanja, problem osnovnog budžeta i linearno programiranje (SIMPLEX postupak). Razmotrena je primjena genetskih algoritama za rješavanje navedenih optimizacijskih problema.
Opisan je i implementiran proširiv programski sustav za rješavanje optimizacijskih problema u koji se naknadno mogu umetati i algoritmi i optimizacijski problemi. Svi gore navedeni optimizacijski problemi implementirani su u programski sustav.
This document describes basic Genetic algorithm with tournament selection. After, are defined several NP-hard optimization problems like travelling salesman problem, P-median problem, Quadratic assignment problem, Capital budgeting problem and Linear programming problem (SIMPLEX). Apply of Genetic algorithm is observed for resolving optimization problems.
Program sistem is described and implemented for resolving optimization problems in witch we can put algorithms and oprimization problems. All above mentioned optimization problems are implemented in program system.
2. EVOLUCIJSKI
PROCESI U PRIRODI
3.2 Model
jedonstavnog genetskog algoritma
3.3 Kodiranje
svojstva jedinke
3.4 Inicijalizacija
i uvjet završetka GA
3.7 Genetski
operatori križanja i mutacije
3.8 Parametri
genetskog algoritma
4. DEFINICIJA
I IMPLEMENTACIJA NP TEŠKIH OPTIMIZACIJSKIH PROBLEMA
4.1 Problem
linearnog programiranja (SIMPLEX postupak)
4.1.1 Definicija
linearnog programa
4.1.2 Primjena
genetskog algoritma u simplex postupku.
4.1.3 Sintaksa
implementirane ulazne datoteke simplex postupka
4.2 Problem
trgovačkog putnika
4.2.2 Genetski
algoritmi i problem trgovačkog putnika.
4.2.3 Sintaksa
implementirane ulazne datoteke TSP problema
4.3.2 Genetski
algoritam i P-median problem
4.3.3 Sintaksa
implementirane ulazne datoteke P-median problema
4.4 Problem
kvadratičnog pridruživanja
4.4.2 Genetski
algoritam i problem kvadratičnog pridruživanja
4.4.3 Sintaksa
implementirane ulazne datoteke problema kvadratičnog pridruživanja
4.5.2 Genetski
algoritam i problem osnovnog budžeta
4.5.3 Sintaksa
implementirane ulazne datoteke problema osnovnog budžeta
5. PROGRAMSKI
SUSTAV ZA RJEŠAVANJE OPTIMIZACIJSKIH PROBLEMA
5.1 Opis
glavnih cjelina programskog sustava Optimization Framework
5.1.1 Glavni
asembliji programskog sustava
5.1.2 Početna
forma programskog sustava
5.1.3 Forma
za odabir problema i algoritma
5.2 Implementacija
novih problema u programski sustav
5.2.1 Dodavanje
novog asemblija
5.2.2 Dodavanje
statičkih podataka novog projekta u bazu podataka
5.2.3 Implementacija
sučelja novog problema
5.2.4 Implementacija
parsera ulaznih i izlaznih datoteka
5.3 Implementacija
novih algoritama u programski sustav
5.4 Integracija
novog projekta u postojeći sustav
5.5 Učitavanje
i spremanje projekata
5.6 Priprema
projekta za instalaciju
6. PRIMJERI
IMPLEMENTIRANIH PROBLEMA
6.1 Implementacija
Linearnog programiranja (SIMPLEX postupak)
6.2 Implementacija
problema trgovačkog putnika – TSP
6.3 Implementacija
P-median problema
6.4 Implementacija
problema kvadratičnog pridruživanja
6.5 Implementacija
problema osnovnog budžeta
1. UVOD
Genetski algoritmi (GA) predloženi su od strane Johna H. Hollanda u ranim sedamdesetim godinama. Pokazali su se vrlo moćnim i u isto vrijeme općenitim alatom za rješavanje čitavog niza problema iz inžinjerske prakse. GA služi za rješavanje težih optimizacijskih problema, za koje ne postoji egzaktna matematička metoda rješavanja ili su NP-teški pa se za veći broj nepoznanica ne mogu riješiti u zadanom vremenu. GA kao metoda optimiranja nastao je oponašanjem evolucije. Simuliranje prirodnog evolucijskog procesa na računalu svodi se na grube aproksimacije rješenja.
Genetski algoritam je heuristička metoda optimiranja. Po načinu djelovanja genetski algoritam ubraja se u metode usmjerenog slučajnog pretraživanja prostora rješenja (guided random search techniques) u potrazi za globalnim optimumom. Analogija evolucije kao prirodnog procesa i genetskog algoritma kao metode optimiranja očituje se u procesu selekcije i ostalim genetskim operatorima. U genetskom algoritmu ključ selekcije je funkcija cilja, koja na odgovarajući način predstavlja problem koji se rješava. Za genetski algoritam jedno rješenje je jedna jedinka. Selekcijom se odabiru dobre jedinke koje se prenose u slijedeću populaciju, a manipulacijom genetskog materijala stvaraju se nove jedinke. Takav ciklus selekcije, reprodukcije i manipulacije genetskim materijalom jedinki ponavlja se sve dok nije zadovoljen uvjet zaustavljanja evolucijskog procesa.
Snaga genetskih algoritama leži u činjenici da su oni sposobni odrediti položaj globalnog optimuma u prostoru s više lokalnih ekstrema, u tzv. višemodalnom prostoru. Klasične determinističke metode će se uvijek kretati prema lokalnom minimumu ili maksimumu, pri čemu on može biti i globalni, ali to se ne može odrediti iz rezultata. GA nije ovisan o nekoj eventualnoj početnoj točki i mogu svojim postupkom pretraživanja s nekom vjerojatnošću locirati globalni optimum određene ciljne funkcije. Za rezultat rada GA nemože se sa 100% vjerojatnošću reći predstavlja li globalni ili samo lokalni optimum, te je li isti određen sa željenom preciznošću. Sigurnost dobivenih rezultata značajno se povećava postupkom ponavljanja procesa rješavanja.
Genetski materijal je skup svojstva koji opisuje neku jedinku. GA ne određuje na koji način je genetski materijal pohranjen u radni spremnik, niti kako treba manipulirati genetskim materijalom, već samo kaže da se genetski materijal treba razmjenjivati, slučajno mijenjati, a bolje jedinke trebaju s većom vjerojatnošću preživljavati selekciju. Kako će se bolje jedinke selektirati za reprodukciju, te kako će se i s kolikim vjerojatnostima obaviti križanje i mutacija, određuje se na temelju iskustva i eksperimentalno, tj. heuristički. Podešavanjem (optimiranjem) parametara genetskog algoritma mogu se postići zadovoljavajući rezultati. Međutim postupak podešavanja i optimiranja je dugotrajan proces za rješavanje teških optimizacijskih problema s velikim brojem nepoznanica. Jedan od načina kako skratiti trajanje postupka optimiranja jest paralelizacija genetskih algoritama. [1]
Kako bi se problemi i evolucijski algoritmi okupili na jedno mjesto, u diplomskom radu implementiran je sustav koji na jednostavan način ujedinjuje probleme i algoritme. Sustav je nazvan Optimization Framework. Sustav je izveden tako da nakon odabira problema i algoritma generira projekt koji rješava problem pomoću odabranog algoritma. Projekte je moguće spremati na disk te kasnije ponovno pokretati. Omogućeno je da se problem može rješavati sa više različitih algoritama, čime je dobiveno na kompaktnosti sustava. Definiciju problema moguće je definirati na više različitih načina, zbog toga je u sustavu omogućena implementacija više parsera ulaznih datoteka za problem. Ukoliko postoji potreba posebnog formata datoteke u kojoj su zapisani rezultati izvođenja algoritma moguče je također implementirati parsere izlaznih datoteka, čime je omogućena komunikacija sa drugim programima.
Definirano je i u sustav implementirano pet NP-teških problema. Za problem linearnog programiranja i problem trgovačkog putnika u sustavu su implementirani genetski algoritmi kojima se rješavaju navedeni problemi, također su definirani parseri ulaznih i izlaznih datoteka. Za P-median problema, problem kvadratičnog pridruživanja i problem osnovnog budžeta u sustavu su implementirani parseri ulaznih datoteka i prikaz navedenih problema. Cilj praktičnog rada nije bio izrada genetskog algoritma i testiranje njegovih operatora već napraviti sustav koji će omogućiti testiranja evolucijskih algoritama na raznim problemima.
2. EVOLUCIJSKI PROCESI U PRIRODI
Charles Darwin je primijetio da živa bića u pravilu stvaraju više potomaka od cijele njihove populacije. Prema tome, broj jedinki koje čine populaciju trebao bi eksponencijalno rasti iz generacije u generaciju. Unatoč toj činjenici, broj jedinki jedne vrste teži ka konstantnom broju. Primijetivši različitosti medu jedinkama iste vrste, zaključio je da priroda selekcijom jedinki regulira veličinu populacije. Dobra svojstva jedinke, kao što su otpornost na razne bolesti, sposobnost trčanja, itd., pomažu da jedinka preživi u neprestanoj borbi za opstanak.
Kako bi neka vrsta tijekom evolucije opstala, mora se prilagođavati uvjetima i okolini u kojoj živi jer se uvjeti i okolina mijenjaju. Svaka slijedeća generacija neke vrste mora pamtiti dobra svojstva prethodne generacije, pronalaziti i mijenjati ta svojstva tako da ostanu dobra u neprekidno novim uvjetima.
Danas se pretpostavlja da su sva svojstva jedinke zapisana u kromosomima. Kromosomi su lančaste tvorevine koje se nalaze u jezgri svake stanice. Skup informacija koje karakteriziraju jedno svojstvo zapisano je u jedan djelić kromosoma koji se naziva gen. Kromosomi dolaze uvijek u parovima: jedan kromosom je od oca, a drugi od majke. Takav par gena gdje jedan i drugi gen nosi informaciju za jedno svojstvo naziva se alel.
Kemijsku strukturu koja je prisutna u kromosomima otkrili su Watson i Circk 1953. godine. Slika 2.1 prikazuje molekulu deoksiribonukleinske kiseline (DNK) u obliku dvije spirale građena od fosforne kiseline i šećera, a mostovi između spiralnih niti građeni su od dušičnih baza i to adenina, gvanina, timina, citozina. Pokazalo se da su upravo te dušične baze jedinice informacije. Slično kao što je u računalu najmanja jedinica informacije jedan bit, tako je u prirodi najmanja jedinica informacije jedna dušićna baza (A,G,C ili T). Jedan kromosom se sastoji od dvije komplementarne niti DNK. Ovakva struktura dviju spiralnih niti DNK omogućava prenošenje informacije dijeljenjem kromosoma pri diobi stanice.
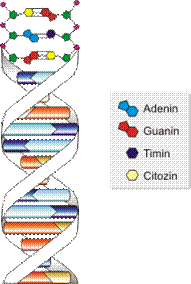
Slika 2.1. Struktura DNK
2.1 Evolucija u prirodi
Evolucija je prirodni proces traženja najbolje i najprilagodljivije jedinke na okolinu i uvjete u prirodi. Dakle, evolucija, odnosno prirodni evolucijski proces, jest metoda optimiranja. Ideja za genetski algoritam može se naći u mehanizmu prirodnog odabira: u prirodi, od skupa istobitnih pojedinaca, preživljavaju oni koji su najbolje prilagođeni snalaženju u okolini siromašnoj sredstvima za život. Najsposobniji dobivaju priliku da dominiraju slabijima i također se reproduciraju. Ako poistovjetimo mjeru sposobnosti pojedinca da preživi sa nasljeđnim materijalom koji nosi u sebi, genima, tada možemo reći da geni dominantnih pojedinaca opstaju dok geni slabijih izumiru jer nemaju potomstva. Pored te pojave, u prirodi pri svakoj reprodukciji dolazi do rekombinacije gena koja uzrokuje različitost među pojedincima iste vrste, ali i sličnosti s roditeljima jedinke. Promatramo li samo gene, može se reći da u svakoj novoj generaciji dobijemo novi skup gena, gdje su neki pojedinci lošiji od onih u prethodnoj generaciji a neki bolji. Izmjena gena koja nastaje pri reprodukciji se u genetskim algoritmima, iako to nije sasvim u skladu sa biologijom, naziva križanje. Osim križanja, uočava se još jedna pojava, ali u znatno manjem opsegu. Riječ je o slučajnom mijenjanju genetskog materijala koje nastaje pod djelovanjem vanjskih uzroka a naziva se mutacija. Križanje i mutacija se kod genetskih algoritama nazivaju genetskim operatorima, a proces izdvajanja najsposobnijih jedinki unutar svake generacije odabirom selekcija.
2.2 Križanje i mutacija
Križanjem se prenosi genetski materijal, a s njime i svojstva roditelja na djecu. Svaka jedinka posjeduje genetski materijal oba roditelja. Neka je broj kromosoma koje ima jedinka jednaka 2n. Slijedeća generacija jedinki također treba imati isti broj kromosoma, što znači da jedan roditelj treba dati polovičan (haploidan) broj kromosoma n. To se postiže prilikom sinteze spolnih stanica staničnom diobom koja se naziva mejoza. Za vrijeme diobe kromosoma, kromosomi se najprije razmotaju u duge niti. Par kromosoma se razdvoji, ali ne u potpunosti, tako da se još drži zajedno u samo jednoj točki koja se naziva centromjera. Slijedi udvostručavanje kromosoma, vežu se slobodne baze s komplementarnim bazama na kromosomskim nitima. Tada dolazi između unutrašnjih niti (rjeđe i vanjskih) do izmjene segmenata kromosomskih niti. Slika 2.2 prikazuje taj proces. Taj proces naziva se križanje ili izmjena faktora.
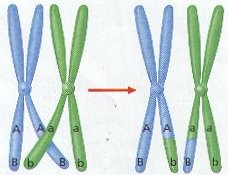
Slika 2.2. Izmjena
segmenata kromosomatskih niti (crossing-over)
Mutacija je slučajna promjena gena. Neki geni mutiraju lakše, a neki teže, pa se dijele na stabilne i nestabilne gene. Vjerojatnost mutacije jednog gena je konstantna, ali je različita za različite gene i kreće se od 10-4 do 10-5. Vjerojatnost da gen A postane gen B nije ista kao i vjerojatnost da se gen B mutacijom promijeni u gen A. Mutacija je trajna (i nasljedna, ako se dogodila u spolnoj stanici) promjena genetskog materijala stanice, tj. DNK ili RNK. Uzroci mutacija su mnogobrojni: greške pri umnožavanju genetskog materijala u procesu stanične diobe, izlaganje vanjskim čimbenicima poput radijacije, različitih kemijskih spojeva ili virusa te namjerne mutacije tijekom mejoze. Slika 2.3 prikazuje mutaciju prilikom izlaganja vanjskim čimbenicima. Mutacije u nespolnim stanicama višestaničnih organizama, tzv. Somatske mutacije, ne prenose se na potomstvo i mogu prouzročiti greške u odvijanju staničnih funkcija ili smrt stanica. S druge strane, mutacije u spolnim stanicama smatraju se jednim od preduvjeta evolucije jer se procesom prirodnog odabira u populaciji nakupljaju mutacije koje omogućuju bolju prilagodbu uvjetima okoliša i time utječu na bolje preživljavanje jedinke koje ih nose i prijenos na slijedeće generacije.
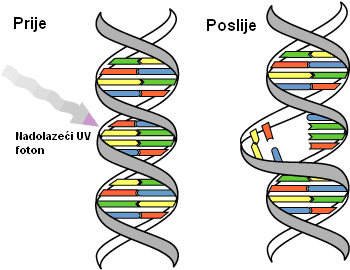
Slika 2.3. Mutacija gena pri izlaganju vanjskim čimbenicima
3. OPIS GENETSKOG ALGORITMA
3.1 Opća razmatranja
Moguće je identificirati dva pristupa rješavanja određenog problema: prilagoditi problem genetskom algoritmu ili genetski algoritam prilagoditi specifičnostima problema. Ukoliko odaberemo prilagođavanje algoritma problemu, potrebno je modificirati njegov rad tako da rukuje sa veličinama svojstvenim određenom zadatku. Najčešće se tu radi o upotrebi ili definiranju drugačijih struktura podataka i operatora. Za vrlo veliki broj takvih slučajeva razvijeni su posebni specijalizirani genetski algoritmi, koji se tada obično nazivaju evolucijskim programima. Uglavnom se tada postižu velika povećanja djelotvornosti. Ovakav način je, opet, problemski ovisan i zahtjeva dosta rada na prilagođavanju; ponekad je taj problem ravan onome koji se želi riješiti, a za svaku novu promjenu potrebna je nova prilagodba. Zato se kompromis postiže pravljenjem evolucijskog programa koji će se moći primijeniti na čitavu klasu problema.
