KITTI semantic segmentation groundtruth
This datasets contains groundtruth semantic segmentations for 445 hand-picked images from the KITTI dataset. We start from 146 images annotated by German Ros from UAB Barcelona, improve their annotation accuracy and contribute another 299 images. The annotations feature high quality pixel-level polygonal approximations into 11 semantic classes: building, vegetation, sky, road, fence, pole, sidewalk, sign, car, pedestrian, bicyclist. The dataset additionally contains high quality stereoscopic reconstructions as illustrated below.













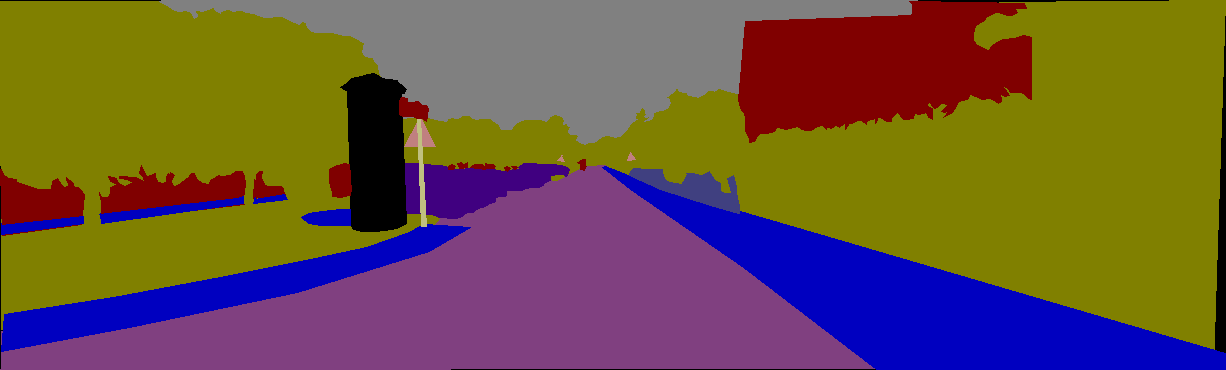




Notation
The images are named as SS_NNNNNN.png, where SS denotes the sequence (00 till 10) while NNNNNN stands for the original image index. The test directory contains 46 images from sequence 07. The train directory contains 399 images including 100 images from the sequence 00 and 299 images from the rest of the dataset (all sequences except 00 and 07). Images from sequences 00 and 07 are improved versions of the corresponding images from the original UAB dataset, while the remainining 299 images were annotated by us from scratch. The total distribution of labeled images over 11 sequences is shown in the table below.
| Sequence | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 |
| # images | 100 | 17 | 33 | 10 | 3 | 60 | 7 | 46 | 97 | 53 | 19 |
License and citing
The dataset may be freely used for academic purposes. If you find our dataset useful in your research, please cite the following paper:
Ivan Krešo, Denis Čaušević Josip Krapac and Siniša Šegvić. Convolutional scale invariance for semantic segmentation. GCPR 2016 (PDF).
Credits
Images were annotated by Ivan Borko, Matija Folnović, Petra Marče, Nikola Munđer and Dino Pačandi. The annotation tool was designed by Ivan Fabijanić.
Download
The dataset can be downloaded from Mendeley. Please unpack the archive and follow the instructions in the README file.
Annotation tool
The tool used to annotate the dataset is available here.