Kako smo već rekli svaku kocku smo crtali pomoću naredbe:
Možemo vidjeti da je na lijevoj strani naredbe varijabla key_box. Ova varijabla je tipa HC_KEY što predstavlja identifikacijski broj svih objekata u HOOPS 3D grafičkom alatu. Svaki objekt, geometrija ili segment ima svoj identifikacijski broj koji je u stvarnosti broj tipa long. Ovaj broj je potreban za upravljanje objektima HOOPS 3D alatom. Preko njega možemo HOOPS-u zadavati naredbe za pojedine objekte, možemo im mijenjati svojstva, manipulirati njima i dr.
Sama oktalna struktura ima svoje identifikacijske brojeve. Svrha toga je da se različite kocke mogu raspoznavati jedna od druge i da se lakše nađe potrebna kocka. Svaki list kao i svaki čvor, koji je jednom prilikom procesa rafiniranja i sam bio list, imaju svoj jedinstveni identifikacijski broj.
Prilikom prikaza listova strukture svaki prikazani list (kocka) je dobio svoj HC_KEY. Postavlja se pitanje kako sada prilikom manipuliranja prikazom dobiti vezu između prikazanih kocki i onih smještenih u oktalnoj strukturi pomoću kojih je prikaz i napravljen. Obje strukture, i prikazana i stvarna, imaju svoje identifikacijske brojeve, ali to nisu isti brojevi. HOOPS ima mogućnost unošenja korisničkih atributa unutar samog modela. Na taj se način identifikacijski broj elementa strukture može spremiti direktno sa prikazanim objektom. Međutim u drugim alatima takvo što nije moguće te se javlja potreba za dodatnom strukturom podataka koja će služiti samo za ostvarivanje veze između stvarne strukture i njenog prikaza.
Najjednostavniji način ostvarivanja veze između stvarne strukture i njenog prikaza je polje. Stvara se dvostruko polje elemenata gdje se u prvom redu upisuju identifikacijski brojevi elemenata prikaza, a u drugom identifikacijski brojevi elemenata strukture. Nije potrebno sortiranje elemenata jer će pretraga ići od početka prema kraju, element po element. Elementi ne moraju imati neprekinut niz identifikacijskih brojeva što onemogućuje direktan skok na zadani element. Postupak pretrage je moguće ubrzati određenim algoritmima, ali zbog prirode primjene nije ekonomično jer će se struktura nakon svake upotrebe uništavati i ponovo graditi.
Svaki put kad napravimo selekciju i nadogradimo stablo, tj. proširimo određenu granu za jednu razinu, unutar polja se gubi jedan element jer je taj list postao čvor i dobivamo osam novih elemenata. Dakle, moramo polje proširiti za sedam novih mjesta, obrisati selektirani element te ga zamijeniti novim i dodati još sedam ostalih novih listova.
Proširivanje polja znači njegovo uništenje i izgradnju novog, većeg, polja na drugoj memorijskoj lokaciji te kopiranje elemenata iz starog polja u novo. Stvaranje cijele jedne nove strukture zbog samo jednog elementa je izrazito neekonomično.
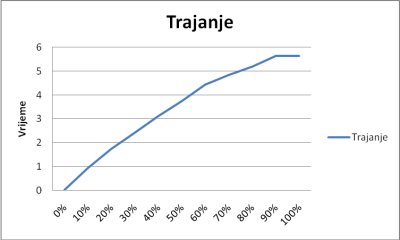
Na grafu se može vidjeti odnos broja elemenata koje je potrebno zamijeniti novim i trajanja postupka stvaranja nove strukture. Možemo primijetiti da se ekonomičnost postupka mijenja u ovisnosti o broju elemenata. Kako taj broj raste tako imamo sve više elemenata koje moramo usporediti prilikom kopiranja iz starog polja u novo.
Nešto složeniji način ostvarivanja veze je lista. Stvaraju se povezani objekti koji unutar sebe čuvaju par identifikacijskih brojeva elemenata prikaza i strukture te pokazivač na sljedeći objekt. Prilikom stvaranja liste, elementi se redom ubacuju u listu. Svaki novi element se stavlja na kraj liste. Prilikom brisanja već postojećeg elementa pretraga ide od početka liste prema kraju, kao i kod polja no nije potrebno stvarati posve novu strukturu. Traženi element se izbacuje iz strukture i stvara se veza između dva okolna elementa.