S druge strane, nastoji li se riješiti zadani problem uz pomoć genetskog algoritma, tada je potrebno problem prilagoditi genetskom algoritmu. Moguće rješenje se najčešće prikazuje kao niz bitova (binarni prikaz). Međutim, postoji čitav niz problema za koje je teško ili nemoguće primijeniti binarni prikaz (npr., problem rasporeda). Zatim uobičajeni genetski operatori mogu generirati značajan postotak nemogućih rješenja (npr., za problem najkraćeg puta) koji ne donose nikakva poboljšanja, već samo usporavaju algoritam. Osim uobičajnog binarnog prikaza koriste se razni drugi prikazi (matrice, nizovi realnih brojeva, itd.) i definiraju se usko specijalizirani genetski operatori primjenjivi samo za određeni problem kako bi se izbjegla nemoguća rješenja. Primjenom prikaza i genetskih operatora dobiva se prilagođeni genetski algoritam problemu koji se naziva evolucijski program.
3.2 Model jedonstavnog genetskog algoritma
Holland je u svom radu predložio (jednostavni) genetski algoritam kao računarski proces koji imitira evolucijski proces u prirodi i primjenjuje ga na apstraktne jedinke. Svaki evolucijski program održava populaciju jedinki u nekoj određenoj generaciji. Svaka jedinka predstavlja potencijalno rješenje problema koji se obrađuje. Svaka je jedinka predstavljena jednakom podatkovnom strukturom (broj, niz, matrica, stablo…). Te jedinke se nazivaju kromosomi. Svakom rješenju se pridjeljuje određena mjera koja se obično naziva dobrota, dok se funkcija koja tu kvalitetu određuje naziva funkcija cilja ili funkcija dobrote. Tada se iz stare formira nova populacija izdvajajući, po nekom postupku odabira, bolje jedinke iz skupa postojećih. Neki članovi ove nove populacije podvrgnuti su utjecajima genetskih operatora koji iz njih formiraju nove jedinke. Operatori se dijele na unarne, koji stvaraju nove jedinke mijenjajući manji dio genetskog materijala (mutacijska grupa) i operatori višeg reda, koji kreiraju nove individue kombinirajući osobine nekoliko jedinki (grupa križanja). Nakon nekog broja izvršenih generacija čitav postupak se zaustavlja kada se zadovolji uvjet zaustavljanja, a najbolji član trenutne populacije predstavlja rješenje koje bi trebalo biti sasvim blizu optimuma. Slika 3.1 prikazuje strukturu genetskog algoritma.
|
Genetski_algoritam() { t = 0; generiraj
početnu populaciju potencijalnih rješenja P(0); sve
dok nije zadovoljen uvjet završetka evolucijskog proc; { t = t + 1; selektiraj P´(t) iz P(t-1); križaj jedinke iz P´(t) i djecu spremi u P(t); mutiraj jedinke iz P(t); } ispiši
rješenje; } |
Slika 3.1. Struktura genetskog algoritma
Prilikom inicijalizacije generira se početna populacija jedinki. Obično se početna populacija generira slučajnim odabirom rješenja iz domene mada je moguće početnu populaciju generirati uniformno (sve jedinke su iste pa u početku evolucijskog procesa GA nije učinkovit i taj postupak se ne preporuča) ili usaditi početno (inicijalno) rješenje u početnu populaciju dobivenom nekom drugom optimizacijskom metodom. Slijedi proces koji se ponavlja sve dok ne istekne vrijeme ili je zadovoljen neki uvjet (npr. funkcija dobrote 95% jedinki odstupa za manje od ε). Taj proces se sastoji od djelovanja genetskih operatora selekcije, križanja i mutacije nad populacijom jedinki. Tijekom selekcije loše jedinke odumiru, dobre opstaju te se u slijedećem koraku, križaju, razmnožavaju. Križanjem se prenose svojstva roditelja na djecu. Mutacijom se mijenjaju svojstva jedinke slučajnom promjenom gena. Takvim postupkom se postiže iz generacije u generaciju sve veća prosjećna dobrota populacije. [1]
Genetski algoritam simulira prirodni evolucijski proces. Za evolucijski proces kao i za genetski algoritam se može ustanoviti sljedeće:
Ø postoji populacija jedinki,
Ø neke jedinke su bolje (bolje su prilagođene okolini),
Ø bolje jedinke imaju veću vjerojatnost preživljavanja i reprodukcije,
Ø svojstva jedinke zapisana su u kromosomima pomoću genetskog koda,
Ø djeca nasljeđuju svojstva roditelja,
Ø nad jedinkom može djelovati mutacija
Za GA jedinke su potencijalna rješenja, a okolinu predstavlja funkcija cilja. Za GA kao metodu optimiranja potrebno je definirati proces dekodiranja i preslikavanja podataka zapisanih u kromosomu te odrediti funkcije dobrote.
3.3 Kodiranje svojstva jedinke
Svi podaci koji obilježavaju jednu jedinku zapisani su u jednom kromosomu. Podaci mogu biti pohranjeni na razne načine u jedan kromosom:
1. niz bitova koji čine jedan kromosom (binarni prikaz)
2. kromosom može biti i realan broj (u C-u float, double)
3. ako je problem višedimenzijski, umjesto jednog broja treba biti polje brojeva veličine dimenzije problema
Općenito kromosom može biti bilo kakva struktura podataka koja opisuje svojstva jedne jedinke. Za genetski algoritam je značajno da kromosom predstavlja moguće rješenje zadanog problema. Za svaku strukturu podataka valja definirati genetske operatore. Genetski operatori trebaju biti tako definirani da oni ne stvaraju nove jedinke koje predstavljaju nemoguća rješenja, jer se time znatno umanjuje učinkovitost genetskog algoritma.
3.4 Inicijalizacija i uvjet završetka GA
Populaciju potencijalnih rješenja predstavlja VEL_POP(t), obično se uzima da je VEL_POP(t) = const = VEL_POP, odnosno veličina populacije se ne mijenja tijekom evolucije. Vrijednost VEL_POP je parametar algoritma.
Proces generiranja početne populacije P(0) se sastoji od slučajno odabranih vrijednosti unutar dozvoljenog intervala. Početna populacija može biti uniformna (sve jedinke su iste). U početnu populaciju se može dodati neko međurješenje dobiveno nekom drugom optimizacijskom metodom.
Evolucijski proces se neprestano ponavlja sve dok se ne zadovolji neki uvjet. Uvjet završetka evolucijskog procesa je najčešće unaprijed zadan broj iteracija. Budući da je vrijeme izvođenja pojedine iteracije približno konstantno, time je zadano i trajanje optimiranja.
3.5 Funkcija dobrote
Funkcija dobrote ili funkcija ocjene kvalitete jedinke se u literaturi još naziva fitness funkcija, funkcija sposobnosti, funkcija cilja ili eval funkcija i u najjednostavnijoj interpretaciji ekvivalent je funkcije f koju treba optimizirati :
|
dobrota(v) = f(x) |
gdje v predstavlja potencijalno rješenje iz populacije. Što je dobrota jedinke veća, jedinka ima veću vjerojatnost preživljavanja i križanja. Funkcija dobrote je ključ za proces selekcije. Pokazalo se u praksi da se ova jednostavna transformacija može primijeniti samo uz neka ograničenja nad f(x). Za zadani optimizacijski problem najveću poteškoću predstavlja definiranje funkcije dobrote, koja treba vjerno odražavati problem koji se rješava. Tijekom procesa evolucije dobar genetski algoritam generira, iz generacije u generaciju, populacije čija je ukupna dobrota i prosječna dobrota sve bolja.
3.6 Postupci selekcije
Genetski algoritmi koriste selekcijski mehanizam za odabir jedinki koje će sudjelovati u reprodukciji. Selekcijom se omogućava prenošenje boljeg genetskog materijala iz generacije u generaciju. Zajedničko svojstvo svih vrsta selekcija je veća vjerojatnost odabira boljih jedinki za reprodukciju. Postupci selekcije se međusobno razlikuju po načinu odabira boljih jedinki. Prema načinu prenošenja genetskog materijala boljih jedinki u sljedeću generaciju postupci selekcije se dijele na:
Ø generacijske selekcije – selekcijom se direktno biraju bolje jedinke čiji će se genetski materijal prenijeti u sljedeću iteraciju
Ø eliminacijske selekcije – biraju se loše jedinke za eliminaciju, a bolje jedinke prežive postupak selekcije
Generacijskom selekcijom se odabiru bolje jedinke koje će sudjelovati u reprodukciji. Između jedinki iz populacije iz prethodnog koraka biraju se bolje jedinke i kopiraju u novu populaciju. Ta nova populacija, koja sudjeluje u reprodukciji, naziva se međupopulacijom. To je ujedno prvi nedostatak generacijskih selekcija, jer se u radnom spremniku odjednom nalaze dvije populacije jedinki. Broj jedinki koje prežive selekciju je manji od veličine populacije. Najčešće se ta razlika u broju preživjelih jedinki i veličine populacije popunjava duplikatima preživjelih jedinki; to je drugi nedostatak generacijske selekcije, jer duplikati nikako ne doprinose kvaliteti dobivenog rješenja, već samo usporavaju evolucijski proces. Generacijska selekcija postavlja granice među generacijama. Svaka jedinka egzistira točno samo jednu generaciju. Izuzetak su jedino najbolje jedinke koje žive duže od jedne generacije i to samo ako se primjeni elitizam.
Kod eliminacijske selekcije bolje jedinke preživljavaju mnoge iteracije pa stroge granice između generacija nema, kao što je to slučaj kod generacijskih selekcija. Eliminacijska selekcija briše M jedinki. Parametar M naziva se mortalitetom ili generacijskim jazom. Izbrisane jedinke bivaju nadomještene jedinkama koje se dobivaju reprodukcijom. Eliminacijskom selekcijom se otklanjaju oba nedostatka generacijske selekcije. Na prvi pogled je uvođenje novog parametra M nedostatak eliminacijske selekcije, jer se svakim dodatnim parametrom značajno produžava postupak podešavanja algoritma. Međutim, uvođenjem novog parametra, nestaje parametar vjerojatnosti križanja.
Selekcijom se osigurava prenošenje boljeg genetskog materijala s većom vjerojatnošću u sljedeću iteraciju. Ovisno o metodi odabira boljih jedinki kod generacijskih selekcija, odnosno loših jedinki kod eliminacijskih selekcija, postupci selekcije se dijele na proporcionalne i rangirajuće. Zajedničko obilježje svim selekcijama je veća vjerojatnost preživljavanja bolje jedinke od bilo koje druge lošije jedinke. Selekcije se razlikuju prema načinu određivanja vrijednosti vjerojatnosti selekcije određene jedinke. Proporcionalne selekcije odabiru jedinke s vjerojatnošću koja je proporcionalna dobroti jedinke, odnosno vjerojatnost selekcije ovisi o kvocijentu dobrote jedinke i prosječne dobrote populacije. Rangirajuće selekcije odabiru jedinke s vjerojatnošću koja ovisi o položaju jedinke u poretku jedinki sortiranih po dobroti. Rangirajuće selekcije se dijele na sortirajuće i turnirske selekcije. Turnirske selekcije se dijele prema broju jedinki koje sudjeluju u turniru. [2]
3.7 Genetski operatori križanja i mutacije
Reprodukcija je jako važna karakteristika genetskog algoritma. U reprodukciji sudjeluju dobre jedinke koje su preživjele proces selekcije. Reprodukcija je razmnožavanje s pomoću genetskog operatora križanja. Tijekom procesa reprodukcije dolazi i do slučajnih promjena nekih gena ili mutacije te zamjene gena ili inverzije.
U procesu križanja (crossover) sudjeluju dvije jedinke koje se nazivaju roditelji. Križanje je binarni operator. Križanjem nastaje jedna ili dvije nove jedinke koje se nazivaju djeca. Najvažnija karakteristika križanja jest da djeca nasljeđuju svojstva svojih roditelja. Ako su roditelji dobri(prošli su proces selekcije), tada će najvjeroojatnije i dijete biti dobro, ako ne i bolje od svojih roditelja.
Križanje može biti definirano s proizvoljnim brojem prekidnih točaka.
Vrste križanja:
Ø uniformno križanje je križanje s b-1 prekidnih točaka (b je broj botova), te je jednaka vjerojatnost nasljeđivanja svojstva oba roditelja.
Ø p-uniformno križanje je križajne gdje se vjerojatnost nasljeđivanja svojstva razlikuje za pojedine gene
Ø uniformno križanje kao logička operacija nad bitovima
Ø segmentno križanje s više točaka prekida, broj točaka i pozicija prekida je slučajna za svako pojedino križanje
Ø miješajuće križanje obavlja se u tri koraka. Izmješaju se bitovi svakog roditelja, klasično križanje s jednom ili više točaka, izmješani bitovi kod roditelja vrate se na stara mjesta.
Definira se pozicijska i distribucijska sklonost operatora križanja, u ovisnosti da li zamjena bitova kod operatora križanja ovisi o poziciji ili broju zamjenjenih bitova.
Pretpostavalja se da je upravo operator križanja to što razlikuje genetski algoritam od ostalih metoda optimiranja.
Drugi operator koji je karakterističan za GA je mutacija ili slučajna promjena jednog ili više gena. Mutacija je unarni opertaor jer djeluje nad jednom jedinkom. Rezultat mutacije je izmjenjena jedinka. Paramtar koji određuje vjerojatnost mutacije pm jednog bita je ujedno i parametar algoritma. Ako vjerojatnost mutacije teži k jedinici, tada se algoritam pretvara u algoritam slučajne pretrage prostora rješenja. S druge strane ako vjerojatnost mutacije teži k nuli, postupak će najvjerojatnije već u početku procesa optimiranja stati u nekom lokalnom optimumu.
Mutacijom se pretražuje prostor rješenja i upravo je mutacija mehanizam za izbjegavanje lokalnih minimuma. Ako cijela populacija završi u nekom od lokalnih minimuma, jedino slučajnim pretraživanjem prostora rješenja pronalazi se bolje rješenje. Dovoljno je da jedna jedinka (nastala mutacijom) bude bolja od ostalih, pa da se u nekoliko slijedećih generacija sve jedinke presele u prostor gdje se nalazi bolje rješenje. Uloga mutacije je i također i u obnavljanju izgubljenog genetskog materijala. Dogodi li se, npr. da sve jedinke populacije imaju isti gen na odredenom mjestu u kromosomu, samo križanjem se taj gen nikada ne bi mogao promijeniti.
3.8 Parametri genetskog algoritma
Genetski algoritam ima sljedeće parametre:
Ø veličina populacije
Ø broj generacjia ili iteracija
Ø vjerojatnost mutacije
Ø vjerojatnost križanja - za generacijski GA
Ø broj jedinki za eliminaciju – za eliminacijski GA umjesto vjerojatnosti križanja
Za različite vrijednosti parametara algoritma, algoritam daje različite rezultate: brže ili sporije dolazi do boljeg ili lošijeg rješenja. Optimiranje parametara GA je složen postupak i zahtjeva izvođenje velikog broja eksperimenata.
Dovoljno je optimizirati slijedeće parametre:
Ø veličina populacije
Ø vjerojatnost mutacije
Ø vjerojatnost križanja
Ø broj jedinki za eliminaciju
Parametri GA ne moraju biti konstantni za vrijeme evolucije. Dinamički parametri mogu biti funkcija vremena ili broja iteracija ili mogu biti funkcija veličine raspršenosti rješenja. Ako su rješenja raspršena, valja povećati učestalost križanja, a smanjiti mutaciju. Ako su rješenja uniformna potrebno je učiniti suprotno.
Za optimirajne višemodalnih funkcija, GA trebaju posjedovati dvije važne karakteristike:
Ø sposobnost konvergiranja k optimumu (lokalni ili globalni) nakon pronalaženja područja u kojem se nalazi
Ø sposobnost da se konstantno istražuju nova područja problemskog prostora u potrazi za globalnim optimumom
Ako GA upotrebljava samo križanje on će moći konvergirati k ekstremu kod koga se zatekao. Ako pak imamo samo mutaciju kao genetski operator, GA će nakon dovoljnog broja generacija vrlo vjerojatno naći područje globalnog optimuma. Strategije prilagodbe traže kompromis između ove dvije krajnosti mijenjajući vjerojatnost mutacije i križanja, ovisno o trenutnom stanju GA.
