Ladder-style DenseNets for semantic segmentation
-
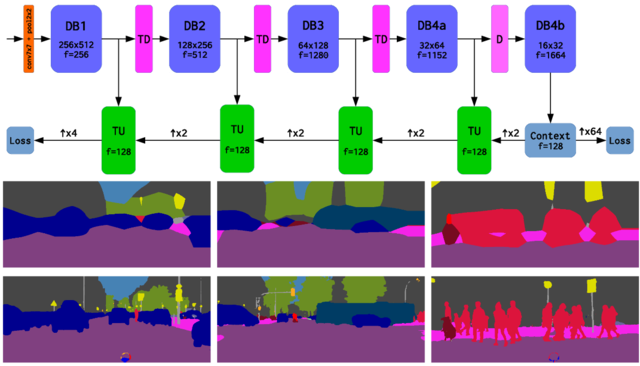
we augment a modified DenseNet classifier
with ladder-style lateral connections
-
the proposed architecture yields
competitive accuracy and speed:
we achieve 74.3 mIoU on Cityscapes
while being able to perform a forward pass
on 2 MPixel images at 7.5 Hz (March 2017)
-
we show our position on the graph
reproduced from a contemporaneous
paper:
ICNet for Real-Time Semantic Segmentation
on High-Resolution Images;
Zhao et al, arXiv:1704.08545.
-
paper:
kreso17cvrsuad
|
|
|
Convolutional scale-invariance
-
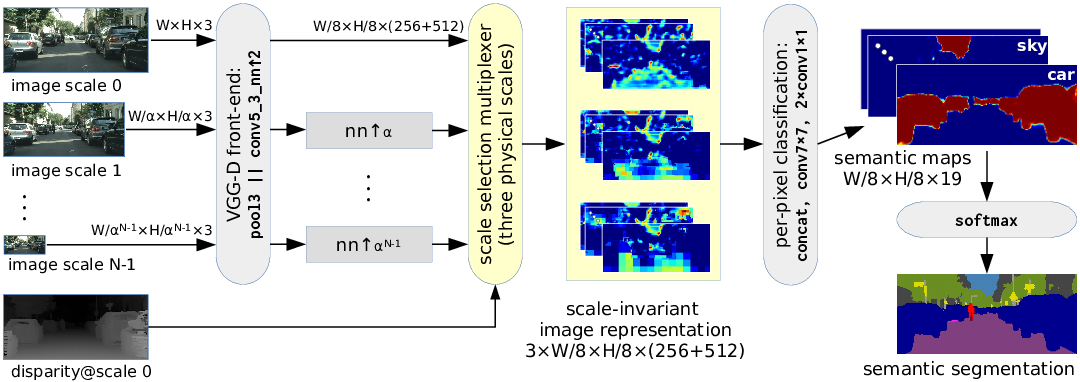
we aid recognition
by means of reconstruction
-
the main idea: use the reconstructed depth
as a guide to disentagle appearance
from the scale
-
this releaves the classifier from
the necessity to recognize objects
at different scales and leads to
efficient exploitation of the training data
-
we have integrated the proposed technique
into an end-to-end trained
fully convolutional model
-
we achieve 66.3 mIoU on Cityscapes test
despite training on reduced resolution
(April 2016)
-
paper:
kreso16gcpr
|



|
|
Learning the calibration bias
-
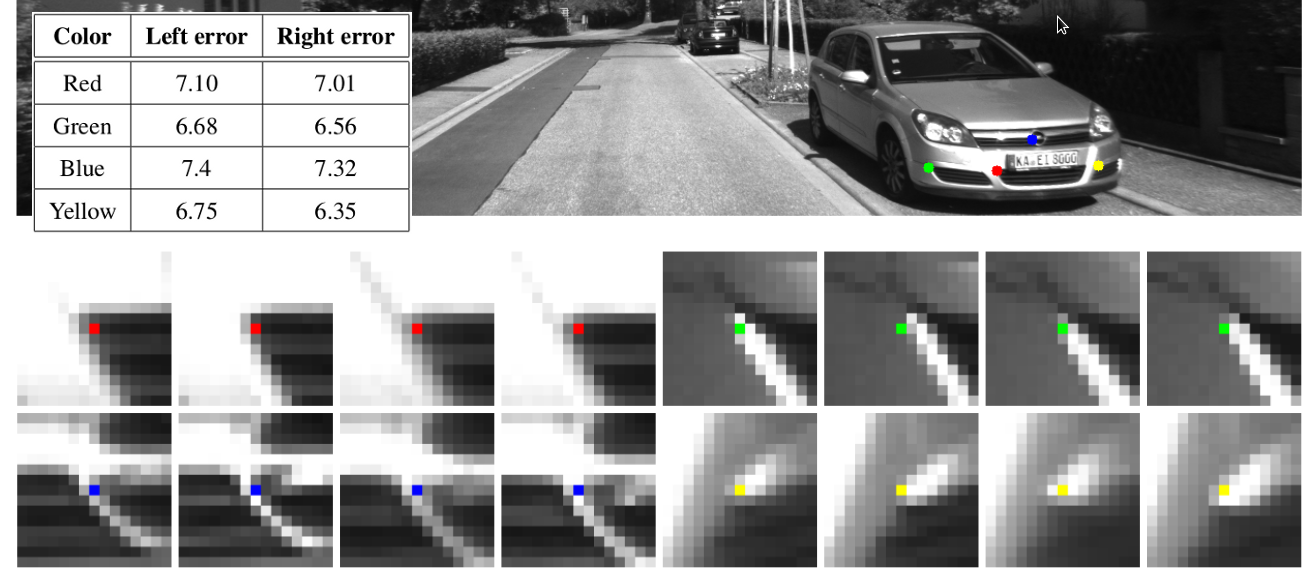
we notice that
near-perfect correspondences on the KITTI dataset
result in high reprojection errors
under ground-truth motion
-