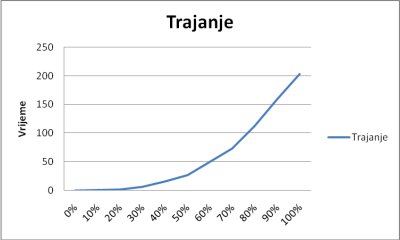
Prema grafu vidimo da trajanje brisanja starih i unošenja novih elemenata eksponencijalno raste sa brojem spomenutih elemenata. Razlog toga je što pretraga za svakim elementom kojeg želimo obrisati kreće od početka liste kao i za unošenje svakog pojedinog elementa. Kod polja smo nove elemente unosili na kraj, ali nismo morali proći kroz čitavo polje nego smo direktno adresirali željene adrese. Kod liste to nije moguće.
Kod sortirane liste imamo sličan slučaj kao kod nesortirane. Prilikom unošenja elemenata u listu moramo krenuti od početka liste i kretati se prema njenom repu, no u ovom slučaju ne moramo nužno ići do kraja liste. Nove elemente ne stavljamo na kraj liste kao kod nesortirane već ih stavljamo ispred prvog elementa veće vrijednosti. Na taj način štedimo nešto vremena prilikom unošenja elemenata. Kod brisanja elemenata nema razlike. Još uvijek moramo pretraživati listu. Činjenica da je lista sortirana nam ne pomaže mnogo jer nam elementi koje tražimo neće dolaziti redom. Može se dogoditi da proces brisanja u nekim situacijama teče brže kod nesortirane liste.
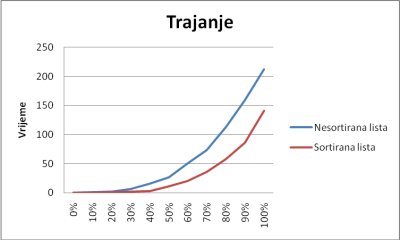
Po grafu vidimo da je trajanje kod sortirane liste isto kao i kod nesortirane. Vrijeme i ovdje raste eksponencijalno sa porastom broja elemenata. Jedina razlika je da su rezultati kod sortirane liste nešto bolji od onih od nesortirane.
Nešto složeniji, ali ujedno i bolji način spremanja podataka jest unutar binarnog stabla. Elementi se prilikom unosa automatski sortiraju po veličini. Osnovno pravilo je da manji elementi od trenutnog idu u „lijevu“ granu dok veći ili jednaki elementi idu u „desnu“ granu. Najbolja varijanta popune stabla jest potpuna popuna stabla gdje se dobiva ista dubina stabla na svim granama. Najlošija je kad za unos dobijemo već sortirane elemente jer u tom slučaju konačno stablo izgleda poput liste. Dubina stabla je u tom slučaju jednaka broju elemenata u stablu.
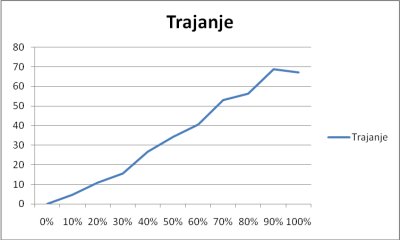
Unos i pretraživanje elemenata su optimalni koliko je i stablo optimalno razgranato, tj. koliko blizu potpunom stablu je korišteno stablo. Najlošiji slučaj je jednak dubini stabla. Pri brisanju elemenata iz stabla se koriste određeni algoritmi za ubrzanje rada. Najjednostavniji modeli brisanja su kad se brišu listovi ili čvorovi sa samo jednim djetetom. U slučaju brisanja čvora sa oba djeteta koristi se poseban postupak preraspodjele elemenata stabla:
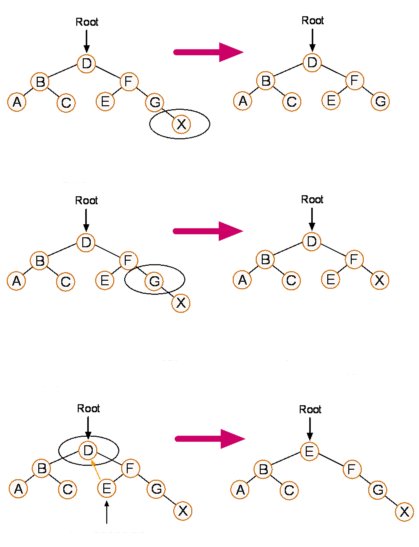
Kako vidimo na slici brisanje lista je najjednostavniji slučaj. Obriše se objekt koji predstavlja list, a pokazivač u čvoru roditelju se postavlja na „null“ vrijednost. Slučaj brisanja čvora s jednim djetetom je nešto složeniji i svodi se na to da se nakon brisanja objekta pokazivač roditelja premjesti na dijete obrisanog čvora. Treći slučaj je dosta složeniji. Za početak moramo pronaći „čvor nasljednika“. On je zadnji lijevi čvor u desnoj grani.