4. DEFINICIJA I IMPLEMENTACIJA NP TEŠKIH OPTIMIZACIJSKIH PROBLEMA
4.1 Problem linearnog programiranja (SIMPLEX postupak)
Linearno programiranje (LP) specijalan je slučaj matematičkog programiranja, definiran kao:
|
|
(4.1) |
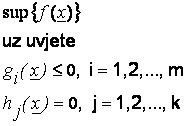
gdje je x vektor od n komponenti x1, x2, …, xn, a h1, h2, …, hk jesu funkcije definirane u n-dimenzijskom euklidskom prostoru.[3]
Kod linearnog programiranja za zadanu realnu linearnu funkciju od n strukturnih varijabli traži se ekstrem (minimum ili maksimum), uz uvjet da bude zadovoljeno m+k linearnih ograničenja postavljenih na strukturne varijable, a formuliranih u obliku nejednadžbi i jednadžbi.
4.1.1 Definicija linearnog programa
Standardna definicija problema linearnog programiranja ima oblik :
|
|
(4.2) |
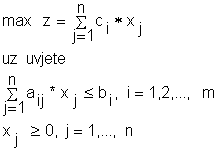
Varijable xj, j=1,…,n nazivaju se strukturnim varijablama.
Ista definicija u matričnoj notaciji ima oblik:
|
|
(4.3) |
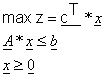
Svi ostali oblici mogu se svesti na navedenu definiciju:
Ø Minimizacija: Maksimizira se suprotna funkcija (pomnožena sa -1)
|
|
(4.4) |
Ø Ograničenja tipa ≥: Množenje s -1 dobije se ≤ :
|
|
(4.5) |
Ø Ograničenje tipa = : Uvode se dva ograničenja ≥ i ≤ s istim iznosima
|
|
(4.6) |
Ø Ograničenja na strukturne varijeble: formiraju se dodatni reci.
Ø Struktura varijabla može biti negativna (dj ≤ xj; dj < 0): Uvodi se supstitucija
|
|
(4.7) |
Ø Strukturna varijabla može poprimiti bilo koju vrijednost (-∞ < xi < +∞): Uvodi se supstitucija
|
|
(4.8) |
Navedene transformacije najčešće se u praksi ne koriste, ali služe da bi se pokazala univerzalnost navedene definicije linearnog programiranja[3]
Definicija rješenja linearnog programa
Rješenjem se naziva bilo koja uređena n-torka (x1, …, xn) e Rn.
Rješenje je moguće ili dopustivo ako su sva postavljena ograničenja zadovoljena. Optimalno rješenje jest ono moguće rješenje za koje funkcija cilja z poprima maksimalnu vrijednost. Vršno moguće rješenje takvo je rješenje koje ne leži na spojnici bilo koja dva druga moguća rješenja.
Spojnica rješenja (x1', …, xn' ) i (x1'', …, xn'') jest skup
točaka
|
{px1''
+ (1-p) x1', …, pxn'' + (1-p) xn' } , 0 < p < 1 |
(4.9) |
Slika
4.1 prikazuje
spojnicu dviju točaka u dvodimenzionalnom prostoru. Sa slike je vidljivo da
vrijedi
|
|
(4.10) |
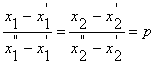
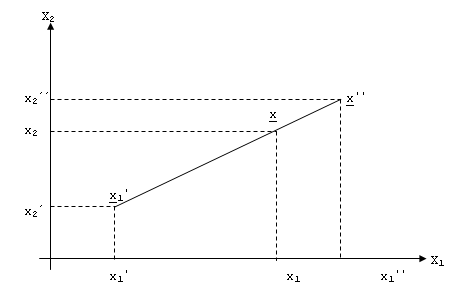
Slika 4.1 Spojnica
dvaju rješenja
Tako je za x1
|
|
(4.11) |
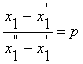
iz čega je
|
x1 = px1'' - px1' + x1' = px1'' + (1-p)x1'' |
(4.12) |
odnosno općenito
|
x = px'' + (1-p)x' |
(4.13) |
Dva vršna moguća rješenja jesu susjedna ako je njihova spojnica brid dopuštenog područja.
Ako postoji optimalno rješenje s vrijednosti funkcije cilja z*, onda se ono nalazi barem u jednom vrhu skupa. U suprotnom, ako su z´ i z´´ vrijednosti funkcija cilja u dva susjedna vrha, z* bude na njihovoj spojnici, vrijedilo bi
|
z* = pz'' + (1-p)z' , 0 < p < 1 |
(4.14) |
Iznos rješenja na spojnici je ponderiran prosjek vršnih rješenja. Kako je suma pondera jednaka 1, moguća su samo tri međusobna odnosa između z', z* i z'' :
z' < z* < z''
z' > z* > z''
z' = z* = z''
Prve dvije mogućnosti u suprotnosti su s pretpostavkom o optimalnosti z*. Iz treće mogućnosti slijedi da ako ima barem dva optimalna rješenja, onda je i njihova spojnica optimalno rješenje.[3]
Definicija simplex postupka
Simpleksnu metodu razvio je G.B.Dantzig 1947. godine. Od prve ugradnje na računalo pa sve do danas usavršavani su numerički postupci njene realizacije, ali se u osnovi nije mijenjala. Iako je bilo više pokušaja da se pronađe efikasniji algoritam, tek je 1984. N. Karmarker razvio upotrebljiv algoritam, čija su prva testiranja dala obećavajuće rezultate, pogotovo za rješavanje velikih problema (više desetaka tisuća ograničenja). Simpleksna metoda jest interaktivni postupak, koji u svakom koraku rješava sustav linearnih jednadžbi. Za rješavanje standardnog problema linearnog programiranja i uz uvjet
bi ≥ 0 za i = 1,…, m
algoritam se sastoji od više koraka.
Linearni program u standardnom obliku izražen strukturnim varijablama izgleda
|
|
(4.15) |
uvođenjem dopunskih varijabli prelazi u slijedeću formu
|
|
(4.16) |
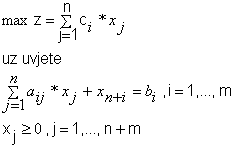
Sustav lineranih jednadžbi sad se sastoji od m jednadžbi s m+n nepoznanica. Rješenje tog sustava (s dopunskim varijablama) naziva se prošireno rješenje. Prošireno vršno rješenje naziva se bazičnim rješenjem.
Sustav u kojem ima više nepoznanica nego linearno nezavisnih jednadžbi, ima beskonačno mnogo rješenja. Da bi bazično rješenje bilo moguće, ono mora biti u prvom kvadrantu, zbog postavljenih uvjeta nenegativnosti.
Simultanim rješavajnem sustava od m linearnih jednadžbi s m+n nepoznanica dobije se bazično rješenje ako se prethodno izabere n varijabli i fiksira ih na 0. Te se varijable nazivaju nebazičnima.
Postoji najviše
|
|
(4.17) |
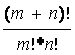
načina da se od m+n varijabli izabere njih n nebazičnih, prema tome ima isto najviše toliko bazičnih rješenja.
Sama po sebi nameće se ideja da se do optimuma dođe pronalaženjem svih bazičnih rješenja. Međutim, već sustav s 10 linearnih ograničenja i 5 nepoznanica ima
|
|
(4.18) |
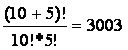
bazična rješenja. Sustav s 20 ograničenja i 10 nepoznanica ima čak 30045015 bazičnih rješenja, što bi značilo da za takav, u praksi zanemarivo malen problem, treba preko 30 milijuna puta rješiti sustav s 20 jednadžbi i 20 nepoznanica. Stvarni problemi iz prakse sastoje se od više stotina, pa i tisuća ograničenja, te je očito da ni na najbržim računalima taj pristup neće dovesti do rezultata. Zbog toga se u simpleksnoj metodi ispituju samo moguća bazična rješenja, i to tako da svako slijedeće rješenje nije lošije od prethodnoga. Za određivanje početnog bazičnog rješenja odabire se n nebazičnih varijabli. Te se varijable fiksiraju na nulu i time omogućuje jednoznačno rješavanje sustava od m jednadžbi s m nepoznanica. Pogodno je kao nebazične na početku odabrati strukturne varijable. Tada preostaje m dopunskih varijabli u m jednadžbi s tim da se svaka od tih dopunskih varijabli nalazi samo u po jednoj jednadžbi, i to s koeficjentom 1. Takav izbor omogućuje izravno očitavanje prvog mogućeg bazičnog rješenja. Ispituje se da li bi porast neke od nebazičnih varijabli poboljšalo funkciju cilja. Ako bi, obavlja se zamjena jedne takve ulazne nebazične i jedne izlazne bazične varijable, i to tako da novo bazično rješenje bude i dalje moguće. Kad se ne može naći takva ulazna nebazična varijabla koja bi svojim porastom s vrijednosti 0 poboljšala funkcija cilja, rješenje je optimalno.[3]
Simplex postupak kretat će se uvijek od vrha do vrha dopustivog područja prema boljem rješenju ili prema onom koje je barem jednako dobro. Valja naglasiti da promjena funkcije cilja ne mora uvijek biti kriterij koji će postupak najbrže dovesti do optimuma. Slika 4.2 prikazuje hipotetički primjer dopustivog područja u kojemu će postupak iz ishodišta krenuti u pravcu točke A jer je koeficjent funkcije cilja uz x2 veći. Izbor točke B kao slijedećeg vrha bio bi neusporedivo bolji, ali postupak to ne može uočiti.
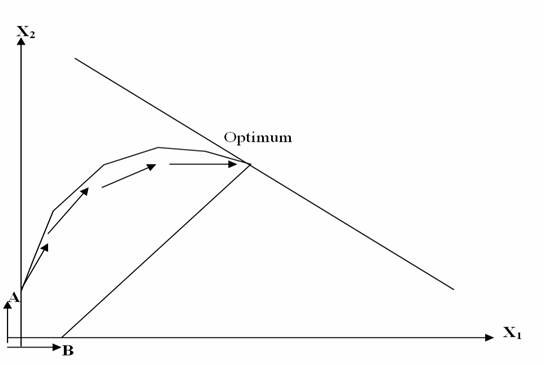
Slika 4.2. Kretanje simplex postupka prema optimumu
4.1.2 Primjena genetskog algoritma u simplex postupku
Prikaz rješenja
Rješenje je prikazano s pomoću prirodnog binarnog koda, te zbog ubrzanja algoritma također kao broj s pomičnom točkom. Zbog toga što je linearni program n-dimenzionalni problem svaki kromosom je sastavljen od N vektora koji predstavljaju pojedinu dimenziju zadanog problema. Kromosom kao N binarnih vektora predstavalja kodiranu vrijednost pojedine dimenzije xi e[dgi, ggi] gdje je ie[1, N]. Svaka dimenzija ima svoju dg (donja granica) i gg (gornja granica).
Dužina n binarnog broja utječe na preciznost i označava broj bitova, odnosno broj jedinica ili nula u jednoj dimenziji kromosoma. U takav vektor je moguće zapisati 2n različitih kombinacija nula i jedinica, tj. moguće je zapisati bilo koji broj u intervalu [0, 2n – 1]. Binarni vektor v(0) = [000…0] predstavlja vrijednost xi = dg, a vektor v(2n – 1) = [111…1] predstavlja vrijednost xi = gg. Općenito ako je binarni broj b e[0, 2n -1] zapisan kao binarni vektor v(b) = [Bn-1B n-2B n-3 …B1B0] gdje je B=0 ili B=1, tada vrijedi:
binarni broj:
|
|
(4.19) |
Dekodiranje je proces pretvaranja binarnog broja u potencijalno rješenje. U ovom slučaju potencijalno rješenje bilo koje dimenzije je bilo koji realni broj x u intervalu [dg, gg]. Binarni vektor v(b) predstavlja vrijednost x koja se izračunava prema formuli:
ekvivalent realni broj:
|
|
(4.20) |
Kodiranje, odnosno određivanje binarnog broja b za zadani realni broj x obavlja se prema formuli:
|
|
(4.21) |
Neka je x zadane preciznosti p i neka je peN. To znači da x odstupa od točnog rješenja za maksimalno 10-p. Odnosno, rješenje x je točno na p decimala. Rješenje x je preciznosti p ako je zadovoljena nejednakost :
|
|
(4.22) |
Za zadanu preciznost p, pojedina dimenzija zadanog kromosoma mora biti duljine n:
|
|
(4.23) |
Funkcija dobrote
Funkcija dobrote u implementaciji je ekvivalent funkciji cilja koja se optimira.
Na temelju funkcije dobrote određuje se koliko kromosom vrijedi. Vrijednost dobrote kromosoma koristi se u selekciji gdje se na temelju te vrijednosti određuje najlošija jedinka. Na kraju genetskog algoritma najbolja jedinka u populaciji se također određuje na temelju doborte.
Generiranje početne populacije
Svaki kromosom je izabran slučajnim odabirom iz domene problema. Svaka kordinata kromosoma mora zadovoljavati uvjete zadane u linearnom programu. Zbog gore navedena dva uvjeta postoji vjerojatnost da se generira kromosom koji ne zadovoljava zadane uvjete. Ako se generira nevaljani kromosom, isti se briše i ponovno se generira novi kromosom, i tako sve dok se ne generira cijela populacija. Algoritam koji je odredio gornje i donje granice problema nije u potpunosti točno odredio gg i dg zbog toga se svaki kromosom provjerava tako da se uvrsti u uvjete i provjeri da li ih zadovoljava.
Selekcija
Selekcija implementirana u programu je 3-turnirska eliminacijska selekcija.
U svakom koraku genetskog algoritma odabiru se nasumično 3 jedinke iz populacije. Nakon toga se uspoređuju dobrote svake odabrane jedinke te jedinka sa najlošijom dobrotom se briše iz populacije. Preostale dvije jedinke se križaju i stvaraju novu jedinku.
Križanje
Križanje implementirano u programu je jednoliko(uniformno) križanje. Svaki put se generira slučajni niz bitova R(slučajni kromosom).Križanje se izvršava nad preostala dva kromosoma iz selekcije i novim kromosomom R. Dijete se računa po formuli:
|
DIJETE = AB + R(AÅB) |
(4.24) |
Mutacija
Mutacija implementirana u programu je jednostavna mutacija. U kromosomu koji je nastao križajnem ostala dva selektirana kromosoma nasumično se odabire dimenzija, te se također nasumično odabire bit koji se mijenja. Vjerojatnost mutacije kromosoma je
|
PM » 1 – (1 – pm)n |
(4.25) |
gdje je n broj bitova odabrane dimenzije.
Primjer: pm = 0.005 (mutira se 5 bitova na 1000), n = 32; pM = 0.148 (14.8 %, tj. svaki 7 kromosom će biti mutiran).
Očekivni ukupni broj mutacija uz N novih članova populacije je pM*N.
Ukoliko nakon mutacije kromosom nije u dopuštenom području postupak se ponavlja, a ako se nemože generirati dobar kromosom mutacija se prekida i kromosom ulazi u populaciju bez mutacije.[3]
4.1.3 Sintaksa implementirane ulazne datoteke simplex postupka
Problem linearnog programa zadaje se kako je i matemetički formuliran s jednom malom promjenom. Na početku ulazne datoteke upisuje se dimenzija problema zbog jednostavnijeg parsiranja. Nakon što je datoteka isparsirana generiraju se matrice koje se upotrebljavaju u daljnjem izvođenju programa.
Tablica 4.1 Usporedba zapisa LP matematički i u programu
|
Matematička formulacija LP |
Implementacijska formulacija LP |
|
|
|
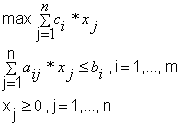
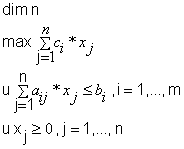
Prije svakog upisivanja uvjeta na početak reda upisuje se znak ''u'' koji označava da je u tom redku uvjet. Time se olakšalo pronalaženje i sortiranje uvjeta, funkcije cilja i dimenzije prilikom parsiranja ulazne datoteke.