we hypothesize that this irregularity
is due to insufficient capacity
of the employed camera calibration model
-
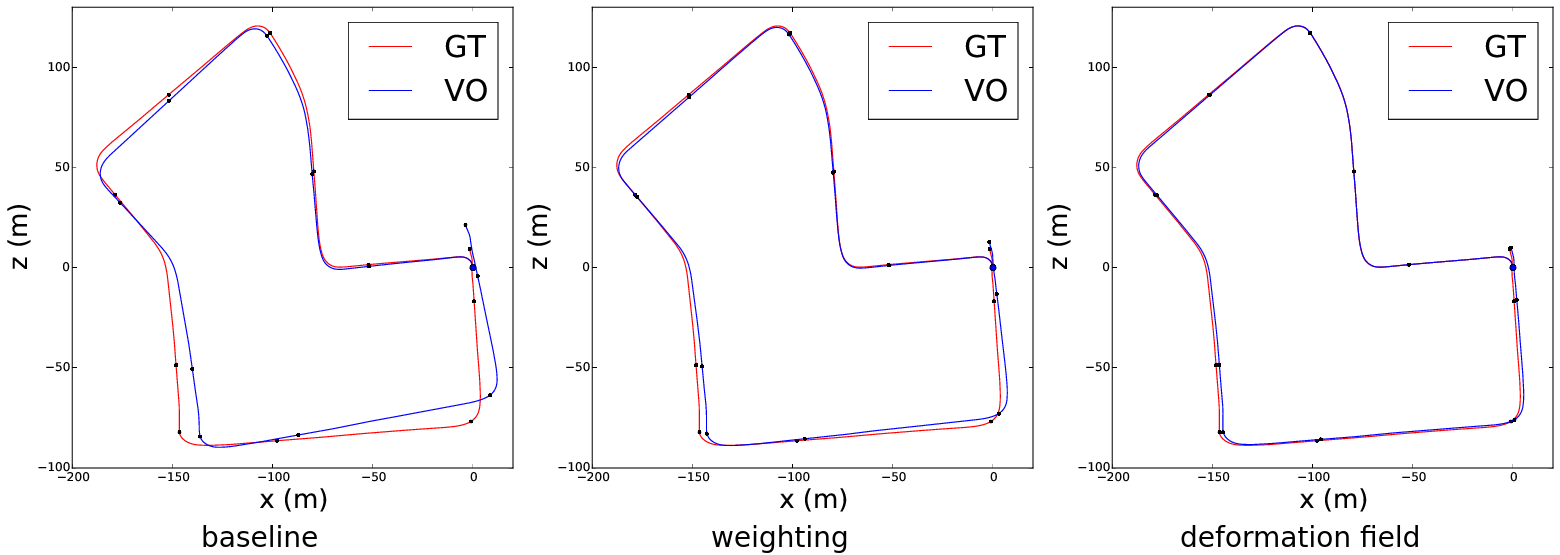
we correct the calibration bias
by exploiting the groundtruth motion;
this improves egomotion accuracy
on sequences which were not seen
during training
-
paper:
kreso15visapp
|
|
|
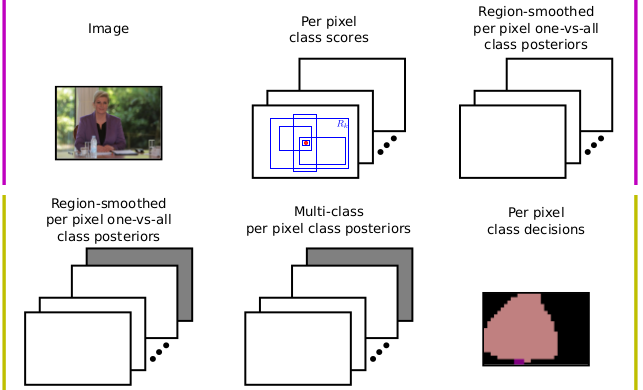
Weakly supervised semantic segmentation
-
we embed convolutional features
into Fisher space and train
one versus all classification models
on aggregated representations
-
we apply the classifiers to pixel embeddings
and smooth the scores by averaging
over all encompassing rectangular regions
-
we recover the background scores by noisy or and
achieve 38% mIoU on PASCAL VOC 2012
(March 2016)
-
paper:
gcpr16krapac;
|

|
|
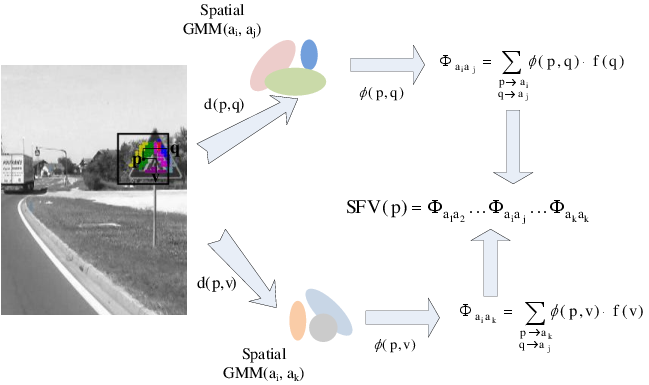
Weakly supervised spatial layout
-
we improve our previous
weakly supervised localization approach
by introducing spatial layout cues and
accounting for non-linear normalizations
-
we improve the execution speed
by a first-order approximation
of the classification score
of a normalized Fisher vector representation
-
the obtained performance is 81% AP, 11% pMiss
(vs 88% AP, 5% pMiss s.s. HOG+SVM)
-
paper:
zadrija15gcpr;
dataset:
TS2010a
|
|
|
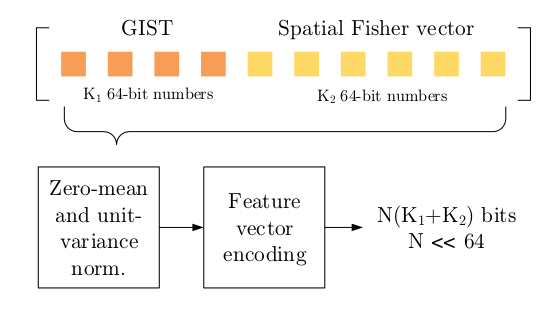
Classification on a representation budget
-