Test usporedbe je rađen na računalu AMD Sempron(tm) 2800+. Svaki test je kretao od već izgrađene strukture elemenata. Test je ponavljan veći broj puta sa različitim inicijalnim veličinama struktura. Mjerenje pri istoj veličini je također ponavljano oko 1000 puta (ovisno o veličini strukture) radi preciznijih rezultata.
Test se sastojao od toga da se usporede brzine brisanja starih i spremanja novih elemenata u strukture podataka. Test je ponavljan za različit broj podataka koji se mijenjaju u jednom pokušaju. Izmjereno vrijeme služi samo za usporedbu efikasnosti mjerenih struktura.
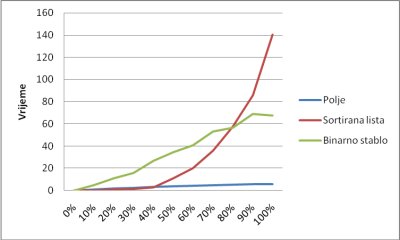
Pri usporedbi efikasnosti struktura podataka sa 1000 spremljenih elemenata polje je dalo najbolje rezultate (slika 5.6). Sortirana lista je davala malo bolje rezultate pri mijenjanju do 40% elemenata odjednom, ali nakon toga joj efikasnost veoma brzo opada. Binarno stablo je dalo najlošije rezultate iako se može primijetiti da mu efikasnost opada daleko sporije od liste te da daje bolje rezultate pri više od 80% mijenjanih elemenata. Ako uzmemo u obzir da će se rijetko mijenjati više od 20% elemenata odjednom možemo zaključiti da će polje kao najjednostavnija struktura davati posve zadovoljavajuće rezultate.
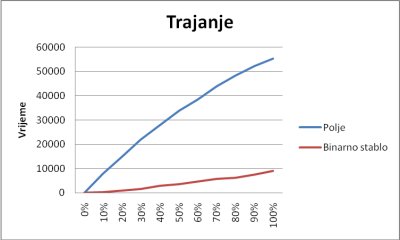
Pri veličini strukture od 100.000 elemenata se situacija mijenja. Možemo primijetiti da u ovom slučaju binarno stablo od početka daje daleko bolje rezultate. Polje više nije dominantna struktura.
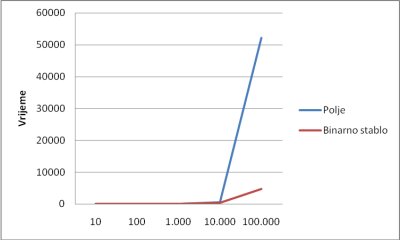
Polje je struktura koju možemo koristiti pri manjem broju elemenata. Tada se njegove mane ne očituju u tolikoj mjeri da bi postale značajne. Nakon određene granice polje postaje preneefikasno za rad. Binarno stablo je dobra i efikasna struktura za upravljanje podacima, brzo pronalaženje potrebnih elemenata i njihovu manipulaciju. Prednosti binarnog stabla se ne očituju pri malom broju elemenata, ali postaju značajne pri većem.
key_box = HUtility::InsertBox( max, min );
Možemo vidjeti da je na lijevoj strani naredbe varijabla key_box. Ova varijabla je tipa HC_KEY što predstavlja identifikacijski broj svih objekata u HOOPS 3D grafičkom alatu. Svaki objekt, geometrija ili segment ima svoj identifikacijski broj koji je u stvarnosti broj tipa long. Ovaj broj je potreban za upravljanje objektima HOOPS 3D alatom. Preko njega možemo HOOPS-u zadavati naredbe za pojedine objekte, možemo im mijenjati svojstva, manipulirati njima i dr.