4.2 Problem trgovačkog putnika
4.2.1 Definicija problema
Definicija koja jako dobro opisuje dani problem u njegovoj osnovnoj i najjednostavnijoj varijanti je slijedeća definicija:
Za dan skup gradova i cijenu putovanja između svakog para gradova, problem trgovačkog putnika (Traveling Salesman Problem, TSP) mora pronaći najjeftiniji put koji će obići sve gradove točno jednom i na kraju se vratiti u početni grad.
Razmatra se ovakva definicija problema uz uvjet da je cijena putovanja od grada A do grada B jednaka kao i cijena putovanja od grada B do grada A.
Iako je definicija vrlo jednostavna i jasna problem je jako težak, čak štoviše spada u klasu NP - teških problema. Točnije problem je faktorijalne složenosti što u prijevodu znači da za 10 gradova broj mogućih rješenja iznosi 10! = 3,628,800. Ako se ide gledati za veći broj gradova, što su u današnje vrijeme realne ture, 100 – tinjak gradova, broj mogućih tura se penje na približno 9.3e157, što se metodom grube sile (brute force) uz današnju snagu računala ne može riješiti 3e144 godina uz pretpostavku da je broj ruta koje današnje računalo može obraditi po sekundi jednak 1.000.000 .
Problem se osim gornje definicije može proširiti dodavanjem različitih ograničenja gornjoj definiciji. Tako je nastao i vremenski ovisan problem trgovačkog putnika, koji uz minimalnu duljinu puta u obzir uzima i vrijeme koje je potrebno da se put obavi kao i eventualni vremenski periodi u kojima se jedan dio posla mora napraviti. Uz ovu defniciju postoji još i asimetrični problem trgovačkog putnika u kojemu put između grada A i grada B nije isti kao i put između grada B i grada A. Uz ove definicije postoje još i mnoge druge. [4]
4.2.2 Genetski algoritmi i problem trgovačkog putnika
Iz definicije problema vidi se da bi genetski algoritmi kao stohastička metoda za pretraživanje mogla biti korisna u rješavanju problema TSP. Zbog načina rada genetski algoritmi ne pretražuje cijeli prostor rješenja već pomoću posebno definiranih operatora križanja i mutacija evoluira rješenje. Za praktičnu primjenu genetski algoritmi dobivaju još jedan plus zbog toga što u praksi nije nužno naći optimalni put već je dovoljno dobar put i onaj koji je u okolici optimuma. Također rad algoritma je moguće regulirati i usmjeravati podešavanjem parametara.
Uz sve ovo moguće je i kombinirati genetske algoritme s metodama traženja lokalnog optimuma kako bi pojedina jedinka što brže konvergirala prema svom optimumu koji je potencijalno i globalni. Takvi se algoritmi nazivaju hibridnima. [4]
Prikaz kromosoma
Iako postoji više mogućih načina prikaza za ovaj rad odabran je najintuitivniji prikaz koji se može prikazati na slijedeći način:
( 0 , 1 , 3 , 5 , 4 , 6 , 2 , 7 )
U ovom prikazu postoji 8 gradova koje treba obići, a redosljed obilaska je slijedeći: kreće se iz grada 0, pa u grad 1, nakon njega 3 itd. Dakle mjesto u osmorki označava kada će taj grad biti posjećen. A broj koji je na tom mjestu označava sam grad. Ukratko, gradovi su poredani u smjeru u kojem se posjećuju. Ovaj način prikaza je uobičajen u TSP implementacijama.
Još jedan način prikaza koji se koristi je matrični prikaz. Matrica je tipa n * n i to je zapravo matrica susjedstva u grafu koji se dobiva povezivanjem svih gradova. Ako postoji put iz grada A u grad B tada je na mjestu M[A,B] jedinica, inače je 0. No zbog kompleksnosti on nije ovdje korišten, iako je po brzini izvođenja bolji prikaz od ovdje korištenog i danas se ide u smjeru razvoja operatora za ovakav način prikaza kromosoma. [4]
Funkcija cilja
Funkcija cilja je jednostavna formula koja zbraja udaljenosti između gradova, dajući tako za svaki kromosom ukupnu dužinu puta. Naravno, što je dužina puta kraća, kromosom je bolji i ima veću šansu za opstanak.
Operatori selekcije
Ø
Prirodna
selekcija
Iz početne se populacije eliminira R = M x pe / 100 jedinki. Jedinke se eliminiraju tako da se sačuva različitost populacije, odnosno eliminiraju se slične jednike. Za početak cijela se populacija sortira prema dobroti. Nakon toga se uspoređuje sličnost dobrota susjednih jedniki i ukoliko je njihova razlika manja od predefiniranog malog realnog pozitivnog broja ε, eliminra se jedna od n – torki. To se ponavlja dok je broj eliminiranih jedniki manji od R. Ako je nakon ovog postupka broj eliminiranih jedinki i dalje manji od R eliminiraju se jedinke s lošijom vrijednošću funkcije dobrote.
Ø
Turnirska
selekcija
Turnirska selekcija je zapravo vrlo jednostavana. Iz cijelokupne populacije odabere se k jedinki (k je veličina turnira, obično između 3 i 7) te se najlošija od njih izbaci. Od ostatka jedniki slučajnim se odabirom odabiru dvije koje se onda križaju i daju novu jedniku koja ulazi na mjesto stare u populaciju. [4]
Operatori križanja
Ø
Partially matched crossover (PMX)
PMX križanje je vrlo jednostavno, a radi na slijedeći način:
U oba roditelja označe se dvije točke prekida. (Slika 4.3 prikazuje točke prekida s |) geni između tih
točaka se zamijene u oba roditelja, što daje slijedeće: 3 zamjenjuje
2, 8 zamjenjuje 4, 4 zamjenjuje 1 i obratno.
Sada se popunjava ostatak kromosoma tako da se gradovi izvan
točaka prekida vraćaju na svoje mjesto ukoliko već ne postoje kao rezultat
zamjene. U tom se slučaju na mjesto grada koji postoji upisuje onaj kojeg
mijenja novopridošli grad. Npr. kada se nakon zamjene želi u prvo dijete
staviti grad 1 on već postoji (novija jedinica pridošla iz drugog kromosoma).
Sada na mjesto jedinice dolazi 8 jer 4 zamjenjuje 1, a kako i 4 već postoji u
kromosomu 8 zamjenjuje 4.
|
(2 5 1 | 3 8 4 | 7 6) (8 6 7 | 2 4 1 | 3 5) postaje (3 5 8 | 2 4 1 | 7 8) (1 6 7 | 3 8 4 | 2 5) |
Slika 4.3 PMX križanje
PMX križanje ima problem jer želi populaciju odvući u lokalni
optimum što se mora rješiti korištenjem mutacije. [4]
Ø
Greedy crossover
Definicja Greedy Crossover križanja je slijedeća:
„Greedy Crossover uzima prvi grad jednog roditelja, uspoređuje gradove u koje se dolazi iz tog grada u oba roditelja te uzima onog čiji je put kraći. Ako se je jedan grad već pojavio u djetetu tada se uzima drugi. Ako su oba u djetetu tada se slučajnim odabirom odabire jedan neodabrani grad“.Ovo križanje je jako efikasno i brzo skraćuje ture.
Operatori mutacije
Ø Jednostavna mutacija
Kao što joj i ime kaže jednostavna mutacija radi tako da uzme dva slučajno odabrana grada u kromosomu i zamjeni njihova mjesta. Prikazana zamjena 5 i 1: [4]
|
(3 5 4 2 6 1 7 8) postaje (3 1 4 2 6 5 7 8) |
Slika 4.4 Jednostavna mutacija
4.2.3 Sintaksa implementirane ulazne datoteke TSP problema
|
<TSP>
<info>
<brojGradova>4</brojGradova>
</info>
<tocke>
<t0>0 3</t0>
<t1>1 0</t1>
<t2>2 7</t2>
<t3>1 0</t3>
</tocke>
</TSP> |
Slika 4.5 Sintaksa ulazne datoteke
Unutar tag-ova <brojGradova> upiše se veličina problema, dok se unutar tag-ova <tocke> upisuju koordinate gradova (x i y koordinata).[4]
4.3 P – median problem
4.3.1 Definicija problema
Problem lokacije objekata ima više primjena u telekomunikacijama, industrijskom prijevozu, distribuciji, itd. Jedan od najpoznatijih problema lokacije je p-median problem. Problem se sastoji od lociranja p objekata u danom prostoru (Euklidov prostor) koji zadovoljava n zahtjeva i to tako da ukupna suma udaljenosti između svakog zahtjeva i najbližeg sredstva bude minimalna.
U bez kapacitetnom p-median problemu, podrazumjeva se da svaki objekt koji je kandidat za median može zadovoljiti neograničen broj zahtjeva. Suprotno bez kapacitetnom p-median problemu u kapacitetnom p-median problemu svaki objekt ima fiksan kapacitet, i maksimalan broj zahtjeva koje mora zadovoljiti. P-median problem je NP-težak problem. Zbog toga, heurističke metode koje su specijalizirane za rješavanje spomenutog problema zahtjevaju značajan računalni napor.
Da bi rješili ovaj problem predložen je genetski algoritam (GA) specifičan za kapacitetan p-median problem.
Genetski algoritam koji će se opisati naziva se Cap-p-Med-GA.
Neslužbeno, cilj p-median problema je da odredi p objekata u predefiniranom setu sa n (n > p) kandidiranih objekata da bi zadovoljili set zahtjeva, tako da je ukupna suma udaljenosti između zahtjevane točke i najbližeg objekta minimalna. P objekata koji sačinjavaju rješenje problema se zovu mediani.
Službeno, pod predpostavkom da su svi vrhovi grafova potencijalni mediani, p-median problem se može definirati ovako: G = (V,A) neusmjeren graf gdje je V vrh a A su rubovi. Cilj je naći set vrhova VpÌV (median set) sa kardinalnošću p, tako da je suma udaljenosti između preostalih vrhova u {V - Vp} (zahtjevani set) i najbližim vrhom u Vp minimalna.
Slijedećim nizom formula (4.26, 4.27, 4.28, 4.29, 4.30) prikazana je formulacija p-median problema u uvjetima cjelobrojnog programiranja predložena od Revelle i Swaina (1970). Ova formulacija dopušta da se svaki vrh uračuna, u isto vrijeme, kao i zahtjevi i objekti (potencijalni median), ali u mnogim slučajevima (uključujući stvarnu primjenu) zahtjevi i objekti pripadaju disjunktnim skupovima. [5]
|
|
(4.26) |
|
|
(4.27) |
|
|
(4.28) |
|
|
(4.29) |
|
|
(4.30) |
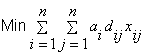
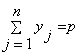
Gdje je :
n – ukupan broj vrhova u grafu,
ai – zahtjev vrha j
dij – udaljenost izmedu vrhova i i j
p – broj zauzetih objekata kao mediana
![]() 1, ako je vrh i dodjeljen sredstvu j
1, ako je vrh i dodjeljen sredstvu j
xij
0, inače
1, ako je vrh j upotrebljen kao median
Yj
0, inače
Ciljna funkcija (4.26) minimizira sumu udaljenosti između zahtjeva vrhova i skupova mediana. Ograničavajuća forumla (4.27) garantira da će svi zahtjevani vrhovi biti dodjeljeni točno jednom medianu. Ograničavajuća formula (4.28) zabranjuje da zahtjevani vrh može biti dodjeljen objektu koji nije izabran kao median.
Ukupan broj mediana je definiran sa izrazom (4.29) kao jednakost za p. Ograničenje (4.30) garantira da su vrijednosti izabranih varijabli x i y binarne (0 ili 1).
Pod predpostavkom da su svi vrhovi grafa potencijalni mediani, p-median problem može se formalno definirati sa G= (V,A) G = (V,A) neusmjeren graf gdje je V vrh i A su rubovi. Cilj je naći set vrhova VpÌV (median set) sa važnosti p, tako da je:
a) suma udaljenosti između preostalih vrhova u {V - Vp} (zahtjevani set) i najbližim vrhom u Vp minimalna, i
b) sve zahtjevane točke su zadovoljene bez narušavanja ograničavajućih kapaciteta medianih objekata.
Uspoređivanjem sa p-median problemom, kapacitetni p-median problem ima dodatna ograničenja:
1. svaki objekt mora zadovoljiti limitirani broj zahtjeva (ograničavanje objekata).
2. sve zahtjevne točke moraju biti zadovoljene poštivajući kapacitet objekata izabranih kao mediani.
Realan primjer:
Savezno svučilište Parane (UFPR), u Curitibi, Brazil, osnovano je 1912. kao prvo savezno brazilsko sveučilište. Trenutno pruža 61 preddiplomski smjer, 84 specijalistička smjera (sve diplomirani stupanj), 37 smjerova znanstvenih i stručnih magisterija i 21 smjer doktorata. Ne diplomirani studenti su izabrani preko prijamnog ispita koji pišu svi prijavljeni kandidati. Za ispit iz 2001. predložilo se da kandidati pišu ispite u objektima koji su što bliže njihovim domovima (da bi se vidjela udaljenost između doma svakog kandidata i objekta, sve su adrese bile precizno locirane u digitalnu kartu grada Curitibe ). Odredili su algoritam koji je izabrao 26 objekata koji moraju primiti 19710 kandidata, od 43 kandidirana objekta. Problem je predstavljen kao p-median problem zbog sljedećeg: [5]
- 43 objekta (potencijalne lokacije) je set V (|V|=43) od svih kandidiranih objekata za median (izabrane lokacije)
- Vp ÌV (|Vp|=26) je set od 26 izabranih lokacija
- svaka od 43 potencijalne lokacije može zadovoljiti limitirani broj kandidiranih studenata
- cilj je izabrati set VpÌV koji će minimizirati ukupnu udaljenost između kuće kandidiranog studenta i najbliže lokacije (median).
4.3.2 Genetski algoritam i P-median problem
Svaki kromosom ima točno p gena, gdje p broj mediana i alel svakog gena predstavlja indeks (jedinstveni id broj) za svaki objekt označen kao median.
Za primjer, ako se uzme problem od 15 objekata (potencijalnih mediana) označenih sa indeksima 1,2,…,15. Predpostavimo da želimo označiti 5 mediana. U genetskom algoritmu jedinka [2, 7, 5, 15, 10] predstavlja kandidata za rješenje gdje su objekti 2,5,7,10,15 označeni kao mediani.
Funkcija dobrote
Dobrota pojedine jedinke je vrijednost funkcije cilja. Funkcija cilja predstavljena je izrazom (4.26).
Selekcija
Selekcija je zasnovana na ranking-based selekciji koju je predložio Mayerle(1996) slijedećim izrazom:
|
|
(4.31) |
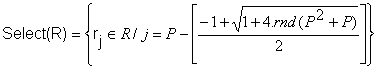
Gdje je:
Ø R lista, R = (r1, r2,…, rp) sa P jedinki sortiranih u padajućem redosljedu prema funkciji dobrote.
Ø rnd Î [0,1], uniformno-distribuiran nasumičan broj
Izraz (4.31) vraća poziciju jedinke u listi R. Formula je zasnovana na temelju davanja prednosti jedinci u prijašnjoj poziciji liste R.
Populacija evoluira prema steady-state metodi. Potomci se dodaju u populaciju samo ako imaju bolju funkciju dobrote od najlošije jedinke u populaciji.
Operator križanja
Cap-p-Med-GA izračunava dva zamjenjiva vektora, po jedan za svakog roditelja. Za svaki gen od roditelja 1, Cap-p-Med-GA provjerava da li je alel (indeks sredstva) od gena 1 sadržan u genomu roditelja 2. Ako nije indeks objekta je kopiran u zamjenjiv vektor od roditelja 1 to znači da indeks objekta može biti prebačen u roditelja 2 kao rezultat križanja, tako ta zamjena neće stvoriti duplikat indeksa objekta u genotipu roditelja 2. Ista procedura je primjenjena za sve ostale indekse objekata u genotipu roditelja 2.
Za primjer, ako se odaberu dva roditelja sa indeksima objekata:
R1=[1,2,3,4,5]
R2=[2,5,9,10,12]
Zamjenjivi vektori pojedinih roditelja su:
zR1 = [1,3,4]
zR2 = [9,10,12]
Kada su indeksi objekata koji se mogu zamjeniti pronađeni, može se primjeniti operator križanja na slijedeći način.
