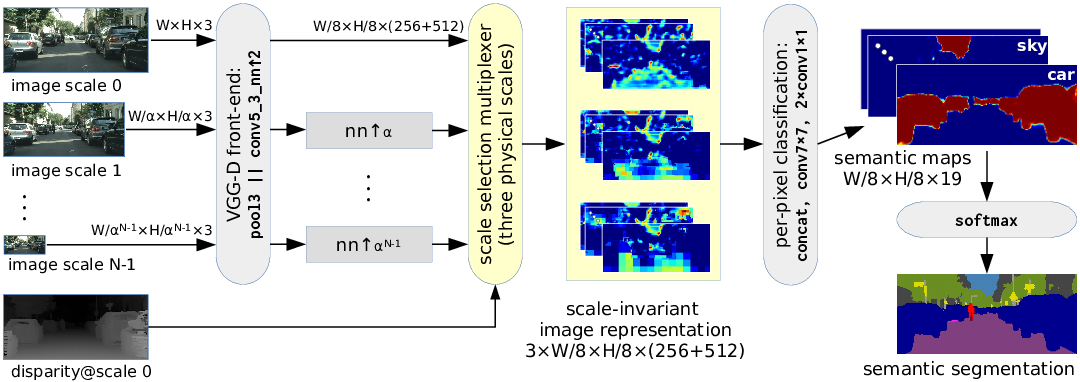
Scale invariant semantic segmentation
We present a convolutional architecture which leverages stereoscopic depth to produce a scale-invariant representation of the scene, in which appearance is decoupled from scale. This precludes the necessity to recognize objects at all possible scales and allows for an efficient use of the classifier capacity and the training data. This trait is especially important for navigation datasets which contain objects at a great variety of scales and do not exhibit the photographer bias. Experiments on KITTI and Cityscapes show a clear advantage with respect to a multi-scale approach with a fixed selection of scales. Results on Cityscapes are very close to the state-of-the-art, despite the fact that we have trained our network on a significantly reduced resolution.
Results on Cityscapes
Unlike recent submissions,
we train our approach on a reduced resolution of
1504x672 pixels in order to meet memory requirements.
After applying a dense pretrained CRF we achieve 66.3% mIoU.
Experiments on full resolution shall be presented soon.



Download
The source code for the scale invariant convolutional architecture is available for download from github.
Due to pooling, our network outputs the semantic map of the given input image at reduced resolution (16x16 times). In order to achieve best results we recommend smoothing the semantic maps with a pixel-level CRF. Our GCPR results were postprocessed by a CRF with Gaussian potentials as proposed and implemented by Krähenbuhl and Koltun.
License and citing
The code may be freely used for academic purposes. If you find the code useful in your research, please cite the following paper:
Ivan Krešo, Denis Čaušević Josip Krapac and Siniša Šegvić. Convolutional scale invariance for semantic segmentation. GCPR 2016 (PDF).
Dataset
During this research we semantically annotated 300 images from the KITTI dataset and improved the consistency of the 146 images originally annotated by German Ros. The dataset is available here.
Annotation tool
The tool which we used to annotate the dataset is available here.