Sama oktalna struktura ima svoje identifikacijske brojeve. Svrha toga je da se različite kocke mogu raspoznavati jedna od druge i da se lakše nađe potrebna kocka. Svaki list kao i svaki čvor, koji je jednom prilikom procesa rafiniranja i sam bio list, imaju svoj jedinstveni identifikacijski broj.
Prilikom prikaza listova strukture svaki prikazani list (kocka) je dobio svoj HC_KEY. Postavlja se pitanje kako sada prilikom manipuliranja prikazom dobiti vezu između prikazanih kocki i onih smještenih u oktalnoj strukturi pomoću kojih je prikaz i napravljen. Obje strukture, i prikazana i stvarna, imaju svoje identifikacijske brojeve, ali to nisu isti brojevi. HOOPS ima mogućnost unošenja korisničkih atributa unutar samog modela. Na taj se način identifikacijski broj elementa strukture može spremiti direktno sa prikazanim objektom. Međutim u drugim alatima takvo što nije moguće te se javlja potreba za dodatnom strukturom podataka koja će služiti samo za ostvarivanje veze između stvarne strukture i njenog prikaza.
Polje
Najjednostavniji način ostvarivanja veze između stvarne strukture i njenog prikaza je polje. Stvara se dvostruko polje elemenata gdje se u prvom redu upisuju identifikacijski brojevi elemenata prikaza, a u drugom identifikacijski brojevi elemenata strukture. Nije potrebno sortiranje elemenata jer će pretraga ići od početka prema kraju, element po element. Elementi ne moraju imati neprekinut niz identifikacijskih brojeva što onemogućuje direktan skok na zadani element. Postupak pretrage je moguće ubrzati određenim algoritmima, ali zbog prirode primjene nije ekonomično jer će se struktura nakon svake upotrebe uništavati i ponovo graditi.
Svaki put kad napravimo selekciju i nadogradimo stablo, tj. proširimo određenu granu za jednu razinu, unutar polja se gubi jedan element jer je taj list postao čvor i dobivamo osam novih elemenata. Dakle, moramo polje proširiti za sedam novih mjesta, obrisati selektirani element te ga zamijeniti novim i dodati još sedam ostalih novih listova.
Proširivanje polja znači njegovo uništenje i izgradnju novog, većeg, polja na drugoj memorijskoj lokaciji te kopiranje elemenata iz starog polja u novo. Stvaranje cijele jedne nove strukture zbog samo jednog elementa je izrazito neekonomično.
Na grafu se može vidjeti odnos broja elemenata koje je potrebno zamijeniti novim i trajanja postupka stvaranja nove strukture. Možemo primijetiti da se ekonomičnost postupka mijenja u ovisnosti o broju elemenata. Kako taj broj raste tako imamo sve više elemenata koje moramo usporediti prilikom kopiranja iz starog polja u novo.
Lista
Nešto složeniji način ostvarivanja veze je lista. Stvaraju se povezani objekti koji unutar sebe čuvaju par identifikacijskih brojeva elemenata prikaza i strukture te pokazivač na sljedeći objekt. Prilikom stvaranja liste, elementi se redom ubacuju u listu. Svaki novi element se stavlja na kraj liste. Prilikom brisanja već postojećeg elementa pretraga ide od početka liste prema kraju, kao i kod polja no nije potrebno stvarati posve novu strukturu. Traženi element se izbacuje iz strukture i stvara se veza između dva okolna elementa.
Prema grafu vidimo da trajanje brisanja starih i unošenja novih elemenata eksponencijalno raste sa brojem spomenutih elemenata. Razlog toga je što pretraga za svakim elementom kojeg želimo obrisati kreće od početka liste kao i za unošenje svakog pojedinog elementa. Kod polja smo nove elemente unosili na kraj, ali nismo morali proći kroz čitavo polje nego smo direktno adresirali željene adrese. Kod liste to nije moguće.
Sortirana lista
Kod sortirane liste imamo sličan slučaj kao kod nesortirane. Prilikom unošenja elemenata u listu moramo krenuti od početka liste i kretati se prema njenom repu, no u ovom slučaju ne moramo nužno ići do kraja liste. Nove elemente ne stavljamo na kraj liste kao kod nesortirane već ih stavljamo ispred prvog elementa veće vrijednosti. Na taj način štedimo nešto vremena prilikom unošenja elemenata. Kod brisanja elemenata nema razlike. Još uvijek moramo pretraživati listu. Činjenica da je lista sortirana nam ne pomaže mnogo jer nam elementi koje tražimo neće dolaziti redom. Može se dogoditi da proces brisanja u nekim situacijama teče brže kod nesortirane liste.