U Cap-p-Med-GA primjenjena je fiksna vjerojatnost križanja. Križanje je moguće izvesti nad svim jedinkama koje su različite odnosno gdje je barem jedan indeks objekta u zamjenjivom vektoru od roditelja 1 i roditelja 2. Ako su dva roditelja jednaka njihovi izmjenjivi vektori su prazni, tada jedan od roditelja ostaje nepromjenjen za slijedeću generaciju a drugi roditelj se briše, time se osigurava da ne postoje duplikati u populaciji.
Križanje se primjenjuje na slijedeći način. Slučajan prirodan broj c koji se nalazi između 1 i broja elemenata u zamjenjivom vektoru -1 (cÎ[1, rank[zamjenjiv_vektor]-1]). Broj c uvjetuje koliko će indeksa objekata svakog vektora zamjene biti zamjenjeno između dva roditelja. Takva procedura garantira da neće biti duplih indeksa objekata, niti u jednom djetetu nastalom križanjem roditelja. Takvim križanjem roditelja nastaju dva djeteta. [5]
Operator mutacije
Mutacija je primjenjena na slijedeći način. Geni mutiraju tako da se alel zamjeni sa drugim slučajno geneiranim alelom (indeks objekta), jedini uvjet je da novi indeks objekta već ne postoji u trenutnom genotipu jedinke. [5]
4.3.3 Sintaksa implementirane ulazne datoteke P-median problema
Prvi redak ulazne datoteke mora imati slijedeći oblik:
p <n> <m> <p>
Gdje je:
<n> - broj vrhova,
<m> - broj rubova
<p> - broj objekata
Zatim poslije prvog redka mora biti točno <m> redaka sa slijedećim oblikom:
e <v1> <v2> <cost>
Gdje je:
<v1> - vrh 1
<v2> - vrh 2
<cost> - cijena između dva navedena vrha
Vrhovi imaju oznake od 1 do n, gdje je n broj vrhova.
4.4 Problem kvadratičnog pridruživanja
4.4.1 Definicija problema
Problem kvadratičnog pridruživanja(QAP) su predstavili Koopmans i Beckmann 1957. godine kao matatatički model za lokaciju nedjeljivih ekonomskih aktivnosti. Želimo dodjeliti n objekata na n lokacija sa cijenom proporcionalnom kretanju između objekata, pomnoženu sa udaljenošću između lokacija. Cilj je dodjeliti svakom objektu njegovu lokaciju tako da ukupna cijena bude minimalna.
Problem se može modelirati pomoću dvije (n * n) matrice:
A = (aij), gdje je aij kretanje od objekta i do objekta j
B=(bkl), gdje je bkl udaljenost između lokacija k i l
Problem kvadratičnog pridruživanja u Koopmans-Beckmann formi zapisuje se na slijedeći način:
|
|
(4.32) |
Gdje je :
Ø Sn - skup svih permutacija cijelih brojeva od 1 do n. Sn Î [1,n];
Ø Svaki umnožak ap(i) p(j)bij je cijena prouzročena dodjelom objekta p(i) lokaciji i i objekta p(j) lokaciji j
Problem kvadratičnog pridruživanja sa ulaznim parametrima kao dvijema matricama zapisuje se sa QAP(A,B). Ako su koeficjeniti matirce a ili b simetrični, QAP(A,B) se naziva simetrični QAP, inače se naziva asimetrični.
Problem kvadratičnog pridruživanja osim u teoriji lokacija, ima primjenu i u mnogim drugim problemima, kao: problem razmještaja, povezivanje elemenata vodičem na tiskanoj pločici, u proizvodnji računala, vremenskom planiranju, u procesu komunikacije.
Problem kvadratičnog pridruživanja je NP-težak problem. [6]
4.4.2 Genetski algoritam i problem kvadratičnog pridruživanja
Strategija zamjena - Selekcija
Strategija zamjena odnosi se na strategiju selekcije, koja definira kako selektirati slijedeću generaciju potomaka. Posebno je važna za visoko ograničene probleme jer vodi algoritam pretraživanja kroz dozvoljeno područje i tako utječe na performanse algoritma. Najčešća upotrebljavana strategija zamjena je steady-state. U svakoj generaciji jedinke su selektirane kako bi se nad njima izvršili genetski operatori. Svaki novi potomak uspoređuje se sa najgorim članom u trenutnoj generaciji, i njime će biti zamjenjen. [6]
Cilj nove strategije je poboljšanje sposobnosti globalnog pretraživanja algoritma. Uključuje dvije različite strategije zamjena replace-worst i replac-parent strategije.
Ø replace-worst strategija primjenjuje se jednom svakih Tc generacija. Dobrota novog potomka se uspoređuje sa najgorim kromosomom u populaciji, ako je dobrota potomka bolja nego dobrota najlošijeg kromosoma tada zamjenjujemo potomka i najlošiji kromosom. Prilagođavanjem frekvencije primjene replace-wors strategije konvergencija procesa pretraživanja i raznolikost populacije može biti dobro uravnotežena.
Ø replace-parent strategija primjenjuje se jednom u svakoj generaciji, svaki novi potomak uspoređuje se sa svojim roditeljom (kromosom prije mutacije). Ako je dobrota potomka bolja nego dobrota njegova roditelja tada potomak zamjenjuje roditelja.
Model genetskog algoritma zasnovanog na novoj strategiji zamjena opisana je na slijedeći način. U modelu , replace-worst strategija primjenjuje se jednom svakih Tc generacija (Tc se naziva period replace-worst strategije). [6]
|
Begin Stvori početnu populaciju; za svaku generaciju slučajno odaberi jedinke iz
populacije; primjeni genetske operatore na
generirane potomke; if nije u i´Tc
generaciji usporedi svakog potomka sa
njegovim roditeljom i obriši lošijeg; inače usporedi svakog potomka sa
najlošijim članom populacije i obriši lošijeg; ponavljaj
dok nije zadovoljen jedan od uvjeta End |
Slika 4.6 GA zasnovan na novoj strategiji zamjena
Prikaz kromosoma
U genetskom algoritmu za QAP iskorišten je prikaz permutacije.
Gen predstavlja da je objekt 5 postavljen na lokaciju 2
Slika 4.7 Izgled kromosoma
Na slici vrijednost svakog gena predstavlja objekt koji je dodjeljen određenoj lokaciji. U kromosomu prikazanom na slici postoji 10 objekata postavljenih na 10 lokacija. Npr. drugi gen u kromosomu znači da je objekt 5 postavljen na lokaciju 2. [6]
Funkcija cilja
Cilj genetskog algoritma je minimizacija ukupne cijene C kako je opisano u izrazu (4.32). Funkcija cilja za kromosom u genetskom algoritmu je definirana na slijedeći način:
|
|
(4.33) |
Gdje je fi dobrota kromosoma i a Ci je stvarna vrijednost. [6]
Operator križanja
Specijalan tip uniformnog križanja sa konstantnim postotkom izmjene gena. Postotak izmjene gena je postavljen na malu vrijednost npr. 20%, tako će svako od dvoje djece biti puno sličnije jednom od svojih roditelja. Križanje je prikazanao na slici (X).
Nakon križanja, jedinke A i B stvaraju C i D. Definiramo A kao direktnog roditelja od C pošto su međusobno slični, i definiramo B kao direktan roditelj od D. [6]
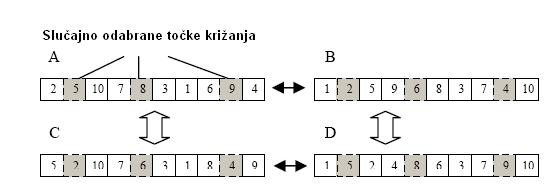
Slika 4.8 Operator križanja
U svakoj generaciji svaki kromosom se uparuje sa drugim kromosom nasumično. Operator križanja bit će primijenjen na sve parove kromosoma.
Operator mutacije
Kroz uvodna testiranja uviđeno je da operator mutacije nema puno utjecaja na performanse GA, pa zbog toga netreba implementirati operator mutacije. [6]
4.4.3 Sintaksa implementirane ulazne datoteke problema kvadratičnog pridruživanja
|
Dimenzija matrce mA a00 …….a0n …. …. an0………ann mB b00 …….b0n …. …. bn0………bnn |
Slika 4.9 Sintaks ulaze datoteke
Dimenzija matrice - određuje dimenziju matrica, tj. broj redaka i broj stupaca u ulaznoj datoteci.
mA- predstavlja početak zapisa podataka za matricu A
mB- predstavlja početak zapisa podataka za matricu B
4.5 Problem osnovnog budžeta
4.5.1 Definicija problema
Originalan problem budžeta odnosi se na maksimizaciju ukupnog neto profita ograničavanjem budžeta birajući prikladne kombinacije projekta. Sa iskazanim zahtjevima, dvojba za buduće zahtjeve i više kontradiktornih ciljeva, uzeto je slučajno ograničeno cjelobrojno programiranje za rješavanje problema budžeta.
Slučajno ograničeni model programiranja može biti promjenjen u deterministički ekvivalent kada su stohastičke varijable normalno rasprostranjene. Međutim, problem je obično teško transformirati u determinističku formu ako problem sa stohastičkim varijablama pripada drugoj klasi ili su ograničenja nepravilna. Ispravan način rješavanja generalnog slučajno ograničenog modela programiranja (neprekinut slučaj) predložili su Iwamura i Liu; stohastička simulacija zasnovana na genetskom algoritmu gdje genetski algoritam provjerava slučajna ograničenja. Unatoč tome, Liu i Iwamura razvili su tehniku slučajno ograničenog programiranja sa neodređenim parametrima rađe nego sa stohastičkim parametrima.
Dizajnirali su neodređene simulacije zasnovane na genetskim algoritmima za rješavanje sličnih modela.
Problem budžeta u neodređenom okruženju prikazan je u novom pristupu kojeg su prikazali Iwamura i Liu. Ujedinjavanjem postupaka promjenjivih parametara vodi do jedinstvenog neodređenog modela problema budžeta. Model je isti kao i stohastički model osim činjenice da stohastički parametri i Pr su zamjenjeni sa noedređenim parametrima i Pos, gdje Pos predstavlja vjerojatnost neodređenih događaja.[7]
Predpostavljamao da kompanija želi uvesti nove strojeve u proizvodnju. Predpostavljamo sa postoji n dostupnih strojeva. Ako sa xi označimo broj tipova i strojeva tada xi' predstavlja nenegativan cjelobrojni broj. Neka je ai količina sredstava koju treba izdvojiti za stroj tipa i. Neka je a ukupni raspoloživi kapital, tada imamo slijedeću formulu:
|
|
(4.34) |
Ukupan kapital upotrebljen za kupnju strojeva ne smije premašiti raspoloživ iznos. Slijedeće ograničenje je maksimalno raspoloživo prostorno ograničenje za strojeve. Predpostavimo da bi je prostor koji zauzima tip stroja i. Ako je ukupan slobodan prostor b tada imamo slijedeće ograničenje:
|
|
(4.35) |
Predpostavljamo da različiti strojevi proizvode različite proizvode. Neka je ci proizvodni kapacitet stroja i za proizvod i, tada je ukupni iznos proizvoda i jednal cixi. Također predpostavljamo da će buduća potražnja za proizvodima i biti bi. Zato što proizvodnja mora zadovoljiti buduću potražnju imamo slijedeće ograničenje
|
|
(4.36) |
Ako je pi neto profit po tipu stroja i tada je ukupni neto zarada p1x1+ p2x2 + … + pnxx. Cilj je maksimizirati ukupnu zaradu:
|
|
(4.37) |
Dakle, deterministički model za problem budžeta temeljen na cjelobrojnom programiranju glasi:
|
|
(4.38) |

U stvarnosti problem budžeta je puno kompleksniji od gore spomenutog modela. [7]
4.5.2 Genetski algoritam i problem osnovnog budžeta
Postoje dva načina prikaza rješenja optimizacijskog problema, binarni vektor i vektor sa realnim vrijednostima. Ako uzmemo binarni vektor kao kromosom koji predstavlja stvarnu vrijednost varijable odluke, tada duljina vektora ovisi o potrebnoj preciznosti. Drugi pristup je implementacija kromosoma koji su kodirani kao vektori realnih brojeva iste duljine kao i vektor rješenja. Vektor
V = (x1, x2,…,xn)
kao kromosom koji predstavlja rješenje optimizacijskog problema gdje je n dimenzija problema.
U problemu budžeta sve varijable xi su cijeli brojevi. Jezikom C++ vektor V je int polje dimenzije n. [7]
Inicijalizacija
Definira se cijeli broj pop_size kao broj kromosoma i nasumično generiramo pop_size kromosoma. Za kompleksnije optimizacijske probleme, kompleksnije je generirati početnu populaciju kromosoma koji zadovoljavaju sve uvjete. Postoje dva načina inicijalizacije početne populacije ovisno o informacijama koje donositelj odluka može dati.
Prvi slučaj je da donositelj odluka može utvrditi unutrašnju točku, označenu sa V0 u dozvoljenom području. Također definira se veliki pozitivan broj M koji osigurava da će primjena svih genetskih operatora najvjerojatnije završiti u dozvoljenom području. Broj M također se koristi u operatoru mutacije. Početna populacija kromosoma bit će stvorena na slijedeći način. Nasumično odaberemo smjer d u Rn i definiramo kromosom V kao V0 +M*d ako je to moguće rješenje, inače definiramo M kao slučajan broj između 0 i M dok V0 +M*d ne postane moguće rješenje. Proces ponavljamo pop_size puta. Ako donositelj odluka ne uspije pronaći unutarnju točku, tada može unaprijed odrediti područje koje sadrži mogući skup rješenja. Mogući prostor je oblika n-dimenzijske hiperkocke, a računalo lako može generirati točke unutar hiperkocke. Nasumično generiramo točke unutar hiperkocke i provjeravamo da li točka zadovoljava uvjete. Ako točka zadovoljava uvjete tada je dodajemo u početnu populaciju inače nanovo generiramo točku dok god točka ne zadovolji uvjete. [7]
Funkcija cilja
Funkciju cilja označimo sa eval(V), koja označava vjerojatnost reprodukcije za svaki kromosom V. To znači da je vjerojatnost selekcije relativno proporcionalna dobroti ostalih kromosoma u populaciji, tj. kromosom sa boljom funkcijom cilja ima veću vjerojatnost stvaranja potomaka pomoću selekcije kotačem ruleta. [7]
Neka je parametar a Î [0, 1] tada definiramo rank-based evolucijsku funkciju na slijedeći način:
|
|
(4.39) |
Selekcija
Selekcija je proces zasnovan na okretanju rulet kotača pop_size puta., svaki put odaberemo jedan kromosom za novu populaciju na slijedeći način: [7]
Ø Korak 1. Izračunamo sumu vjerojatnosti qi za svaki kromosom Vi
|
|
(4.40) |
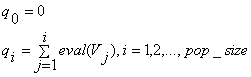
Ø Korak 2. Generiraj slučajan broj r Î [0, qpop_size]
Ø Korak 3. Odaberi i-ti kromosom Vi (1 £ i £ pop_size) tako da qi-1 < r £ qi
Ø Ponovi korake 2. i 3. pop_size puta i dodaj novih pop_size kromosoma
Operator križanja
Definiramo parametar Pc kao vjerojatnost križanja. Ta vjerojatnost nam daje očekivani broj Pc * pop_size kromosoma nad kojima će biti primijenjen operator križanja, generirajući slučajan realan broj r iz intervala [0,1]. Kromosom Vi je odabran kao roditelj ako je r < Pc.
Označimo odabrane roditelje na slijedeći način V1',V2',V2', … i podjelimo ih u parove
(V1',V2'), (V3',V4'), (V5',V6'), …
Križanje se provodi na slijedeći način: Generiramo slučajan broj c iz otvorenog intervala<0,1>. Križanjem roditelja V1' i V2' dobivamo dva djeteta:
|
|
(4.41) |
Aritmetičko križanje ne osigurava da oba djeteta budu u mogućem području pa zbog toga moramo provjeriti svako dijete. Ako su oba djeteta u mogućem području zamjenimo roditelje sa njihovom djecom, inače ponovno obavljamo križanje sa drugim slučajnim brojem c dok djeca ne budu u dopuštenom području. [7]
4.5.2.1 Operator mutacije
Definiramo parametar Pm kao vjerojatnost mutacije. Ta vjerojatnost nam daje očekivani broj Pm*pop_size kromosoma nad kojima će biti primjenjena mutacija. Isto kao i kod odabira roditelja za operator križanja ponavljamo korake od i=1 do pop_size generirajući realan broj r iz intervala [0,1], kromosom Vi odabiremo ua mutaciju ako je r < Pm.