we adress the problem of designing an image representation
which would allow best classification
for a given representation budget
-
several solutions were tried (deep autoencoders, Fisher vectors, GIST),
best results are obtained by a custom encoding of a concatenation
of GIST with a spatial Fisher vector
-
paper:
sikiric15vprice;
dataset:
unizg-fer-fm2
|
|
|
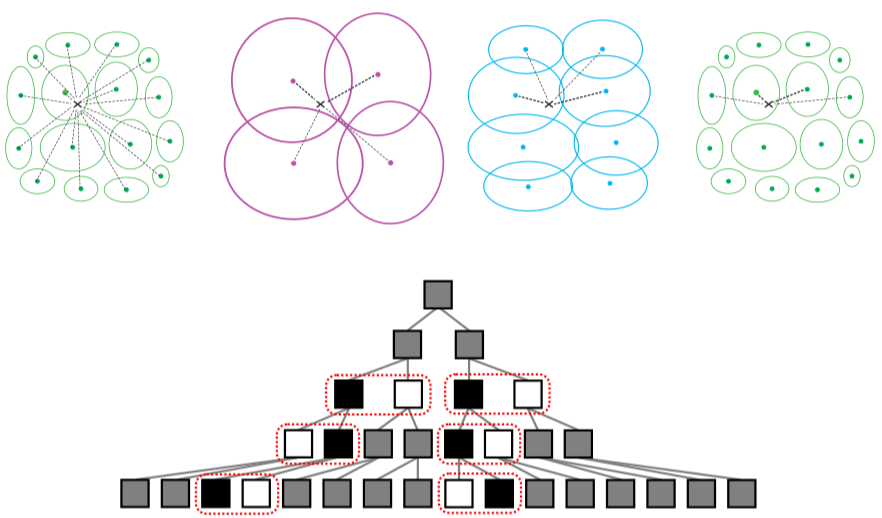
Fast approximate soft assign
-
we address the problem of speeding up the soft-assign
of an unseen pattern to the components of a large GMM
-
the proposed approach uses recursive agglomerative
clustering of the GMM components and allows to tune
the trade-off between the speed and the accuracy
-
the results on a fine-grained dataset
suggest that the speed can be improved
by an order of magnitude without loss
of classification performance
-
paper:
krapac15gcpr;
|
|
|
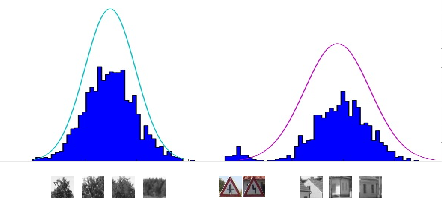
Weakly supervised localization
-
we show that traffic signs can be successfully localized
in real images by a classification model
trained on entire images
-
we exploit a sparse regularizer
to learn a classification model which selects
the relevant components of the
Fisher vector image representation
-
the results are close to a heavy-weight
strongly supervised approach (HOG+SVM):
77% vs 88% AP, 16% vs 5% pMiss
-
paper:
gcpr15;
dataset:
TS2010a;
|
|