Po grafu vidimo da je trajanje kod sortirane liste isto kao i kod nesortirane. Vrijeme i ovdje raste eksponencijalno sa porastom broja elemenata. Jedina razlika je da su rezultati kod sortirane liste nešto bolji od onih od nesortirane.
Binarno stablo
Nešto složeniji, ali ujedno i bolji način spremanja podataka jest unutar binarnog stabla. Elementi se prilikom unosa automatski sortiraju po veličini. Osnovno pravilo je da manji elementi od trenutnog idu u „lijevu“ granu dok veći ili jednaki elementi idu u „desnu“ granu. Najbolja varijanta popune stabla jest potpuna popuna stabla gdje se dobiva ista dubina stabla na svim granama. Najlošija je kad za unos dobijemo već sortirane elemente jer u tom slučaju konačno stablo izgleda poput liste. Dubina stabla je u tom slučaju jednaka broju elemenata u stablu.
Unos i pretraživanje elemenata su optimalni koliko je i stablo optimalno razgranato, tj. koliko blizu potpunom stablu je korišteno stablo. Najlošiji slučaj je jednak dubini stabla. Pri brisanju elemenata iz stabla se koriste određeni algoritmi za ubrzanje rada. Najjednostavniji modeli brisanja su kad se brišu listovi ili čvorovi sa samo jednim djetetom. U slučaju brisanja čvora sa oba djeteta koristi se poseban postupak preraspodjele elemenata stabla:
Kako vidimo na slici brisanje lista je najjednostavniji slučaj. Obriše se objekt koji predstavlja list, a pokazivač u čvoru roditelju se postavlja na „null“ vrijednost. Slučaj brisanja čvora s jednim djetetom je nešto složeniji i svodi se na to da se nakon brisanja objekta pokazivač roditelja premjesti na dijete obrisanog čvora. Treći slučaj je dosta složeniji. Za početak moramo pronaći „čvor nasljednika“. On je zadnji lijevi čvor u desnoj grani.
Usporedba efikasnosti navedenih struktura podataka
Test usporedbe je rađen na računalu AMD Sempron(tm) 2800+. Svaki test je kretao od već izgrađene strukture elemenata. Test je ponavljan veći broj puta sa različitim inicijalnim veličinama struktura. Mjerenje pri istoj veličini je također ponavljano oko 1000 puta (ovisno o veličini strukture) radi preciznijih rezultata.
Test se sastojao od toga da se usporede brzine brisanja starih i spremanja novih elemenata u strukture podataka. Test je ponavljan za različit broj podataka koji se mijenjaju u jednom pokušaju. Izmjereno vrijeme služi samo za usporedbu efikasnosti mjerenih struktura.
Pri usporedbi efikasnosti struktura podataka sa 1000 spremljenih elemenata polje je dalo najbolje rezultate (slika 5.6). Sortirana lista je davala malo bolje rezultate pri mijenjanju do 40% elemenata odjednom, ali nakon toga joj efikasnost veoma brzo opada. Binarno stablo je dalo najlošije rezultate iako se može primijetiti da mu efikasnost opada daleko sporije od liste te da daje bolje rezultate pri više od 80% mijenjanih elemenata. Ako uzmemo u obzir da će se rijetko mijenjati više od 20% elemenata odjednom možemo zaključiti da će polje kao najjednostavnija struktura davati posve zadovoljavajuće rezultate.
Pri veličini strukture od 100.000 elemenata se situacija mijenja. Možemo primijetiti da u ovom slučaju binarno stablo od početka daje daleko bolje rezultate. Polje više nije dominantna struktura.
Polje je struktura koju možemo koristiti pri manjem broju elemenata. Tada se njegove mane ne očituju u tolikoj mjeri da bi postale značajne. Nakon određene granice polje postaje preneefikasno za rad. Binarno stablo je dobra i efikasna struktura za upravljanje podacima, brzo pronalaženje potrebnih elemenata i njihovu manipulaciju. Prednosti binarnog stabla se ne očituju pri malom broju elemenata, ali postaju značajne pri većem.