Za svaki odabrani kromosom zapisan kao V = (x1, x2,…,xn) mutiramo ga na slijedeći način, odaberemo slučajan smjer mutacije d iz Rn , ako V + M*d nije moguće zbog ograničenja, tada mijenjamo M kao slučajan broj između 0 i M dok V ne postane moguće rješenje. Ako oba procesa ne mogu pronaći moguće rješenje u predviđenom broju koraka tada postavimo M = 0. I zamjenimo roditelja V sa djetetom [7]
|
|
(4.42) |
4.5.3 Sintaksa implementirane ulazne datoteke problema osnovnog budžeta
|
dim n max {Funkcija cilja} a {Funkcija ukupnog raspoloživog kapitala} b {Funkcija ograničenja prostora} {Buduća potražnja} |
Slika 4.10 Sintaksa ulazne datoteke
Ključne riječi : dim, a, b.
Gdje je:
Ø n- broj različitih tipova stroja
Ø Funkcija cilja - Ukupna zarada
5. PROGRAMSKI SUSTAV ZA RJEŠAVANJE OPTIMIZACIJSKIH PROBLEMA
Proširivi programski sustav omogućuje na jednostavan način implementaciju novih problema i novih algoritama. Programski sustav nazvan je „Optimization Framework“.
5.1 Opis glavnih cjelina programskog sustava Optimization Framework
5.1.1 Glavni asembliji programskog sustava
Dva asemblija su bazni dio programskog sustava.
Ø Slika 5.1 prikazuje Asemblij Optimization_framework - asemblij u kojem se nalazi:
o Glavna MDI forma (Main) – sadrži sve projekte
o Forma u kojoj se odabire tip problema i algoritma (Wizard)
o Klasa koja komunicira sa bazom (DataBaseEntry)
o Pobrojni tip ComplitedProjects - sadrži popis gotovih projekata (problem + algoritam)
o Pomoćne klase ListViewItemExtend i TreeNodeExtend koje su nasljeđene iz .net klasa ListViewItem i TreeNode te im je dodana funkcionalnost pohrane dodatnih podataka

Slika 5.1. Asemblij Optimization_framework
Ø Slika 5.2 prikazuje Asemblij CommonClass – asemblij u kojem se nalaze bazne klase, sučelja i pomoćne klase:
o Bazna forma WorkingSession – bazna klasa koja sadrži svu logiku upravljanja odabranim projektom
o Sučelje IAlgorithm – sučelje koje sadrži metode i svojstva koje svi algoritmi moraju implementirati
o Sučelje IinputParser – sučelje koje moraju implementirati svi parseri ulaznih datoteka
o Sučelje IoutputParser – sučelje koje moraju implementirati svi parseri izlaznih datoteka
o Bazna UserControla AlgorithmManager – bazna kontrola koju mora implementirati upravljačka kontrola algoritma.
o Pobrojni tip ImplementedAlgorithmType – na temelju njegovih podataka odabire se implementirani algoritam
o Kontrola DecimalTextBox – nasljeđena od .net kontrole TextBox kojoj je dodana mogućnost parsiranja decimalnih brojeva, omogućava upis samo brojeva, točke i predznaka
o Klasa DynamicalCall – dinamički poziva parsere na temelju imena i asemblija. Pomoću refleksije dinamički alocira objekte, pojednostavljuje izvedbu implementacije
o Forma Progress – u novom procesu prikazuje napredak algoritma koji se izvršava u glavnom procesu
o Klasa ProjectSerializer – klasa koja omogućava spremanje na disk i učitavanje sa diska odabrane projekate.
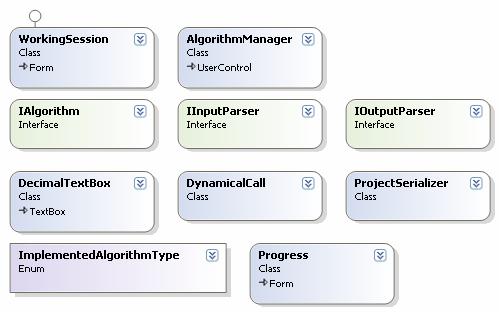
Slika 5.2. Asemblij CommonClass
5.1.2 Početna forma programskog sustava
Glavna forma je MDI(Multipla Document Interface) forma, to znači da sve nove forme koje pokrenemo nalaze se unutar glavne forme. Glavna forma je roditelj svim novim formama. Na glavnoj formi nalazi se izbornik sa gumbom „Novi problem“ pritiskom miša na isti otvara se prozor koji omogućuje odabir problema i za njih implementiranih algoritama. MDI forma omogućuje kompaktnu i cjelovitu kontrolu nad svim pokrenutim formama što je i potrebno za ovaj projekt.
5.1.3 Forma za odabir problema i algoritma
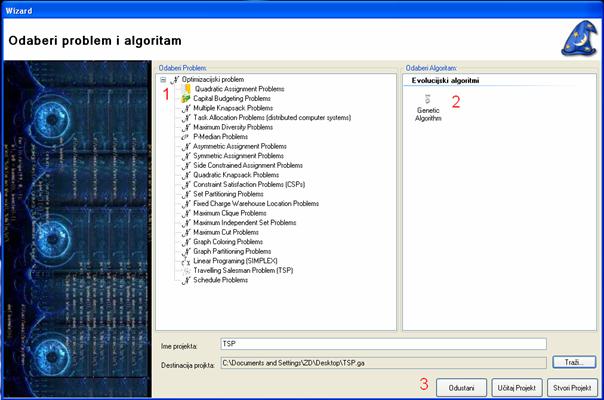
Slika 5.3 Čarobnjak za kreiranje projekta
Slika 5.3 prikazuje formu za odabir problema i algoritma. Nakon odabira problema u odjeljku 1 omogućuje se odabir algoritama u odjeljku 2 koji su implementirani za odabrani problem. Nakon odabira algoritma upisuje se ime projekta te destinacija projekta gdje se isti može spremiti kako bi se kasnije ponovno mogao pokrenuti. Popis problema i algoritama se nalazi u Access bazi koja će biti objašnjena u nastavku.
Ako želite stvoriti novi projekt odaberete gumb „Stvori projekt“ a ako želite pokrenuti spremljnu verziju odabranog problema i algoritma odaberete gumb „Učitaj projekt“.
5.1.4 Baza podataka
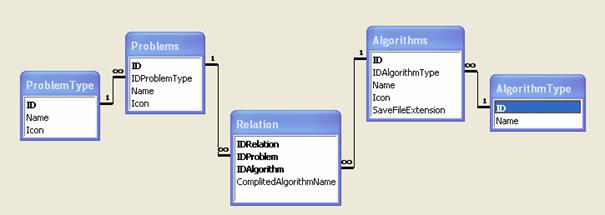
Slika 5.4 Baza podataka
Slika 5.4 prikazuje bazu podataka u kojoj tablice Problems i Algorithms sadrže popis problema i algoritama. Svaki problem je iz neke porodice problema (trenutno su implementirani samo optimizacijski problemi) pa je zbog toga tablica Problems povezana sa tablicaom ProblemType.
Svaki algoritam je također iz neke porodice algoritama (npr. evolucijski algoritam) te je zbog toga tablica Algorithms povezana sa tablicom AlgorithmType.
Svaki algoritam može rješitit više različitih problema, a isto tako svaki problem se može rješiti pomoću više različitih algoritama pa je iz tog razloga potrebna tablica Relation koj povezuje tablice Algoriths i Problems.
Tablica Algorithms:
Ø ID – jedinstveni id algoritma
Ø
IDAlgorithmType
– označava tip algoritma
Ø
Name –
ime algoritma. Na temelju podatka zapisanom u tom polju odabire se
implementirani algoritam
Ø
Icon –
Ikona koja će biti prikazana pri odabiru algoritama
Ø
SaveFileExtension
– ekstenzija datoteke sa kojom se sprema projekt
Tablica AlgorithmType:
Ø Name – Naziv tipa algoritma
Tablica Problems:
Ø ID – jedinstveni id problema
Ø IDProblemType – označava tip problema
Ø Name – ime problema
Ø Icon – ikona koja će biti prikazana pri odabiru problema
Tablica ProblemType:
Ø Name – naziv tipa problema
Ø Icon – ikona koja će biti prikazana uz ime tipa problema u korijenu stabla gdje se odabiru problemi
Tablica Relation:
Ø IDRelation – jedinstveni id relacije
Ø IDProblem – id problema
Ø IDAlgorithm – id algoritma
Ø ComplitedAlgorithmName – naziv implementiranog algoritma koji rješava zadani problem sa zadanim algoritmom. Na temelju toga imena odabire se određeni implementirani problem.
Klasa u programskom sustavu koja komunicira sa gore opisanom bazom podataka naziva se DataBaseEntry nalazi su u asembliju Optimization_Framework u direktoriju DataBaseConnection. Imenički prostor je Optimization_Framework DataBaseConnection.DataBaseEntry.
Preporuka je da sve statičke podatke vezane za probleme i algoritme koji će se implementirati stavljaju u bazu podataka. Komunikacija sa bazom trebala bi se odvijati samo na jednom mjestu, tj. u gore navedenoj klasi. Trenutno komunikacija se odvija samo između glavne forme i baze podataka, u slučaju da neki od implementiranih problema treba komunicirati sa bazom podataka tada bi se cijela klasa trebala prebaciti u asemblij CommonClass kako bi se izbjegla cirkularna referenca.
5.2 Implementacija novih problema u programski sustav
Za implementaciju novih problema potrebno je napraviti slijedeći niz radnji.
5.2.1 Dodavanje novog asemblija
U Solution Optimization Framework dodati novi projekt u slijedećem nizu koraka:
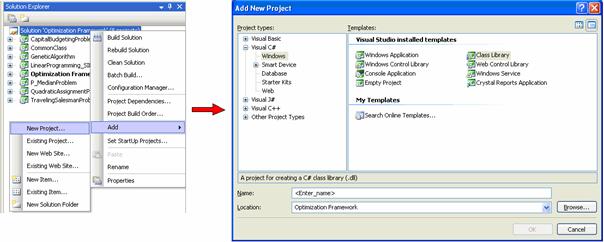
Slika 5.5 Dodavanje novog projekta
Tip novog projekta je ClassLibrary. Nakon dodavanja novog projekta u Solution potrebno je dodati referencu na taj asemblij i na asemblije koji će biti pozivani iz istog.
Slika 5.6 prikazuje dodavanje reference između novog asemblija i asemblija Optimization Framework što omogućuje implementaciju koda koji poziva novi projekt.
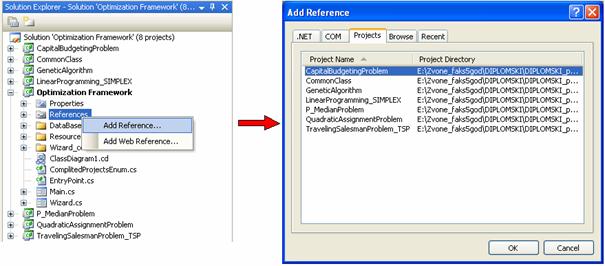
Slika 5.6 Dodavanje reference između novog projekta i Optimization framework asemblija
Nakon klika na Add Reference… u novo otvorenom prozoru potrebno je odabrati ime novog projekta i kliknuti na OK.
Slijedeći korak je dodavanje reference između novog projekta i CommonClass asemblija u kojem se nalaze bazne klase problema i algoritama. Ta refernca nam omogućuje implementaciju definicije problema i algoritma. Slika 5.6 prikazuje postupak s tom razlikom što se referenca dodaje u novi projekt, a u novo otvorenom prozoru odabire se CommonClass projekt.
Slijedeći korak je dodavanje direktorija u novom projektu. Svaki projekt mora imati slijedeće direktorije :
Ø
InputFileParsers
– sadrži parsere ulaznih datoteka.
Ø
OutputFileParsers
– sadrži parsere izlaznih datoteka.
Svi parseri moraju biti spremljeni u gore navedene direktorije kako bi se mogli dinamički pokretati pomoću Refleksije. Takav postupak olakšava dodavanje novih parsera jer nigdje u kodu netreba dodavati kod koji povezuje nove parsere.
5.2.2 Dodavanje statičkih podataka novog projekta u bazu podataka
U tablice Problems i ProblemType dodaju se statički podaci koji su bitini za novi projekt.
Tablica Problems :
Ø U IDProblemType - polje dodaje se id tipa problema, ako tip problema nije naveden u tablicu ProblemType dodaje se naziv tipa problema i njegov id te se taj novi id upise u polje.
Ø U Name - polje dodaje se ime novog projekta
Ø U Icon - polje dodaje se ikona koja predstavlja novi problem, ikona se dodaje tako da se iznad polja postavi kazaljka miša i klikne desna tipka te se u padajućem izborniku odabere se Insert Object… , u novo otvorenom prozoru odabere Create New te se pod Object Type odabere Bitmap Image i nakon toga se klikne na OK. Nakon toga otvori se Paint program od Windowsa te se u njega kopira slika i nakon taoga se samo zatvori.
Tablica ProblemType - ako ne postoji tip problema koji se implementira tada se dodaju slijedeći podaci:
Ø ID – id tipa problema koji se upisuje u tablicu Problems u polje IDProblemType
Ø Name – Tipa problema
Ø Icon – Ikona koja predstavlja tip problema
U tablice Algorithms i AlgorithmType dodaju se statički podaci koji su bitni za algoritam u novom projektu.
Tablica Algorithms :
Ø U IDAlgorithmType – polje dodaje se id tipa algoritma, ako tip algoritma nije naveden u tablici AlgorithmType dodaje se naziv tipa algoritma i njegov id te se taj novi id upisuje u polje.
Ø U Name - polje dodaje se ime implementiranog algoritma
Ø U Icon - polje dodaje se ikona koja predstavlja novi algoritam, ikona se dodaje tako da se iznad polja postavi kazaljka miša i klikne desna tipka te se u padajućem izborniku odabere Insert Object… , u novo otvorenom prozoru odabere se Create New te se pod Object Type odabere Bitmap Image i nakon toga se klikne na OK. Nakon toga otvori se Paint program od Windowsa te se u njega kopira slika i nakon taoga se samo zatvori.
Ø
U SaveFileExtension
- polje dodaje se ekstenzija datoteke u koju se sprema projekt. Prilikom
spremanja trenutnog projekta uzima se ekstenzija i tako se zna koji algoritam
treba učitat.
Tablica AlgorithmType - ako ne postoji tip algoritma koji se implementira tada se dodaju sljedeći podaci:
Ø ID – id tipa algoritma koji se upisuje u tablicu Algorithms u polje IDAlgorithmType
Ø Name – Tipa problema
Ø Icon – Ikona koja predstavlja tip problema
Nakon dodavanja potrebnih podataka u tablice Problems i Algorithms potrebno je povezati problem i algoritam. To se radi tako da se id problema i id algoritma upiše u novi redak tablice Relation, te se u polje ComplitedAlgorithmName doda kodno ime novog projekta kako bi se na temelju toga imena pozvala forma koja prikazuje novi projekt.
5.2.3 Implementacija sučelja novog problema
Implementacija sučelja novog problema započinje stvaranjem forme koja nasljeđuje baznu formu WorkingSession iz asemblija CommonClass.
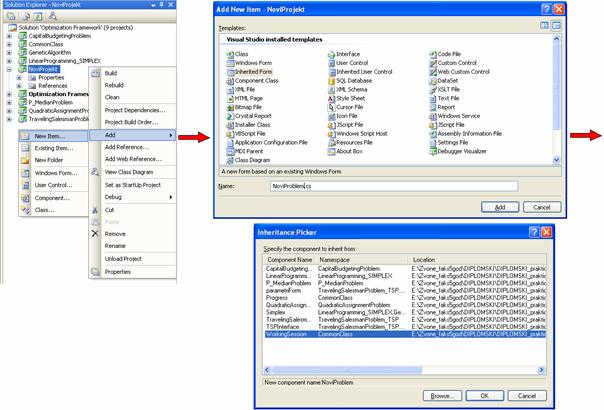
Slika 5.7 Dodavanje nasljeđene forme za novi problem
Desnim klikom miša iznad novog projekta u padajućem izborniku odabire se Add i nakon toga New Item… . U novo otvorenom prozoru odabere se tip forme Inherited Form i klikne se na Add. Na slijedećem prozoru odabere se pod Component Name bazna forma WorkingSession koja se nalazi u CommonClass asembliju. Slika 5.8 prikazuje formu koju Visual Studio nakon postupka generira.
Slika 5.8 Sučelje novog problema
Forma sadrži nekoliko glavnih cjelina, prostor za odabir izlaznih i ulaznih datoteka(1), prostor za postavljanje sučelja algoritma(2), program komunicira sa korisnikom pomoću kontrole (4), kontrola (3) sadrži tri pod cjeline Definicija problema, Rezultati, Grafički prikaz rezultata na koje se dodaju nove kontrole kojima će biti prikazan novi problem. Sva logika oko učitavanja ulaznih, izlaznih datoteka, pokretanja parsiranja te prikaz rezultata je implementiran. Kako bi cijela logika bila potpuna potrebno je nadjačati (override) i implementirati sljedeći niz metoda:
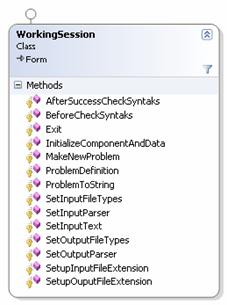
Slika 5.9 Metode novog problema koje treba implementirati
Tablica 5.1 Opis metoda novog problema
|
Metoda |
Uloga
metode |
|
AfterSuccessSyntaks |
Metoda se poziva nakon
uspješnog parsiranja ulazne datoteke. Nije nužno implementirati istu. |
|
BeforeCheckSyntaks |
Metoda se poziva prije početka
parsiranja ulazne datoteke. Nije nužno implementirati istu. |
|
Exit |
Metoda se poziva nakon
zatvaranja forme |
|
InitializeComponentAndData |
Metoda se poziva iz
konstruktora forme. Dobro je u tu metodu prebaciti InitializeComponent metodu,
te u svaki konstruktor koji se napravi dodati poziv iste. U metodu staviti
sav kod koji je zajednički za sve konstruktore. |
|
MakeNewProblem |
Metoda mora moći obrisati
prethodni problem sa kontrole koja omogućuje opis problema. |
|
ProblemDefinition |
Metoda mora postaviti
problema na kontrolu koja je predviđena za to i dinamičkim pozivom vratiti
objekt koji parsira odabrani problem. |
|
ProblemToString |
Poziva se prilikom spremanja
ulazne datoteke na disk. Metoda mora vratiti problem u obliku tekstualnog
zapisa. |
|
SetInputFileTypes |
Metoda puni DataTable strukturu sa nazivom parsera
ulazne datoteke i ekstenzijom datoteke |
|
SetInputParser |
Dinamički vrača objekt koji
parsira ulaznu datoteku, ali ne šalje tekst koji se parsira. Poziva se
prilikom odabira ulaznog tipa datoteke. |
|
SetOutputFileTypes |
Metoda puni DataTable strukturu sa nazivom parsera
izlazne datoteke i ekstenzijom datoteke |
|
SetOutputParser |
Metoda dinamički alocira
objekt koji parsira izlaznu datoteku |
|
SetupInputFileExtension |
Metoda vraća string koji
definira filter u OpenFileDialog
kontroli za ulaznu datoteku |
|
SetupOutputFileExtension |
Metoda vraća string koji
definira filter u OpenFileDialog
kontroli za izlaznu datoteku |
5.2.4 Implementacija parsera ulaznih i izlaznih datoteka
Slika 5.10 Odabir parsera ulaznih i izlaznih datoteka
Parser ulazne datoteke implementira se tako da se nasljedi sučelje IInputParser koje se nalazi u CommonClass asembliju. Slika 5.11 prikazuje parser ulaznih datoteka.
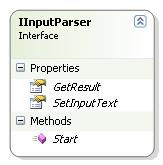
Slika 5.11 Parser ulaznih datoteka
Tablica 5.2 Članovi ulaznog parsera
|
Svojstvo |
Uloga |
|
GetResult |
Nakon uspješno isparsirane
ulazne datoteke dohvaćamo rezultat parsera. |
|
SetInputTex |
Prije pokretanja parsera,
parseru predajemo definiciju problema. |
|
Metoda |
Uloga |
|
Start |
Pokreče parsiranje ulazne
datoteke |
Parser izlazne datoteke implementira se tako da se nasljedi sučelje IOutputParser koje se nalazi u CommonClass asembliju.
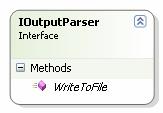
Slika 5.12 Parser izlaznih datoteka
Tablica 5.3 Članovi izlaznog parsera
|
Metoda |
Uloga |
|
WriteToFile |
Metoda zapisuje rezultat
izvođenja algoritma u datoteku. |
Bitna napomena:
Imena klasa ulaznih i izlaznih parsera moraju biti jednaka ekstenziji datoteke koju parsiraju. Time je automatizirano pozivanje novih parsera sa postojećim sustavom.
Primjer:
Ime datoteke: primjer1.simplex
Ime parsera: Simplex.cs
5.3 Implementacija novih algoritama u programski sustav
Implementacija novog algoritma počinje sa nasljeđivanjem baznog sučelja algoritma koje se nalazi u asembliju CommonClass pod imenom AlgorithmManager. Slika 5.13 prikazuje implementaciju novog algoritma.
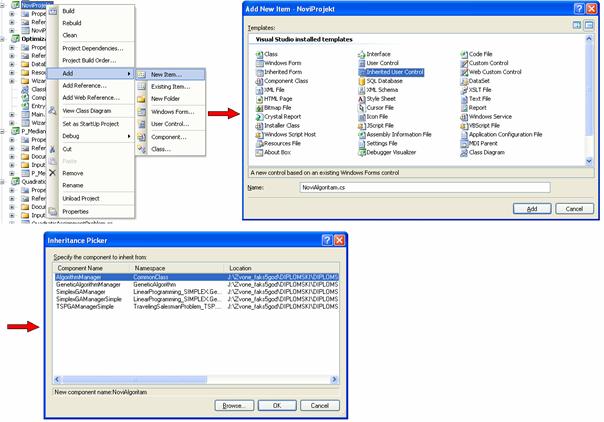
Slika 5.13 Dodavanje nasljeđene ''User contorl'' za novi algoritam
Visual Studio nakon gore navedenog postupka generira slijedeću User Control-u. Komunikacija između sučelja za definiranje problema i sučelja za definiranje algoritma odvija se preko događaja FinishedAlgorithm koji se okida kada algoritam uspješno završi, i svojstva InputData i OutputData preko kojih se prosljeđuju podaci. Na sučelju novog algoritma postoje kontrole koje su već implementirane, to su gumb Start i Stop. Navedene kontrole služe za pokretanje i zaustavljanje izvođenja algoritma. Slika 5.14 prikazuje implementaciju sučelja.
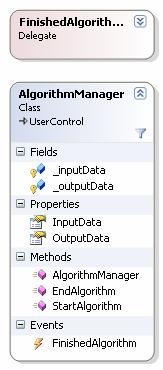
Slika 5.14 Definicija korisničke kontrole algoritma
Tablica 5.4 Članovi korisničke kontrole algoritma
|
Metoda |
Opis |
|
AlgorithmManager |
Konstruktor |
|
StartAlgorithm |
Metoda koja se mora
nadjačat u novom algoritmu i implementirat pokretanje algoritma. |
|
EndAlgorithm |
Metoda se mora nadjačat u
novom algoritmui implementirat ''nasilno'' zaustavljanje algoritma |
|
Svojstva |
Opis |
|
InputData |
Svojstvo preko kojega algoritam
prima ulazne podatke |
|
OutputData |
Svojstvo preko kojega
algoritam prosljeđuje rezultat izvođenja algoritma |
|
Događaji |
Opis |
|
FinishedAlgorithm |
Kada algoritam uspješno završi
okida se događaj te se tako daje do znanja da je algoritam završio |
5.4 Integracija novog projekta u postojeći sustav
Nakon implementacije novog problema i algoritma, slijedeći korak je integracija u postojeći sustav. Povezivanje u postojeći sustav izvodi se u nekoliko koraka.
- U asembliju Optimization_Framework u klasi ComplitedProjectsEnum potrebno je dodati ime problema koji je zapisan u bazu podataka u tablicu Relation u polje ComplitedAlgorithmName. Time je povezan problem sa postojećim sustavom.
- U metodu SelectedProblem koja se nalazi u formi Wizard potrebno je dodati novi case dio (noviProblem zamjeniti sa stvarnim nazivom problema):
|
case ComplitedProjects.noviProblem: session = new NoviProblem.noviProblem(extendData,
GetTypeOfSelectedAlgorithm()); break; |
Slika 5.15 Novi dio SlectedProblem metode
- U asembliju CommonClass u klasu ImplementedAlgorithmType potrebno je dodati ime algoritma koji je zapisan u bazu podataka u tablicu Algorithms u polje Name. Time je povezan algoritam sa postojećim sustavom.
- U metodu GetTypeOfSelectedAlgorithm koja se nalazi također u formi Wizard potrebno je dodati novi case dio(noviAlgoritam zamjeniti sa stvarnim nazivom algoritma):
|
case "NoviAlgoritam": return ImplementedAlgorithmType.NoviAlgoritam; break; |
Slika 5.16 Novi dio GetTypeOfSelectefAlgorithm metode
5.5 Učitavanje i spremanje projekata
Za svaki projekt koji se stvori u sustavu omogućeno je spremanje i ponovno učitavanje.Takva funkcionalnost sustava omogučena je upotrebom serijalizacije iz .NET okruženja. Koristi sejednostavna metoda serializacije pomoću BinaryFormatter klase. Ova metoda primjenjena zbog toga što spremljene projekte ponovno učitava sustav koji je napravljen u .NET okruženju. Ukoliko bi se projekti učitavali u sustave izrađene u drugim razvojnim okruženjima potrebno bi bilo napraviti novi način serializacije u XML dokumente. Kako bi se omogučilo takvo ponašanje sustava potrebno je napraviti sljedeći niz radnji:
Ø Svakoj klasi koju je potrebno spremiti mora se dodati atribut Serializable
|
[Serializable] public class Simplex { } |
Slika 5.17 Atribut za serializaciju projekta
Ø Potrebno je nasljediti sučelje Iserializable
|
[Serializable] public class Simplex : Iserializable { } |
Slika 5.18 Sučelje za serializaciju projekta
Ø Implementirat metodu GetObjectData koja je dio sučelja Iserializable, za nasljeđene klase u sustavu potrebno je također pozvati metodu GetObjectData iz bazne klase. Te nakon toga u objek info dodati ključ i vrijednost podatka.
|
[Serializable] public class Simplex : ISerializable { #region
ISerializable Members public
void GetObjectData(SerializationInfo
info, StreamingContext context) { GetObjectData(info, context); info.AddValue("var1", this.var1); info.AddValue("var2", this.var2); } #endregion } |
Slika 5.19 Implementacija sučelja za serializaciju projekta
Ø U klasu dodati novi konsturktor koji će se pozivati prilikom učitavanja projekta. Potrebno je pozvati i bazni konstruktor.
|
[Serializable] public class Simplex : ISerializable { |ISerializable Members| public
Simplex(SerializationInfo info, StreamingContext context) : base(info,
context) { this.var1
= (type)info.GetValue("var1", typeof(type)); this.var2
= (type)info.GetValue("var2", typeof(type)); } } |
Slika 5.20 Konstruktor objekta koji se serializira
5.6 Priprema projekta za instalaciju
U razvojnom projektu sustava napravljen je projekt kojim se ''Optimization framework“ kroz čarobnjak instalira na računalo korisnika. Za pokretanje programa koji je instaliran potreban je samo .NET framework 2.0. Time je omogućena jednostavna primjena sustava gdje nije instaliran Visulal Studia 2005. Postupak dodavanja novih asemblija u setup instalaciju dodaje se sljedećim nizom koraka:
Ø
Dvostrukim klikom na dokument Primary output from Optimization Framework
(Active) u projektu Optimization
Framework Setup otvara se sljedeća
forma. Slika 5.21 prikazuje formu setup projekta. Na lijevoj strani
forme odabire se Application Folder.
|
|
Slika 5.21 Forma za kreiranje setup projekta
Ø Desnim klikom miša iznad desne strane forme sa (Slike) otvara se izbornik u kojem se klikne na Add -> Assembly... i odabere asemblij koji se želi dodati u setup.
Ø Nakon gore navedenog niza koraka potrebno je ponovno izgraditi projekt (Build).
6. PRIMJERI IMPLEMENTIRANIH PROBLEMA
6.1 Implementacija Linearnog programiranja (SIMPLEX postupak)
Slika 6.1 Definicija problema i pokretanje algoritma
Nakon što se upiše definicija problema pokreće se parsiranje problema i algoritam. Nakon uspješno završenog algoritma prikazuje se rezultat problema. Rezultat problema zapisan je u tablici dok su međurezultati zapisani u izlazu.
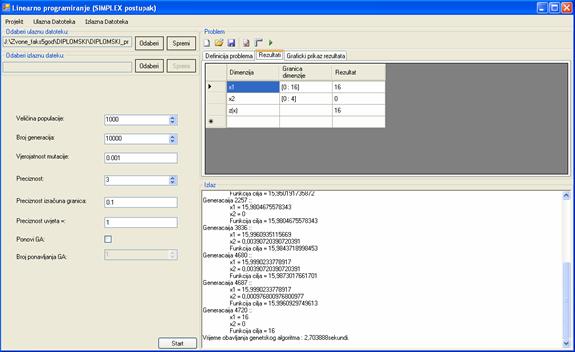
Slika 6.2 Rezultat problema
Tablica 6.1 Osnovni dijelovi sučelja problema
|
Alatna traka |
Sadrži osnovne naredbe koje
se koriste prilikom upravljanja programa. Otvaranje postojeće datoteke,
stvaranje nove datoteke, spremanje posttojeće datoteke. Provjeravanje sintakse
problema, izračunavanje granica dimenzija, pokretanje genetskog algoritma. |
|
Parametri genetskog algoritma |
Veličina populacije,
vjerojatnost mutacije, broj generacija(broj ponavljanja genetskog algoritma),
preciznost- označava na koliko decimala je točan rezultat. |
|
Prostor za definiranje problema |
Upisuje se definicija
linearnog programa |
|
Statusna traka |
Prijavljuju se greške, i
svaki korak izvođenja programa |
|
Tablica rezultata |
Prikazan je rezultat svake
dimenzije te ukupno rješenje funkcije cilja. |
6.2 Implementacija problema trgovačkog putnika – TSP
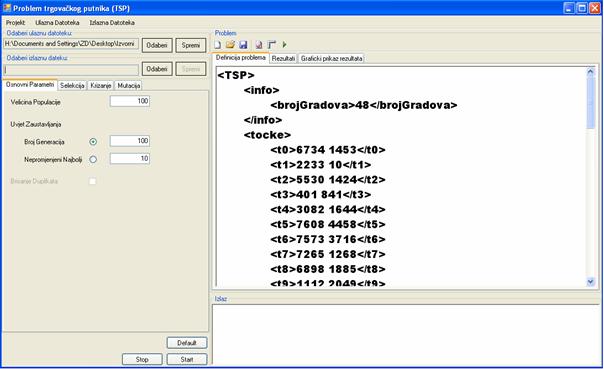
Slika 6.3 Ulazna datoteka u kojoj je definiran problem
Nakon što se upiše definicija problema pokreće se parsiranje problema. Nakon uspješno isparsirane ulazne datoteke, prikazuje se raspored gradova na panelu.
Slika 6.4 Raspored gradova
Nakon uspješno isparsirane ulazne datoteke pokreče se algoritam te se nakon uspješno izvršenog algoritma prikazuje optimalan put.
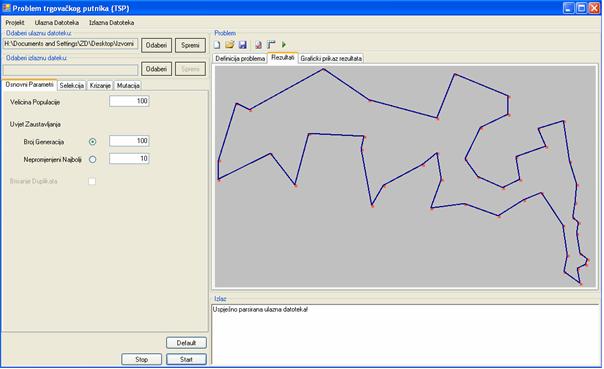
Slika 6.5 Prikaz optimalnog puta
6.3 Implementacija P-median problema
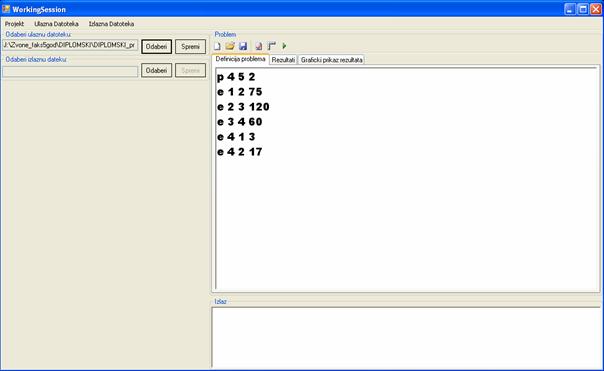
Slika 6.6 Ulazna datoteka u kojoj je definiran problem
Za P-medina problem definiran je zapis problema a time i parser ulazne datoteke. Omogućen je direktan upis u sustav ili upis probelma preko ulazne datoteke.
Nakon što se učita ulazna datoteka sustav će ju parsirat, te ukoliko nema grešaka javlja da je uspješno obavljeno parsiranje. Osim učitavanja ulazne datoteke omogućeno je da korisnik upiše problem te odabere jedan od ponuđenih parsera. Ukoliko korisnik direktno upisuje problem obavezno mora odabrati jedan od ponuđenih parsera kako bi se uspješno pokušao parsirati ulazni tekst problema. Ako ne postoji željeni parser, jednostavnim dodavanjem klase i implementiranjem željenog načina parsiranja omogućit će se uspješno parsiranje problema.
Prostor za definiranje sučelja algoritma je prazno te se jednostavnim kodom može dodati u formu problema navedenim postupkom u poglavlju 5.3.
6.4 Implementacija problema kvadratičnog pridruživanja
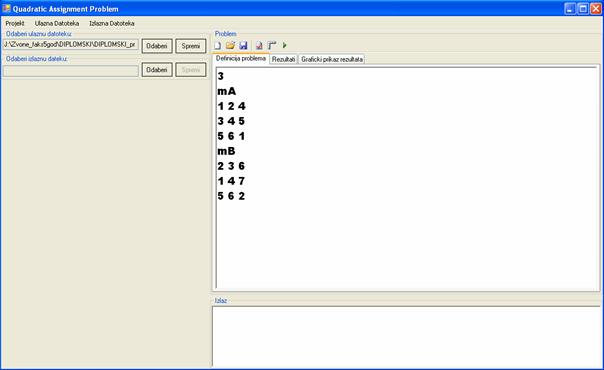
Slika 6.7 Definicija problema
Za probelm kvadratičnog pridruživanja definiran je zapis problema a time i parser ulazne datoteke. Omogućen je direktan upis u sustav ili upis problema preko ulazne datoteke.
Nakon što se učita ulazna datoteka sustav će ju parsirat, te ukoliko nema grešaka javlja da je uspješno obavljeno parsiranje. Osim učitavanja ulazne datoteke omogućeno je da korisnik upiše problem te odabere jedan od ponuđenih parsera. Ukoliko korisnik direktno upisuje problem obavezno mora odabrati jedan od ponuđenih parsera kako bi se uspješno pokušao parsirati ulazni tekst problema. Ako ne postoji željeni parser, jednostavnim dodavanjem klase i implementiranjem željenog načina parsiranja omogućit će se uspješno parsiranje problema.
Prostor za definiranje sučelja algoritma je prazno te se jednostavnim kodom može dodati u formu problema navedenim postupkom u poglavlju 5.3.
6.5 Implementacija problema osnovnog budžeta
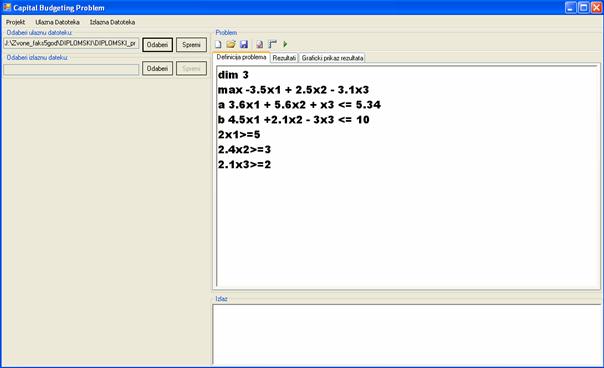
Slika 6.8 Definicija problema
Za probelm osnovnog budžeta definiran je zapis problema a time i parser ulazne datoteke. Omogućen je direktan upis u sustav ili upis problema preko ulazne datoteke.
Nakon što se učita ulazna datoteka sustav će ju parsirat, te ukoliko nema grešaka javlja da je uspješno obavljeno parsiranje. Osim učitavanja ulazne datoteke omogućeno je da korisnik upiše problem te odabere jedan od ponuđenih parsera. Ukoliko korisnik direktno upisuje problem obavezno mora odabrati jedan od ponuđenih parsera kako bi se uspješno pokušao parsirati ulazni tekst problema. Ako ne postoji željeni parser, jednostavnim dodavanjem klase i implementiranjem željenog načina parsiranja omogućiti će se uspješno parsiranje problema.
Prostor za definiranje sučelja algoritma je prazno te se jednostavnim kodom može dodati u formu problema navedenim postupkom u poglavlju 5.3.
6.6 Zaključna razmatranja
Genetski algoritam koji je izrađen za problem linearnog programiranja s velikom uspješnočću pronalazi rješenja koja su približno jednaka onim optimumima koji se dobivaju simpleks postupkom.[3] Prednost genetskog algoritma nad simpleks postupkom je u tome što za velike probleme gdje je broj nepoznanica(dimenzija problema) jako velik simpleks postupak postaje neučinkovit. U konačnom vremenu simpleks postupak ne može naći rješenja takvog problema, dok genetski algoritam nakon što je zadovoljen uvjet zuaustavljanja daje barem nekakve rezultate. Genetski algoritam ne koristi tako puno memorije kao što korisit simpleks postupak. Simpleks postupak u svom rješavajnu linearnih programa korisiti velike tablice odnosno velike matrice nad kojima obavlja operacije.
Dosta velik problem je bio odrediti donje i gornje granice svake dimenzije problema. Što je broj dimenzija odnosno nepoznanica u linearnom programu veći to implementiranom programu treba više vremena za njihovo određivanje. Vrijeme određivanja gornjih i donjih granica dosta je duže od vremena potrebnog genetskom algoritmu da pronađe rješenja.
Genetski algoritam koji je izrađen za problem trgovačkog putnika također s velikom uspješnošću pronalazi rješenja.[4] Također, vidi se da su genetski algoritmi korisni za one klase problema koje se ne mogu rješiti na klasične načine. Iako po brzini nisu u vrhu, po veličini područja koje pretražuju su vjerovatno daleko bolji od svih ostalih metoda. To se jako dobro vidi na primjeru problema trgovačkog putnika, čiji je prostor rješenja ogroman već i za stotinjak gradova. Praktični rad je pokazao kako je jedna od najbitnijih stvari za uspješan rad algoritma ispravan odabir genetskih operatora kao i parametara koji će odrediti ponašanje tih operatora. Ako se oni ispravno odrede algoritam daje fantastične rezultate, no ako se je nijhov odabir nesmotren algoritam će najvjerojatnije završiti rad u nekom lokalnom optimumu, bliže ili dalje od pravog optimuma, ovisno o parametrima.
Implementiranim sustavom puno će lakše biti testiranje algoritama na temelju njihovih parametara, jer se sve nalazi na jednom mjestu. Omogućeno je spremanje projekata čime se dobiva na mobilnosti rezultata i samih projekata. Sustav je napravljen modularno, čime je omogućeno lagano dodavanje problema, algoritama i novih funkcionalnosti sustava.
Bitne funkcionalnosti sustava koje treba dodati su:
- Načiniti bazne klase za algoritme, npr. za genetski algoritam potrebo je dodati bazne klase za sve dijelove genetskog algoritma, te napraviti generičke klase koje imaju ponašanje npr. kao jednostavni genetski algoritam s turnirskom selekcijom. Time se dobije mogućnost rješavanja optimizacijskih problema sa različitim operatorima i genetskim algoritmima jer generičke kalse znaju manipulirati sa različitim ulaznim podacima.
Primjer jednostavnog gentskog algoritma:
|
public class
SimpleGeneticAlgorithmEngine<T> : IAlgorithm where T : IGeneticAlgorithm { private T _geneticAlgorithm; public T GeneticAlgorithm { get { return
_geneticAlgorithm; } set { _geneticAlgorithm = value;
} } public SimpleGeneticAlgorithmEngine(T
geneticAlgorithm) {
_geneticAlgorithm = geneticAlgorithm; }
#region IAlgorithm Members Dictionary<object,
object> IAlgorithm.GetResults { get { return
_geneticAlgorithm.GetResults; } } Dictionary<object,
object> IAlgorithm.SetInputData { set {
_geneticAlgorithm.SetInputData = value; } } void IAlgorithm.Start() {
_geneticAlgorithm.InitialPopulation(); while (_geneticAlgorithm.StopConstranit()) {
_geneticAlgorithm.Selection();
_geneticAlgorithm.Crossover();
_geneticAlgorithm.Mutation(); } }
#endregion } |
Slika 6.9 Primjer jednostavnog genetskog algoritma
Generička klasa SimpleGeneticAlgorithmEngine definira ponašanje jednostavnog genetskog algoritma. Nasljeđuje IAlgorithm sučelje koje svi algoritmi moraju nasljediti kako bi imali zajednočko sučelje. IAlgorithm sučelje ima slijedeće metode i svojstva:
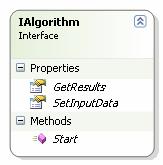
Slika 6.10 Sučelje IAlgorithm
Tablica 6.2 Članovi sučelja IAlgorithm
|
Svojstvo |
Uloga |
|
GetResults |
Rezultat izvođenja algoritma |
|
SetInputData |
Ulazni podaci algoritma |
|
Metoda |
Uloga |
|
Start |
Pokreće izvođenje algoritma |
Generička klasa SimpleGeneticAlgorithmEngine definirana je samo za klase koje nasljeđuju sučelje IGeneticAlgorithm, time se osigurava da sve metode koje poziva klasa SimpleGeneticAlgorithmEngine postoje. Sučelje IGeneticAlgorithm ima slijedeće metode i svojstva:
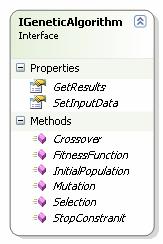
Slika 6.11 Sučelje IGeneticAlgorithm
Tablica 6.3 Članovi sučelja IGeneticAlgorithm
|
Svojstvo |
Uloga |
|
GetResults |
Rezultat izvođenja algoritma |
|
SetInputData |
Ulazni podaci algoritma |
|
Metoda |
Uloga |
|
Crossover |
Operator križanja |
|
FitnessFunction |
Funkcija dobrote |
|
InitialPopulation |
Generira početnu populaciju |
|
Mutation |
Operator mutacije |
|
Selecton |
Selekcija |
|
StopConstraint |
Uvjet zaustavljanja |
- Implementirati grafički prikaz napredovanja algoritama prema rezultatu, npr. napraviti ''wrapper'' oko Microsoft Excel programa koji prosljeđuje podatke Excel-u te Excel na temelju tih podataka napravi graf i onda vrati sustavu. Ili napraviti slično gornjem primjeru ''wrapper'' ok MatLab programa za iscrtavanje grafova.
- Implementirati MPICH2.net sustav koji omogućava paraleno izvođenje poslova, kako bi se mogli implementirati algoritmi koji se izršavaju paralelno. Npr. paralelni genetski algoritmi definirani u [2].
7. ZAKLJUČAK
Evolucijski algoritam primjenjiv je u širokom spektru problema pa je našao svoju primjenu u inženjerstvu, umjetnosti, biologiji, ekonomiji, genetici, robotici, fizici, kemiji te mnogim drugim djelatnostima. Iako postoje mnogi besplatni i komercijalni programi koji omogućuju primjenu evolucijskih algoritama, u mnogim se praktičnim primjenama pokazala potreba modifikacije barem nekog dijela postojećih programa kako bi se algoritam uspješno prilagodio zadatku, optimalno iskorištavajući računalna sredstva koja su na raspolaganju.
Najveća prednost genetskih algoritama svakako je primjenjivost na velik broj različitih vrsta optimizacijskih problema. Uzme li se pri tome jednostavnost implementacije, zatim, da za rješavanje nije potrebno detaljno poznavanje strukture problema, kao i neosjetljivost algoritma na višemodalne prostore rješenja, jasno je da je genetski algoritm jako dobra metoda optimiranja. Kako su genetski algoritmi u osnovi heurističke medote, nije moguće garantirati pronalaženje globalnog optimuma. Genetski algoritam daje samo rješenje koje se nalazi po vrijednosti u blizini globalnog optimuma. Preciznost rješenja se jednostavno može povećati ponavljanjem postupka, primjerice suženim prostorom pretrage.
U ovom radu izgrađen je sustav kojim se objedinjuju problemi i evolucijske metode. Time je omogučena analiza evolucijskih algoritama na jednom mjestu. Glavni cilj sustava je da se na jednostavan način implementiraju problemi i definiraju ulazne i izlazne datoteke. Omogućena je velika fleksibilnost komunikacije sustava s okolinom pomoču ulaznih i izlaznih datoteka. Kako je genetski algoritam u primjeni često prvi korak u pronalaženju optimalnog rezultata sustav omogućuje jednostavnu implementaciju izlaznih datoteka u potrebnom formatu. Sustav je izgrađen modularno što znači da se na jednom definiranom problemu može izvoditi neograničen broj evolucijskih algoritama (odnos problema i algoritma je 1:N). Takvim pristupom omogućeno je da se više vremena provede na stvaranje algoritma kojim se rješava problem. Nadogradnjom sustava dobila bi se i suprotna veza između problema i evolucijskog algoritma, no to nije tema ovog diplomskog rada (time bi odnos problema i evolucijskog algoritma bio N:N). Sustav omogućuje stvaranje, spremanje i učitavanje projekata. Svaki projekt koji se stvori u sebi sadrži cjelinu koja definira problem te cjelinu koja definira algoritam kojim se problem rješava. Time je omogućena prenosivost i ponovno korištenje projekata. Načinjen je instalacijski paket koji je namjenjen krajnjim korisnicima koji koriste sustav za analizu evolucijskih algoritama. Cilj praktičnog rada nije bio izrada genetskog algoritma i testiranje njegovih operatora već napraviti sustav koji će omogućiti testiranja evolucijskih algoritama na raznim problemima.
8. LITERATURA
[1] Golub M., Genetski algoritmi – Prvi dio, 2004. Fakultet elektrotehnike i računarstva. Zavod za elektroniku, mikroelektroniku, računalne i inteligentne sustave. Dostupno na: http://www.zemris.fer.hr/~golub/ga/ga_skripta1.pdf
[2] Golub M., Genetski algoritmi – Drugi dio, 2004. Fakultet elektrotehnike i računarstva. Zavod za elektroniku, mikroelektroniku, računalne i inteligentne sustave. Dostupno na http://www.zemris.fer.hr/~golub/ga/ga_skripta2.pdf
[3] Zvonimir Kunetić, Primjena genetskih algoritama u linearnom programiranju 2007., Dostupno na: http://www.zemris.fer.hr/~golub/ga/
[4] Vedran Lovrečić, Genetski algoritmi u primjeni 2005., Dostupno na: http://www.zemris.fer.hr/~golub/ga/studenti/lovrecic/Genetskialgoritamuprimjeni.htm
[5] Članak ''A Genetic Algorithm for the P-Median Problem''. Dostupno na: http://www.cs.kent.ac.uk/pubs/2001/1417/content.pdf
[6]
Članak ''Solving the Quadratic Assignment
Problems by a Genetic Algorithm with a New Replacement Strategy'', Dostupno na:
www.waset.org/pwaset/v24/v24-59.pdf
[7] Članak ''Dependet – chance integer programming applied to capital budgeting'', Dostupno na: http://www.orsj.or.jp/~archive/pdf/e_mag/Vol.42_2_117.pdf